







海量视频内容的出现带来了一系列版权与内容重复问题。传统依靠人工或简单规则的视频检测方式已难以满足大规模视频处理的需求。
本文将探讨如何利用先进的深度学习模型和亚马逊云科技服务,实现高效的视频相似性检测。
方案背景与挑战
传统的视频检测方式主要依赖视频标题、描述或者简单的规则匹配,无法应对数据量激增和不断变化的内容特性。为此,本方案提出了一种新的思路:
自动化:通过生成式AI模型自动提取视频特征,无需人工干预。
高效性:采用Serverless架构,实现大规模并发处理与即时响应。
精准度:利用预训练的深度学习模型,实现高维特征提取和精细相似性计算。
核心技术与实现原理
视频相似度对比
方案核心在于对视频进行特征提取和相似度计算,主要步骤包括:
1.视频抽帧:利用OpenCV对视频进行均匀抽帧,将视频分解为一系列图像帧。
2.特征提取:使用预训练的ResNet50模型,对每一帧图像进行特征提取,生成一个1000维的特征向量。ResNet50作为图像分类领域的经典模型,既能保证准确率,又具备较好的计算效率。
3.向量矩阵构建:将视频中所有帧的特征向量整合成一个矩阵,为后续的相似性计算提供数据支持。
4.相似度计算:利用余弦相似度等算法,对视频间的特征向量进行比对,计算出相似度得分,判断视频内容的相似程度。
相似视频检索
针对相似视频的检索,本方案设计了一整套高效的向量检索流程:
1.向量存储:将提取出的高维视频特征向量存入Amazon OpenSearch向量数据库,这为后续检索提供了高效、可扩展的数据存储方案。
2.近似检索:利用KNN(K-Nearest Neighbors)算法,在海量向量数据中快速找到与查询视频最为相似的向量。
3.二次排序:对初步检索结果进行更精细的相似度计算,确保返回结果的精准性。
系统架构概览
整个方案采用Serverless架构,充分利用亚马逊云科技的众多服务,简要的系统架构如下图所示。
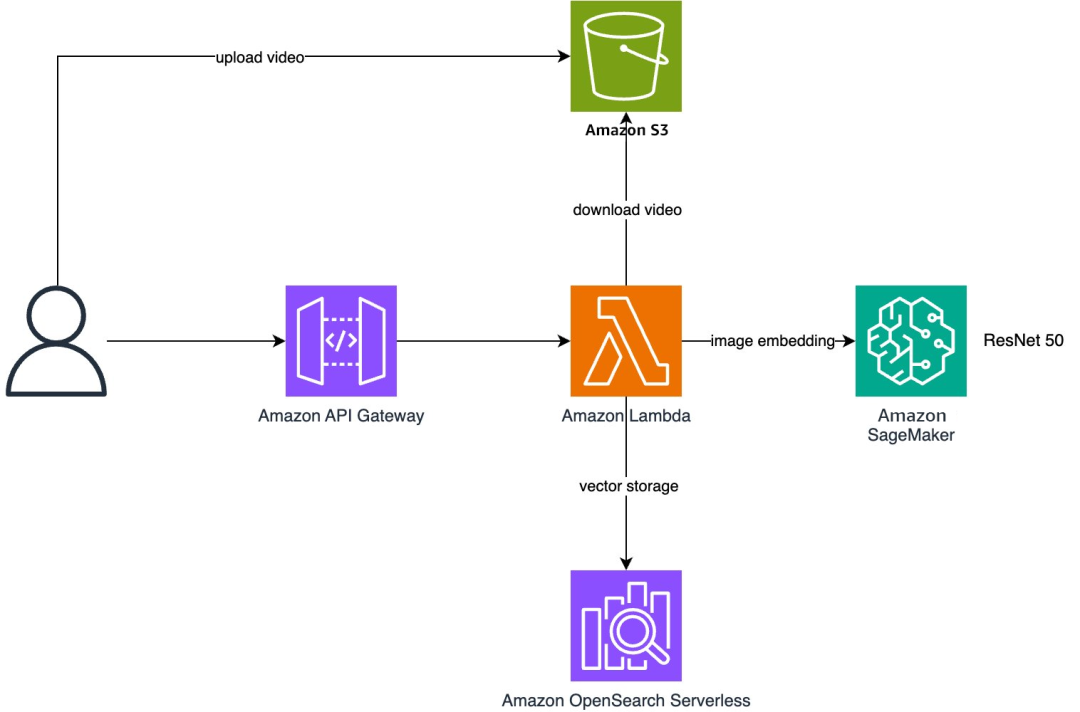
架构中各组件职责明确:
Amazon SageMaker AI:部署ResNet50模型,通过亚马逊云科技Marketplace订阅后,模型即服务(Model-as-a-Service)模式实现快速调用。
Amazon Web Services CDK:利用Amazon Web Services CDK实现一键部署,将各个组件(如Amazon API Gateway、Lambda函数等)快速、无缝集成。
Amazon OpenSearch:构建视频向量索引,支持高效的向量检索。
Amazon S3:作为视频文件的存储后端,结合Amazon Lambda实现实时数据更新与调用。
Demo部署与API接口
下方链接中的Demo项目,可以作为实践本方案的一种选择。
项目地址:
https://github.com/aws-samples/sample-for-video-similarity-using-serverless
项目部署
项目部署非常便捷,主要分为两步。
1
订阅并部署ResNet50模型
前往亚马逊云科技Marketplace完成一键订阅部署,并记下Amazon SageMaker端点名称。亚马逊云科技提供了可免费订阅的ResNet50模型,支持一键部署至Amazon SageMaker推理端点,在页面上订阅模型,然后使用Amazon Cloudformation一键部署(机型选择ml.g4dn.xlarge即可)。
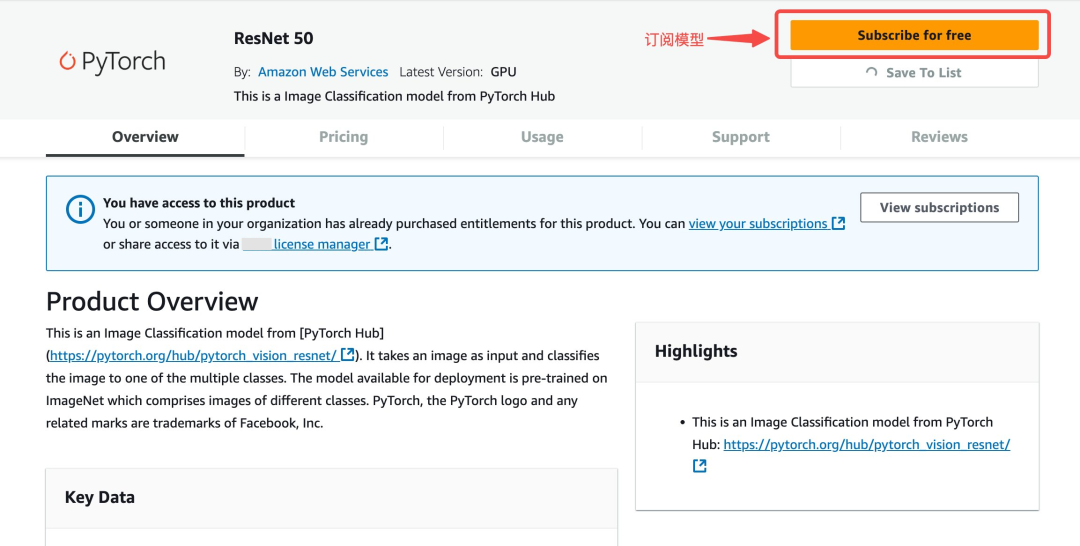
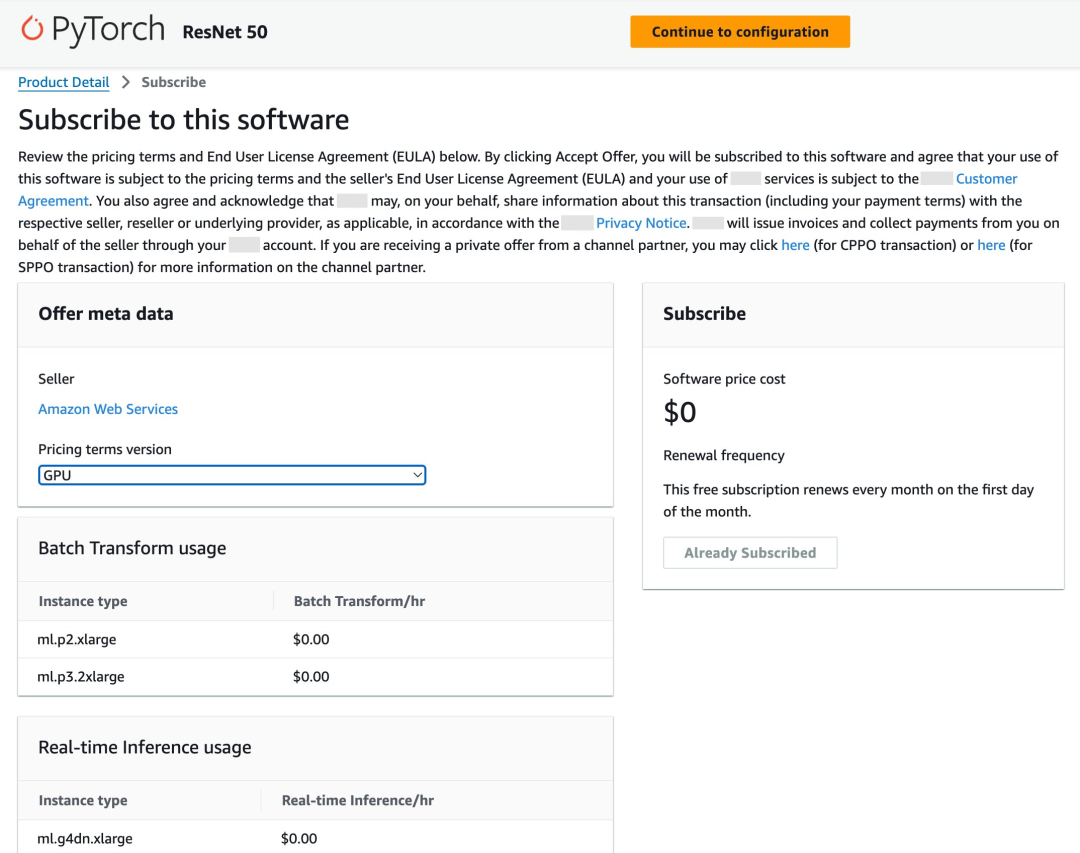
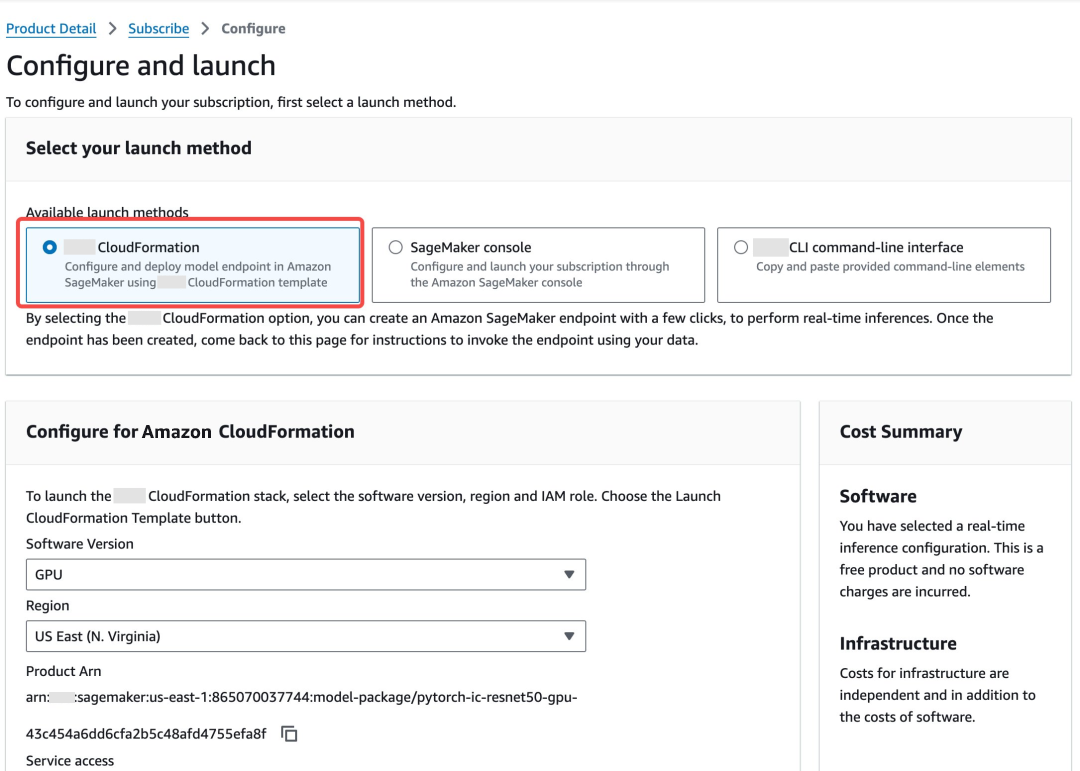
亚马逊云科技Marketplace:
https://aws.amazon.com/marketplace/ai/procurement?productId=cc879d3b-e759-4270-9afb-ceb50d2f7fe6
2
Amazon Web Services CDK一键部署
克隆项目代码,使用Amazon Web Services CDK将整个项目部署到亚马逊云科技环境中。
cd src/cdk# 示例:指定 SageMaker 终端名称cdk deploy --parameters sagemaker_endpoint=ResNet50左右滑动查看完整示意
部署完成后,获取Amazon API Gateway的端点,再调用接口创建OpenSearch索引。
curl --location 'https://{{apigateway.endpoint.url}}/create_opensearch_index' \--header 'Content-Type: text/plain' \--data '{}'左右滑动查看完整示意
主要API接口说明
项目主要提供以下API:
获取视频向量:生成视频向量数据。
将视频向量插入数据库:生成视频向量数据,并将向量数据插入到向量数据库中。
检索相似视频:通过一个视频在存储库中检索出相似视频。
对比两个视频相似度:输出给定的两个视频的相似度分数。
更多API的详细说明,参见项目README文件。
测试结果

测试结果探讨以及进一步优化探索
从项目架构与实现来看,本方案不仅展示了生成式AI在视频内容识别领域的强大能力,更体现了亚马逊云科技云服务在处理大规模数据和实现Serverless架构方面的优势,但是在一些方面仍有改进空间,特别是在面对增加黑框和图像颜色变换后,视频的相似度会受到极大影响。
因为不同的业务场景对相似视频的定义不同(例如有的业务场景下,视频颜色变化后属于创新作品,而不应被认为相似作品),本方案设计的初衷还是在不改变视频原有特征的情况下做相似度比对,如果您对加黑框视频以及颜色变换视频有相似度检索需求,可以尝试在本方案的基础上进行以下探索。
对视频进行预处理以增强鲁棒性,例如:检测并裁剪边框(如通过边缘检测或训练边框分割模型),提取特征前将图片转换为灰度图(牺牲颜色信息但提升对调色鲁棒性)。
提取特征向量时,尝试使用DINO(Self-Supervised Vision Transformer)模型,可能对局部变换(裁剪、翻转、添加边框等)鲁棒性更强。
总结
本方案通过结合生成式AI模型、Serverless架构以及向量检索技术,构建了一个高效、自动化的视频相似性检测系统。
这个项目不仅展示了技术的前沿应用,也为视频版权保护和内容管理提供了新的思路。
本篇作者

张召
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案的架构设计,同时致力于亚马逊云科技的云服务在移动应用与互联网行业的应用和推广。拥有多年移动互联网研发及技术团队管理经验,丰富的互联网应用架构项目经历。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9477
9477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









