







在当今大模型快速发展的生成式AI时代,企业内部对于模型即服务(MaaS)的需求日益增长。
很多公司希望建立一个自主可控的MaaS中台,通过统一兼容主流大模型推理接口的HTTP标准,为业务部门提供多种模型的统一访问能力。
多样化的模型选择
客户希望在MaaS中台上集成多种模型,既包括市场上成熟的SaaS化模型,如Amazon Nova、Claude Sonnet 3.7等,也包括自主部署的DeepSeek-R1蒸馏版模型。
这种多样化的模型选择,能够满足不同业务场景下的需求,为企业带来更大的灵活性和创新空间。
高性能硬件支持
为了确保模型的高效运行,有的客户配备了A100 8卡高端服务器。这些服务器用于部署基于开源自建DeepSeek-R1蒸馏版本模型的不同规格,比如32B和1.5B,能够满足从高精度到快速响应的各种需求。
提升资源利用率
客户希望通过MaaS中台,最大限度地提升推理服务器的资源利用率,以应对企业内部不同规模的流量需求。
为了实现这一目标,需要对后端部署的不同版本R1蒸馏模型提供细粒度模型副本级别的弹性扩缩功能。这意味着系统能够根据实际需求,动态调整模型的副本数量,从而在保证性能的同时,有效降低资源浪费。
整体架构
根据以上各类需求,推荐采用Amazon SageMaker Inference Component(下文简称Amazon SageMaker IC),结合开源LiteLLM的部署方案,具体如下。
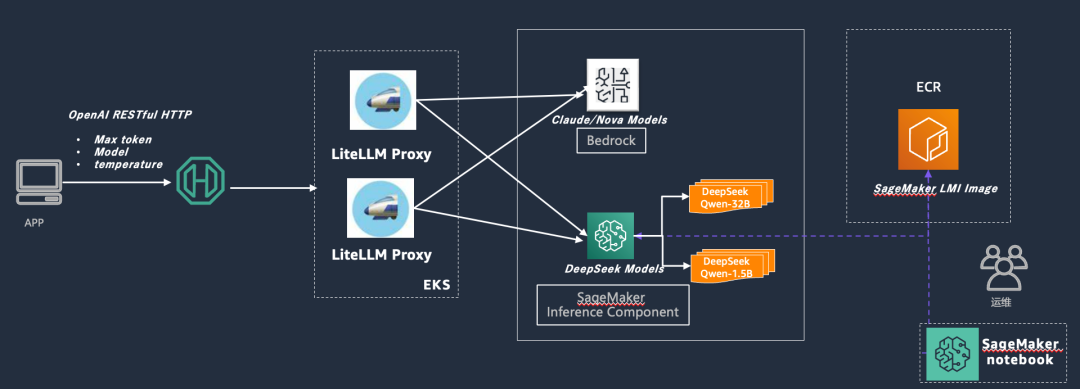
Amazon SageMaker Inference Component:
https://aws.amazon.com/blogs/aws/amazon-sagemaker-adds-new-inference-capabilities-to-help-reduce-foundation-model-deployment-costs-and-latency/
LiteLLM:
https://github.com/BerriAI/litellm
主要组件
1.OpenAPI RESTful HTTP:客户端与MaaS中台之间的接口,通过OpenAPI标准,确保了接口的通用性和兼容性。客户可以通过这个接口发送请求,获取模型的响应。
2.Max token与Model temperature:参数用于控制模型的输出,对后端不同的模型屏蔽api的差异性。
3.LiteLLM Proxy:作为中间层,LiteLLM Proxy负责处理来自客户端的请求,并将其转发到相应的模型服务。它支持多种模型,包括Amazon Nova Models、Claude Models和自建的DeepSeek Models。
4.Amazon EKS:用来管理和部署容器化应用的服务,它提供了高可用性和可扩展性,确保了模型服务的稳定运行。
5.Amazon SageMaker IC:用来部署和管理模型的核心组件。它支持自建托管多种LLM的推理服务,包括DeepSeek的不同版本(如32B和5B),以及诸如HuggingFace等更多长尾的开源模型。
6.Amazon ECR:用来存储和管理容器镜像的服务,它确保了模型部署的快速和可靠。
7.Amazon SageMaker LMI Image:用来构建和部署模型的基础镜像,它包含了所有必要的依赖和配置,确保了模型的高效运行,且提供了业界领先的推理框架。客户可通过开箱即用的方式进行部署,而不需要自己再进行构建和配置。
Amazon EKS:
https://aws.amazon.com/eks/
Amazon ECR:
https://aws.amazon.com/ecr/
工作流程
1.请求发送:客户通过OpenAPI RESTful HTTP接口发送请求,包含Max token和Model temperature参数。
2.请求处理:LiteLLM Proxy接收请求,并根据请求内容将其转发到相应的模型服务。
3.模型响应:模型服务(如Amazon Bedrock或DeepSeek)处理请求,并生成响应。
4.响应返回:LiteLLM Proxy将模型的响应返回给客户端。
下文将详细描述该方案的主要组件的部署步骤和方法。
Amazon SageMaker
Inference Component部署
Amazon SageMaker IC是一项新推出的功能,建立在Amazon SageMaker实时推理端点(Amazon SageMaker端点)功能的基础上。
使用定义端点的实例类型和初始实例计数的端点配置,来创建Amazon SageMaker推理服务后,在每个Inference Component组件中,可以指定要分配给模型每个副本的加速芯片数量、CPU数量、显存量等,以及要部署的LLM、推理的容器映像和模型副本数量,从而允许客户更精细地控制多个模型的部署和资源分配。
Amazon SageMaker IC具体架构如下图所示。

详细信息可参阅文末附录“Amazon SageMaker IC简介”,此处主要介绍使用Amazon SageMaker IC来部署多个LLM的方法。
创建Amazon SageMaker端点
首先,您需要创建一个Amazon SageMaker端点配置,该配置包含了实例类型和初始实例计数,代码示例如下。
import boto3import sagemaker
role = sagemaker.get_execution_role()sm_client = boto3.client(service_name="sagemaker")endpoint_config_name="Sagemaker-inference-componet3"endpoint_name = "Sagemaker-inference-componet-mme3"
!aws sagemaker delete-endpoint-config --endpoint-config-name Sagemaker-inference-componet3
sm_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ExecutionRoleArn=role, ProductionVariants=[{ "VariantName": "AllTraffic", "InstanceType": "ml.g5.48xlarge", "InitialInstanceCount": 1, "RoutingConfig": { "RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS" }, }])
sm_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name,)左右滑动查看完整示意
配置Amazon SageMaker IC推理组件
Amazon SageMaker IC推理组件允许客户指定要分配给不同的模型每个副本的加速器数量和内存量,以及模型对象、容器映像和要部署的模型副本数量,从而方便实施多个模型的资源隔离和分配。
以这一场景为例:客户要同时部署DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Qwen-1.5B两种模型。
在一个8卡(Nvidia A10)的G5服务器上(ml.g5.48xlarge),可以将32B的模型部署在4张GPU卡上并行推理,副本为1;将1.5B的模型部署在2张GPU卡上,副本为2,具体如下。
首先需要创建Amazon SageMaker端点推理端点,作为Amazon SageMaker不同IC的承载服务器。
import sagemakerfrom sagemaker import Model, image_uris, serializers, deserializersfrom sagemaker import get_execution_rolefrom sagemaker.pytorch import PyTorchModelimport time
hf_model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"# 获取 lim 推理容器image_uri = "763104351884.dkr.ecr.us-west-2.amazonaws.com/djl-inference:0.31.0-lmi13.0.0-cu124"print(f"Image going to be used is ---- > {image_uri}")
model_name= "deepseek-r1-distill-qwen-32b-"+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())endpoint_name = "Sagemaker-inference-componet-mme3"左右滑动查看完整示意
其次使用Amazon SageMaker LMI vllm推理镜像,因此需要准备vllm推理镜像的配置文件(server.properties)以及相关的vllm版本依赖(requiremnts.txt)。
serving.properties配置如下所示。
engine=Pythonoption.trust_remote_code=Trueoption.tensor_parallel_degree=4option.gpu_memory_utilization=.87option.max_model_len=10240option.model_id=deepseek-ai/DeepSeek-R1-Distill-Qwen-32Boption.max_rolling_batch_size=2option.rolling_batch=vllm左右滑动查看完整示意
requirements.txt文件如下所示(此处指定vllm为0.7.0版本)。
vllm==0.7.0将server.properties和requiremnts.txt配置文件打包,并上传至Amazon S3路径。
mkdir mymodelmv serving.properties mymodel/mv requirements.txt mymodel/tar czvf mymodel.tar.gz mymodel/rm -rf mymodel
s3_code_prefix = "large-model-lmi/code"bucket = sess.default_bucket() # bucket to host artifactscode_artifact = sess.upload_data("mymodel.tar.gz", bucket, s3_code_prefix)左右滑动查看完整示意
至此Amazon SageMaker LMI vllm镜像所需配置已经准备好,即可开始创建model和Amazon SageMaker IC,具体如下。
DeepSeek-R1-Distill-Qwen-32B模型部署。
container_config = { 'Image': image_uri, 'ModelDataUrl': source_data, 'Environment': vllm_config}
response = sm_client.create_model( ModelName=model_name, ExecutionRoleArn=role, PrimaryContainer=container_config)print(f"Model created: {response['ModelArn']}")
sm_client.create_inference_component( InferenceComponentName="IC-deepseek-r1-distill-qwen-32b-"+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime()), EndpointName=endpoint_name, VariantName="AllTraffic", Specification={ "ModelName": model_name, "ComputeResourceRequirements": { "NumberOfAcceleratorDevicesRequired": 4, "MinMemoryRequiredInMb": 80096 } }, RuntimeConfig={"CopyCount": 1},)左右滑动查看完整示意
DeepSeek-R1-Distill-Qwen-1.5B模型部署。
import sagemakerfrom sagemaker import Model, image_uris, serializers, deserializersfrom sagemaker import get_execution_rolefrom sagemaker.pytorch import PyTorchModelimport time
hf_model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"# 获取 lim 推理容器image_uri = "763104351884.dkr.ecr.us-west-2.amazonaws.com/djl-inference:0.31.0-lmi13.0.0-cu124"print(f"Image going to be used is ---- > {image_uri}")
model_name= "deepseek-r1-distill-qwen-1-5b-"+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())endpoint_name = "Sagemaker-inference-componet-mme3"### lmi vllm配置方法同上一章节32B model一样,这里不再赘述
container_config = { 'Image': image_uri, 'ModelDataUrl': source_data, 'Environment': vllm_config}
response = sm_client.create_model( ModelName=model_name, ExecutionRoleArn=role, PrimaryContainer=container_config)
print(f"Model created: {response['ModelArn']}")
sm_client.create_inference_component( InferenceComponentName="IC-deepseek-r1-distill-qwen-1-5b-"+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime()), EndpointName=endpoint_name, VariantName="AllTraffic", Specification={ "ModelName": model_name, "ComputeResourceRequirements": { "NumberOfAcceleratorDevicesRequired": 1, "MinMemoryRequiredInMb": 4096 } }, RuntimeConfig={"CopyCount": 2},)左右滑动查看完整示意
说明:
32B的模型FP16精度需要64G以上显存,在A10 24G显存的卡上配置了4张卡,因此设置tensor张量并行为4(vllm不支持奇数,如3或者5,transformers layer无法均分到每个GPU上)。
由于vllm要预填充prefill tokens,Inference Component的MinGPU Memory需要设置较大一点(32B需要64G以上,目前通过MinMemoryRequiredInMb设置为80G)。
5B部署2个副本,设置copy参数为2,这样会在2个GPU上部署1.5B的模型的两个推理实例,Amazon SageMaker IC自动做负载均衡。
此处采用了Amazon SageMaker的vllm LMI推理镜像,vllm是rolling batch的动态批处理,吞吐量随着并发的增长有很好的扩展性,详细vllm介绍可参阅文末附录“vllm推理框架”。
Amazon SageMaker IC配置vllm推理引擎框架上,需要注意以下事项。
1.copies副本资源分配,目前不支持单个GPU再划分partition。
2.minGPU需要适量加大,因为vllm默认会prefill cache;如果GPU显存不足,适量减少queue size(max rolling batch size)和max model len。
3.Amazon SageMaker IC的GPU显存分配是针对单个copy的48x,如果8卡要部署2个copy,每个copy配置4卡就足够,IC自己会扩2个4卡,即8卡。
4.多个instance配置扩缩,可以指定copy副本级别请求调用量的metrics(注意,最终扩缩的还是instance实例,即copies增大,instance也需要对应增大,否则没有足够的GPU卡资源,同样会报错,扩缩失败),如下所示。
resource_id = f"inference-component/{inference_component_name}"service_namespace = "sagemaker"scalable_dimension = "sagemaker:inference-component:DesiredCopyCount"min_copy_count = 0max_copy_count = 8aas_client.register_scalable_target(ServiceNamespace=service_namespace,ResourceId=resource_id,ScalableDimension=scalable_dimension,MinCapacity=min_copy_count,MaxCapacity=max_copy_count,)左右滑动查看完整示意
5.多copies副本update、扩缩或initial时,可以通过Amazon SageMaker IC的describe API查看详细日志信息,如下所示。
endpoint_name = "Sagemaker-inference-componet-mme3"sm_client.describe_inference_component( #InferenceComponentName='IC-deepseek-r1-distill-qwen-32b-2025-02-25-14-27-09' InferenceComponentName='IC-deepseek-r1-distill-qwen-32b-2025-02-25-15-43-12')左右滑动查看完整示意
Amazon SageMaker IC管理
Amazon SageMaker IC提供了多种API和接口,可以方便地对已经部署的Component模型更新、删除和新增,如下所示。
查询Amazon SageMaker IC。
endpoint_name = "Sagemaker-inference-componet-mme3"sm_client.list_inference_components( EndpointNameEquals=endpoint_name)
endpoint_name = "Sagemaker-inference-componet-mme3"sm_client.describe_inference_component( #InferenceComponentName='IC-deepseek-r1-distill-qwen-32b-2025-02-25-14-27-09' InferenceComponentName='IC-deepseek-r1-distill-qwen-32b-2025-02-28-05-59-27')左右滑动查看完整示意
删除Amazon SageMaker IC。
##delete all IC componetendpoint_name = "Sagemaker-inference-componet-mme3"InferenceComponents = sm_client.list_inference_components( EndpointNameEquals=endpoint_name)['InferenceComponents']for InferenceComponent in InferenceComponents: IC_name = InferenceComponent['InferenceComponentName'] print(IC_name) sm_client.delete_inference_component(InferenceComponentName=IC_name)左右滑动查看完整示意
更新Amazon SageMaker IC。
response = sm_client.update_inference_component( InferenceComponentName='IC-deepseek-r1-distill-qwen-1.5b-2025-02-25-15-43-12', Specification={ "ModelName": "deepseek-r1-distill-qwen-1.5b-2025-02-25-15-43-11", 'ComputeResourceRequirements': { 'NumberOfAcceleratorDevicesRequired': 1, 'MinMemoryRequiredInMb': 4096 } }, RuntimeConfig={ 'CopyCount': 8 })左右滑动查看完整示意
LiteLLM
下文将介绍另一个重要的组件,通过LiteLLM proxy做MaaS的Agent分发。
LiteLLM是一个高效、灵活的工具,旨在简化与多个机器学习模型提供商的集成。它提供了一致的接口,使得开发者能够更容易地与不同的模型进行交互,无需关心底层的复杂实现。
LiteLLM特别适用于需要快速部署和管理多个模型的场景,能够显著提升开发效率和系统的可维护性,详见附录“LiteLLM Proxy开源Agent框架”。
在客户自建的MaaS中台中,LiteLLM proxy扮演着至关重要的角色,以下是其主要功能和优势。
多Provider集成
客户的MaaS中台需要接入各种模型,包括自建在Amazon SageMaker端点的LLM模型、Amazon Bedrock、第三方LLM SaaS模型。LiteLLM proxy能够无缝集成这些不同来源的模型,提供统一的访问接口。
统一API接入
为了简化外部业务的集成,客户需要一个统一的API接口。LiteLLM proxy提供了兼容的RESTful API,使得业务部门可以通过一个一致的接口与所有模型进行交互,极大地降低了集成成本和复杂度。
Token分发与账单分拆
在后期,系统需要实现token的分发和中台账单的分拆计费。LiteLLM proxy支持这些高级功能,确保每个请求都能正确地进行token管理和计费,从而实现精细化的成本控制和透明的账单分摊。
下文将详细介绍LiteLLM的安装部署和配置。
LiteLLM proxy安装
首先,您需要安装LiteLLM Proxy。新版本需要显式安装proxy组件。
pip install 'litellm[proxy]'在使用LiteLLM Proxy之前,需要设置一些环境变量以确保正确的配置和日志记录。
export LITELLM_LOG=DEBUG假设您要连接的Amazon SageMaker端点名称为Sagemaker-inference-componet-mme3,您还需要设置亚马逊云科技的访问密钥(如果使用Amazon EC2实例的实例身份角色,则不需要该步骤)。
export AWS_ACCESS_KEY_ID=your_aws_access_key_idexport AWS_REGION_NAME=us-west-2export AWS_SECRET_ACCESS_KEY=your_aws_secret_access_key左右滑动查看完整示意
使用以下命令启动LiteLLM Proxy,并指定要使用的Amazon SageMaker模型。
endpoint_name="Sagemaker-inference-componet-mme3"nohup litellm --model sagemaker/${endpoint_name} &左右滑动查看完整示意
您也可以通过YAML配置文件来设置Amazon SageMaker IC的相关参数,示例配置如下。
model_list: - model_name: sagemaker_ds litellm_params: model: sagemaker/sagemaker/Sagemaker-inference-componet-mme3 aws_region_name: ap-northeast-1 model_id: IC-deepseek-r1-distill-qwen-32b-2025-03-11-14-30-02 hf_model_name: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B max_tokens: 1024左右滑动查看完整示意
将上述配置保存为config.yaml,然后使用以下命令启动LiteLLM Proxy。
export LITELLM_LOG=DEBUG nohup litellm --model sagemaker_ds --config ./config.yaml &左右滑动查看完整示意
测试LiteLLM Proxy
LiteLLM proxy支持以兼容主流大模型推理接口格式的RESTful请求,调用后端的Amazon SageMaker端点,如下所示。
InferenceComponentName="IC-deepseek-r1-distill-qwen-32b-2025-03-11-14-30-02"endpoint_name="Sagemaker-inference-componet-mme3"
curl http://ec2-35-93-77-218.us-west-2.compute.amazonaws.com:4000/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "sagemaker/Sagemaker-inference-componet-mme3", "model_id": "IC-deepseek-r1-distill-qwen-32b-2025-03-11-14-30-02", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Hello!" } ], }'左右滑动查看完整示意
同样可以用SDK做兼容性测试。
InferenceComponentName='IC-deepseek-r1-distill-qwen-32b-2025-02-28-05-59-27'endpoint_name="Sagemaker-inference-componet-mme3"
import os from litellm import completionimport boto3
recipe_food = """How to make cake?"""
import openai # openai v1.0.0+client = openai.OpenAI(api_key="dummy", base_url="http://ec2-35-93-77-218.us-west-2.compute.amazonaws.com:4000") # set proxy to base_url# request sent to model set on litellm proxy, `litellm --model`response = client.chat.completions.create( model="deepseek-r1-qwen-32b", model_id="IC-deepseek-r1-distill-qwen-32b-2025-02-28-05-59-27", #如果在config.yaml 已配置model_id 这行可以不用加 messages = [ { "role": "user","content":prompt_template }], #stream=True, )
print(response)左右滑动查看完整示意
当然也可以使用LiteLLM completion的SDK,通过model_id传入Amazon SageMaker IC。
InferenceComponentName='IC-deepseek-r1-distill-qwen-32b-2025-03-11-14-30-02'endpoint_name="Sagemaker-inference-componet-mme3"
import os from litellm import completionimport boto3
recipe_food = """How to make cake?"""
## use completion sdk to pass component name via model idresponse = completion( model=f"sagemaker/{endpoint_name}", model_id=InferenceComponentName, messages=[{ "content": prompt_template,"role": "user"}], temperature=0.2, max_tokens=80, #stream=True, aws_access_key_id="*****", aws_secret_access_key="*********", aws_region_name="us-west-2", )for part in response: print(part.choices[0].delta.content or"") ###result >>> print(response['choices'][0]['message']['content'])Sure! Here's a classic vanilla cake recipe:
**Ingredients:**- 1 ½ cups (300g) all-purpose flour- 1 cup (200g) granulated sugar- 1 ½ tsp baking powder- ½ tsp salt- 1 cup (240ml) whole milk- 2 large eggs->>>左右滑动查看完整示意
LiteLLM SageMaker流式消息
Amazon SageMaker端点的LMI镜像流式消息,需要在vllm打开stream选项。
%%writefile serving.propertiesengine=Pythonoption.trust_remote_code=Trueoption.tensor_parallel_degree=4option.gpu_memory_utilization=.87option.max_model_len=10240option.model_id=deepseek-ai/DeepSeek-R1-Distill-Qwen-32Boption.max_rolling_batch_size=2option.rolling_batch=vllmoption.enable_streaming=true左右滑动查看完整示意
LiteLLM代码中,因为Amazon SageMaker的chunk encoder编码方式,会在超过chunk size时截断,造成一个token单词分在不同的chunk中输出。
因此在LiteLLM的stream_handle中,对应Amazon SageMaker LLM的CustomerStreamWapper的相应代码,需要做相应的定制修改,具体如下。
def __next__(self): ....省略if ( isinstance(self.completion_stream, str) or isinstance(self.completion_stream, bytes) or isinstance(self.completion_stream, ModelResponse) ): chunk = self.completion_stream ###增加判断逻辑,如果遇到sagemaker返回不是换行截断,则再取下一个chunk进行拼接 else: chunk = next(self.completion_stream) print("chunk ==",chunk) if(not chunk.endswith('\n')): next_chunk = next(self.completion_stream) chunk += next_chunk左右滑动查看完整示意
同时,在Continue、Cline等工具对接LiteLLM时,由于其调用的是LiteLLM SageMaker handler的异步的__anext__序列方法获取Amazon SageMaker的流式chunk输出,因此也需要处理chunk encoder编码截断的问题,具体如下。
async for chunk in iterator: event_stream_buffer.add_data(chunk) for event in event_stream_buffer: try: message = self._parse_message_from_event(event) if message: verbose_logger.debug("sagemaker parsed chunk bytes %s", message) # 移除 data: 前缀和 "\n\n" 结尾 message = ( litellm.CustomStreamWrapper._strip_sse_data_from_chunk(message) or"" ) message = message.replace("\n\n", "") # 累积 JSON 数据 accumulated_json += message # 尝试解析累积的 JSON try: _data = json.loads(accumulated_json) if self.is_messages_api: yield self._chunk_parser_messages_api(chunk_data=_data) else: yield self._chunk_parser(chunk_data=_data) # 解析成功后重置累积的 JSON 数据 accumulated_json = "" except json.JSONDecodeError: # 如果还不是有效的 JSON,继续处理下一个事件 continue except UnicodeDecodeError as e: verbose_logger.warning(f"UnicodeDecodeError: {e}. Attempting to combine with next event.") accumulated_json += "" # 跳过解析失败的event(sagemaker chunk encoder编码的截断符号) except Exception as e: verbose_logger.error(f"Error parsing message: {e}. Attempting to combine with next event.") accumulated_json += "" # 跳过解析失败的event(sagemaker chunk encoder编码的截断符号) # 处理最后一个累积的 JSON 数据(如果有) if accumulated_json: try: _data = json.loads(accumulated_json) if self.is_messages_api: yield self._chunk_parser_messages_api(chunk_data=_data) else: yield self._chunk_parser(chunk_data=_data) except json.JSONDecodeError as e: verbose_logger.error(f"Final JSONDecodeError: {e}") except Exception as e: verbose_logger.error(f"Final error parsing accumulated JSON: {e}")左右滑动查看完整示意
修改完毕后,通过pip在源代码目录下重新编译安装。
cd litellmpip install .LiteLLM调用时,RESTful参数中,传stream参数为true。
2.compute.amazonaws.com:4000/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "sagemaker/Sagemaker-inference-componet-mme3", "model_id": "IC-deepseek-r1-distill-qwen-32b-2025-03-11-14-30-02", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "I want to make coffee" } ], "stream":true }'左右滑动查看完整示意
从输出可以看出,已经是流式的chunk,每个chunk是标准的.json格式。
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":".","role":"assistant"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":" What"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":" do"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":" I"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":" need"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":"?\n\n"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":"</think>"}}]}
data: {"id":"chatcmpl-18f510a9-8c46-4e02-ab14-93582d40e1bc","created":1741732757,"model":"Sagemaker-inference-componet-mme3","object":"chat.completion.chunk","choices":[{"index":0,"delta":{"content":"\n\n"}}]}左右滑动查看完整示意
总结
综上所述,通过LiteLLM,Amazon SageMaker Inference Component推理端点,构建统一的MaaS中台,客户不仅能够集成多种模型,还能充分利用高性能硬件,实现资源的高效管理。
这种灵活且高效的架构,将为客户在人工智能领域的应用打下坚实的基础,助力其在竞争中脱颖而出。

附录
Amazon SageMaker Inference Component简介:
https://aws.amazon.com/cn/blogs/aws/amazon-sagemaker-adds-new-inference-capabilities-to-help-reduce-foundation-model-deployment-costs-and-latency
LiteLLM Proxy开源Agent框架:
https://docs.litellm.ai/docs
Amazon SageMaker vllm lmi推理镜像示例:
https://github.com/aws-samples/llm_deploy_gcr/blob/main/sagemaker/sagemaker_vllm/deploy_and_test.ipynb
vllm推理框架:
https://docs.vllm.ai/en/latest/getting_started/quickstart.html
本篇作者

唐清原
亚马逊云科技高级解决方案架构师,负责Data Analytic和人工智能与机器学习产品服务架构设计以及解决方案,拥有10多年数据领域研发及架构设计经验。在大数据BI、数据湖、推荐系统、MLOps等平台项目有丰富实战经验。

黎裕坚
亚马逊云科技高级解决方案架构师,负责基于亚马逊云科技的云计算方案架构的咨询和设计,同时致力于亚马逊云科技生成式AI类服务的应用和推广。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9477
9477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









