







AI Agents日益流行,Agent工具正让更多应用改变工作和生活方式,优化企业生产流程。在实际应用中,数据必不可少。如何自动调用工具访问数据,并产生需要的结果?Model Context Protocol(MCP)定义了应用程序向AI应用提供上下文的方式,遵循MCP协议的应用,可以调用各种工具扩展AI能力。
同时,MCP Server结合数据库,可以自动编写理解自然语言的数据访问语句,按照需求构建数据访问流程。本文将介绍多种MCP结合数据库的应用场景,帮助您更加智能访问数据库,直接根据业务需求获取数据结果。
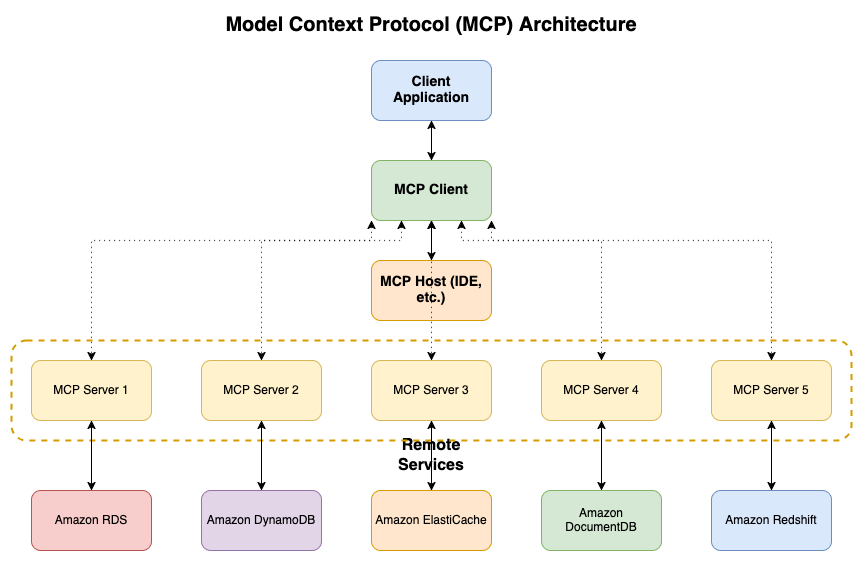
MCP结合数据库架构图
MCP数据库场景:AI工具助手
MCP工具厂商提供了多种工具,包括数据分析。对于营销公司,需要筛选本月抖音爆款视频,可以构建以下MCP工具来完成。
爬取平台数据→分析互动指标→生成TOP50榜单→打包下载链接
1.调用爬虫MCP,获取特定网页数据。
2.调用数据库MCP,爬虫数据写入数据库,并构造SQL查询,生成分析结果。
3.调用文件MCP,生成下载信息汇总。
下文将演示更具体的使用案例。
MCP数据库场景:市场营销分析
需要获取二手车的销售情况,进行分析预测,制定将来销售计划。
流程如下:
爬虫MCP(Firecrawl):爬虫获取汽车垂直网站销售信息,包括型号、车况、年限、价格。
数据库MCP(Mysql):爬取的数据写入数据库,创建视图,构造SQL查询。
大模型:根据查询结果生成分析报告。
具体步骤如下。
1.创建支持MCP的Agent应用,您可参阅Github代码库参考流程。
具体实验步骤可参阅《基于MCP构建端到端的Agentic AI应用工作坊》。
Github代码库:
https://github.com/aws-samples/demo_mcp_on_amazon_bedrock
《基于MCP构建端到端的Agentic AI应用工作坊》
https://catalog.us-east-1.prod.workshops.aws/workshops/d674f40f-d636-4654-9322-04dafc7cc63e/zh-CN
2.安装Firecrawl爬虫工具,支持MCP,您可参阅之前实验的MCP Server安装步骤。
MCP Server安装步骤:
https://catalog.us-east-1.prod.workshops.aws/workshops/d674f40f-d636-4654-9322-04dafc7cc63e/zh-CN/2-lab-1/2-4-usage
获取Firecrawl API KEY。
配置Firecrawl MCP Server。
{ "mcpServers": { "firecrawl-mcp": { "command": "npx", "args": ["-y", "firecrawl-mcp"], "env": { "FIRECRAWL_API_KEY": "YOUR FIRECRAWL API KEY" } } }}左右滑动查看完整示意
3.配置Mysql MCP Server。您可参阅《基于MCP构建端到端的Agentic AI应用工作坊:MCP结合数据库应用》。
《基于MCP构建端到端的Agentic AI应用工作坊:MCP结合数据库应用》
https://catalog.us-east-1.prod.workshops.aws/workshops/d674f40f-d636-4654-9322-04dafc7cc63e/zh-CN/2-lab-1/2-5-database
配置文件如下,可以控制数据库访问方式,例如只读,执行DDL等。本示例中允许数据库读写和DDL更改表结构。修改数据库连接地址、用户名和密码。
{ "mcpServers": { "mcp_server_mysql": { "command": "npx", "args": [ "-y", "@benborla29/mcp-server-mysql" ], "env": { "MYSQL_HOST": "Your RDS Mysql endpoint", "MYSQL_PORT": "3306", "MYSQL_USER": "Your user", "MYSQL_PASS": "Your Password", "MYSQL_DB": "mcp", "ALLOW_INSERT_OPERATION": "true", "ALLOW_UPDATE_OPERATION": "true", "ALLOW_DELETE_OPERATION": "true", "ALLOW_DDL_OPERATION": "true", "PATH": "/usr/bin:/home/ubuntu/.nvm/versions/node/v22.12.0/bin/", "NODE_PATH": "/home/ubuntu/.nvm/versions/node/v22.12.0/lib/node_modules" } } }}左右滑动查看完整示意
4.配置完成后,启用Firecrawl和Mysql MCP Server。
5.开始与Agent应用交互。
提示词如下。
Crawl second hand Tesla sales data from Internet, save data into Mysql, then generate sales report.
生成结果如下。
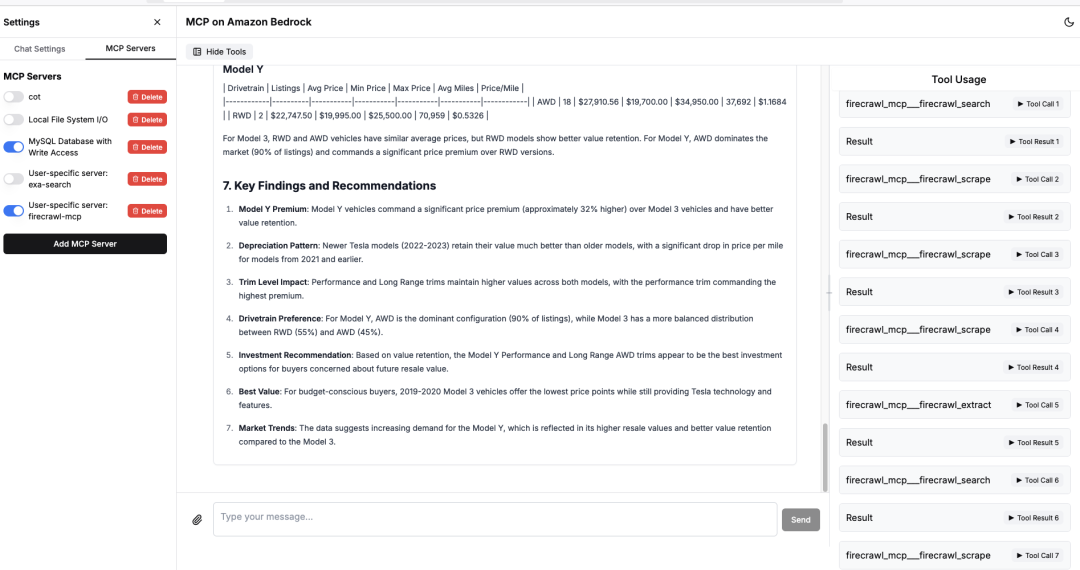
MCP爬虫结合数据库调用过程如下。
1.Tool:爬取二手车销售数据。
访问二手车垂直网站相关页面,如果没有指定网站,大模型会自己思考去哪里获取这些信息。
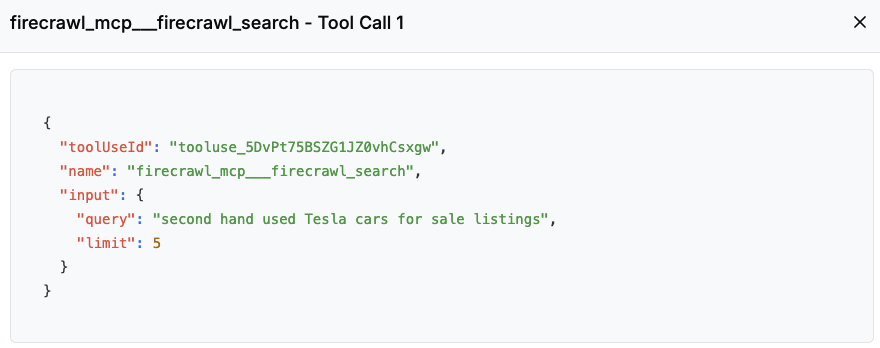
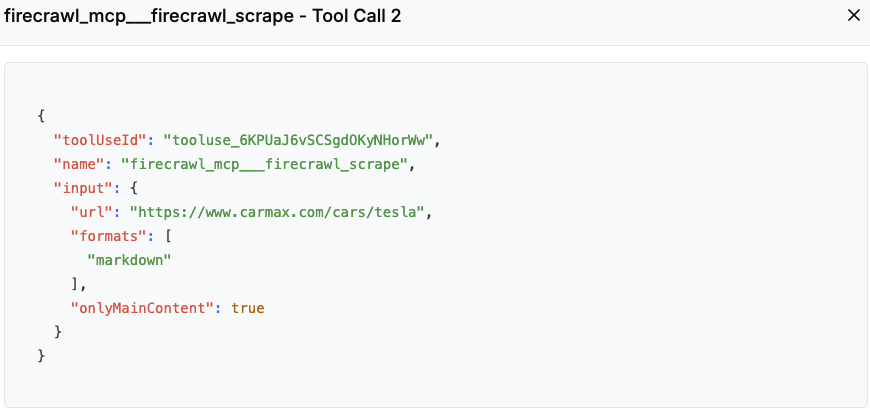
返回结果,包含需要的车辆销售数据。
2.Tool:Mysql:创建表,将爬取下来的数据写入数据库。
"toolUseId": "tooluse_p8L63DPyQx6EEHmYZ5b2xg", "name": "mcp_server_mysql___mysql_query", "input": { "sql": "CREATE DATABASE IF NOT EXISTS tesla_sales;"左右滑动查看完整示意
创建表。
{ "toolUseId": "tooluse_oJq9lchjQBaoJcdOI8m8NQ", "name": "mcp_server_mysql___mysql_query", "input": { "sql": "CREATE TABLE IF NOT EXISTS tesla_sales.used_tesla_sales (\n id INT AUTO_INCREMENT PRIMARY KEY,\n vin VARCHAR(17) NOT NULL,\n year INT NOT NULL,\n model VARCHAR(10) NOT NULL,\n color VARCHAR(20) NOT NULL,\n miles INT NOT NULL,\n trim VARCHAR(100) NOT NULL,\n sold_price DECIMAL(10, 2) NOT NULL,\n interior VARCHAR(50),\n wheels VARCHAR(20),\n features TEXT,\n country VARCHAR(2),\n location VARCHAR(100),\n metro VARCHAR(100),\n state VARCHAR(2),\n currency VARCHAR(3),\n sold_date DATE,\n created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,\n UNIQUE KEY (vin)\n);" }左右滑动查看完整示意
写入数据。

3.Tool:获取数据后,生成Mysql视图,包含销售数据和对比。
{ "toolUseId": "tooluse_G3BkF4cyQ6uLjTdIVgCu-w", "name": "mcp_server_mysql___mysql_query", "input": { "sql": "-- Create a view for the sales report\nCREATE OR REPLACE VIEW tesla_sales.sales_report AS\nSELECT \n model,\n year,\n COUNT(*) AS total_listings,\n ROUND(AVG(price), 2) AS avg_price,\n ROUND(MIN(price), 2) AS min_price,\n ROUND(MAX(price), 2) AS max_price,\n ROUND(AVG(miles), 0) AS avg_miles,\n ROUND(MIN(miles), 0) AS min_miles,\n ROUND(MAX(miles), 0) AS max_miles,\n ROUND(AVG(price/miles), 4) AS avg_price_per_mile,\n COUNT(DISTINCT trim) AS trim_variants,\n ROUND((SELECT COUNT(*) FROM tesla_sales.used_tesla_sales s2 \n WHERE s2.model = s1.model AND s2.drivetrain = 'AWD' AND s2.year = s1.year) / \n COUNT(*) * 100, 2) AS pct_awd\nFROM tesla_sales.used_tesla_sales s1\nGROUP BY model, year\nORDER BY model, year DESC;" }}
{ "toolUseId": "tooluse_RzxCEAyLSZqXtpHSSkhk2w", "name": "mcp_server_mysql___mysql_query", "input": { "sql": "-- Create a model comparison view\nCREATE OR REPLACE VIEW tesla_sales.model_comparison AS\nSELECT \n model,\n COUNT(*) AS total_listings,\n ROUND(AVG(price), 2) AS avg_price,\n ROUND(MIN(price), 2) AS min_price,\n ROUND(MAX(price), 2) AS max_price,\n ROUND(AVG(miles), 0) AS avg_miles,\n ROUND(MIN(miles), 0) AS min_miles,\n ROUND(MAX(miles), 0) AS max_miles,\n ROUND(AVG(price/miles), 4) AS avg_price_per_mile,\n COUNT(DISTINCT year) AS model_years,\n COUNT(DISTINCT trim) AS trim_variants,\n ROUND(SUM(CASE WHEN drivetrain = 'AWD' THEN 1 ELSE 0 END) / COUNT(*) * 100, 2) AS pct_awd\nFROM tesla_sales.used_tesla_sales\nGROUP BY model\nORDER BY total_listings DESC;" }}左右滑动查看完整示意
4.Tool:根据视图查询结果,生成分析报告,包含摘要、车型对比、年销售趋势等。
{ "toolUseId": "tooluse_8JVuTNMLTsymD4YwN8HH5A", "name": "mcp_server_mysql___mysql_query", "input": { "sql": "-- Model & Year Analysis\nSELECT \n 'Model & Year Analysis' AS section,\n model,\n year,\n COUNT(*) AS total_listings,\n ROUND(AVG(price), 2) AS avg_price,\n ROUND(MIN(price), 2) AS min_price,\n ROUND(MAX(price), 2) AS max_price,\n ROUND(AVG(miles), 0) AS avg_miles,\n ROUND(AVG(price/miles), 4) AS avg_price_per_mile\nFROM tesla_sales.used_tesla_sales\nGROUP BY model, year\nORDER BY model, year DESC;" }}左右滑动查看完整示意

至此,整个流程结束。此过程完全由AI控制,有了爬虫和数据库MCP Server,赋予大模型额外的工作能力,自己思考如何调用这些工具来完成任务。
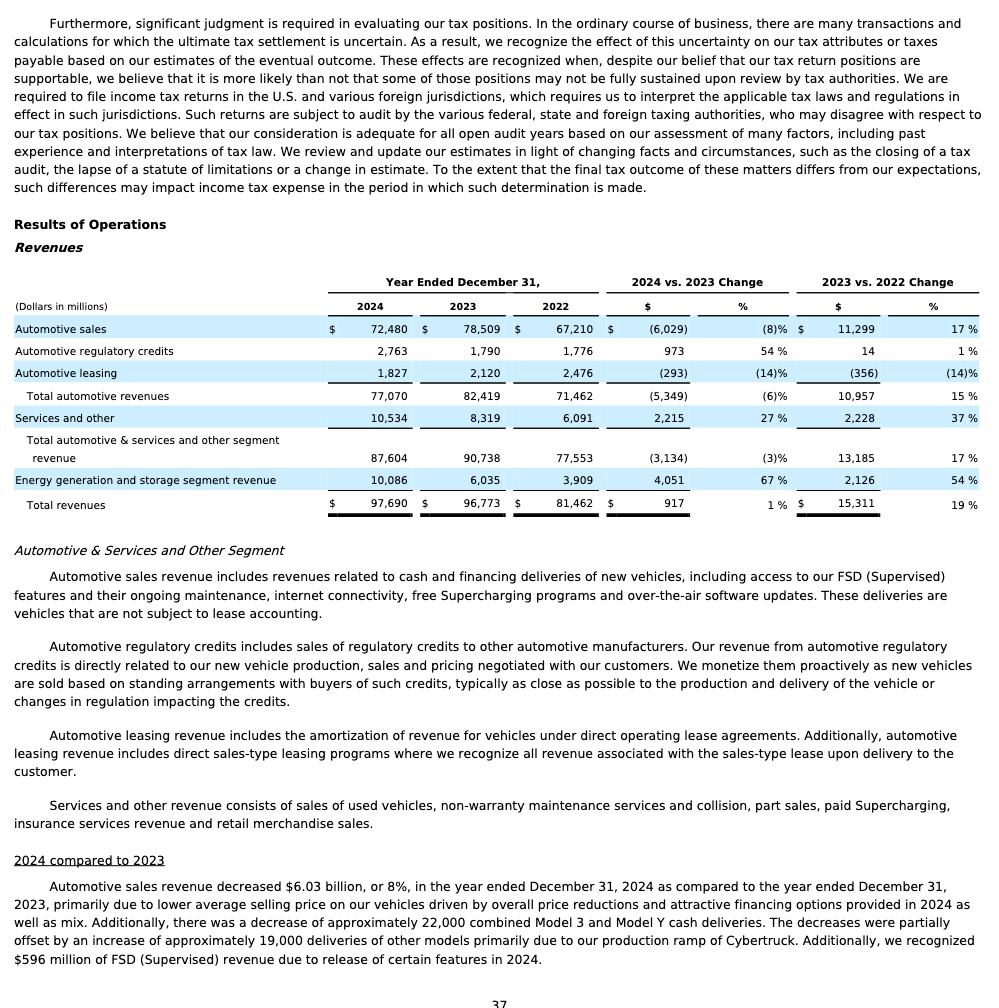
Firecrawl爬虫MCP支持多层数据抓取。在读写数据库时,自动调用数据库访问工具,构建SQL,创建表,写入数据,并根据业务需求,创建多个视图和分析查询,获取近期二手车的销售情况,包括车型、价格、销量。按照这些查询结果,给出分析摘要。
Model Y Premium: Model Y vehicles command a significant price premium (approximately 32% higher) over Model 3 vehicles and have better value retention.
Depreciation Pattern: Newer Tesla models (2022-2023) retain their value much better than older models, with a significant drop in price per mile for models from 2021 and earlier.
Trim Level Impact: Performance and Long Range trims maintain higher values across both models, with the performance trim commanding the highest premium.
Drivetrain Preference: For Model Y, AWD is the dominant configuration (90% of listings), while Model 3 has a more balanced distribution between RWD (55%) and AWD (45%).
Investment Recommendation: Based on value retention, the Model Y Performance and Long Range AWD trims appear to be the best investment options for buyers concerned about future resale value.
Best Value: For budget-conscious buyers, 2019-2020 Model 3 vehicles offer the lowest price points while still providing Tesla technology and features.
Market Trends: The data suggests increasing demand for the Model Y, which is reflected in its higher resale values and better value retention compared to the Model 3.
传统的Text2SQL,关注于单个SQL实现,并不能串联整个流程。大模型生成的语句,有可能不能执行,或者执行结果不符合需求。如果要更为准确地生成SQL语句,需要给出更多提示词,包括表结构,而这些额外工作却使得业务人员难以使用。
相对而言,MCP更灵活,生成的结果也更准确。MCP构建工具调用,根据上个结果,调整下一个语句,完成不同阶段的SQL,直到生成SQL满足需求。
MCP所指的上下文,不只是提示词,更是工具调用上下文。业务人员只需要提业务需求,剩下就是等待结果。实际效果来看,MCP生成的SQL语句,更加符合业务需求。
*提及的第三方品牌和公司名称仅用于举例说明其在相关技术场景中的应用,示例数据来源于公开互联网信息或模拟生成,用于演示MCP与数据库结合的技术能力,非真实商业案例。
MCP数据库场景:RAG补充
结合MCP+RAG知识库
继续深化此场景。现在已经有了从专业网站获取的二手车外部市场信息,单纯的外部数据只是部分参考,结合企业内部数据使用才能更准确反映市场和企业自身情况。
如何基于内部销售数据和外部爬虫获取的数据,分析并预测车辆销售?
可以考虑MCP+RAG方式:MCP分别调用RAG内部知识库和Mysql外部爬虫数据,构造查询过程,结合内部和外部数据,作出更准确预测。
RAG使用向量数据服务,把数据分片后,进行向量化存储,按照相似度查询出最接近的数据。通常适用于企业内部文档数据处理,作为内部知识库,为大模型增加私有知识能力,更满足特定业务需求。应用场景包括:智能客服、内部数据分析、专业知识问答、专有词汇处理。
多种向量数据库或者大数据产品可以用于RAG,例如:
Amazon OpenSearch
PostgreSQL vector
Amazon DocumentDB vector
Amazon MemoryDB vector search
Amazon Bedrock知识库
RAG和MCP各自特点如下:
RAG:以向量数据为大模型提供知识库,提高大模型的特定领域知识能力,根据问题语义查询返回相似度最高的数据结果。但是,多个切片难以获取全局信息。侧重于知识问答和内容生成。
MCP:更擅长构建上下文的工具调用。不需要指定特定表和语句,自动调用数据库访问,包括列出表结构,分析表内容以判断是否符合需求,并构建查询语句,返回精确查询结果。侧重于工作编排、自动化工具代理。
MCP和RAG可以互补,构建理解知识并能行动的智能自主系统。
假设企业有内部销售数据,存放于向量数据库Amazon OpenSearch上的Amazon Bedrock知识库,可以很容易从现有文档转换到知识库,无论是否结构化文档,包括txt、Excel、PDF等。
本例把公司2024年财报,以向量数据方式,存储于Amazon OpenSearch,作为Amazon Bedrock知识库,包含大模型尚未知晓的销售数据。
您可参阅文档导入向量化知识库。
文档导入向量化知识库:
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-build.html
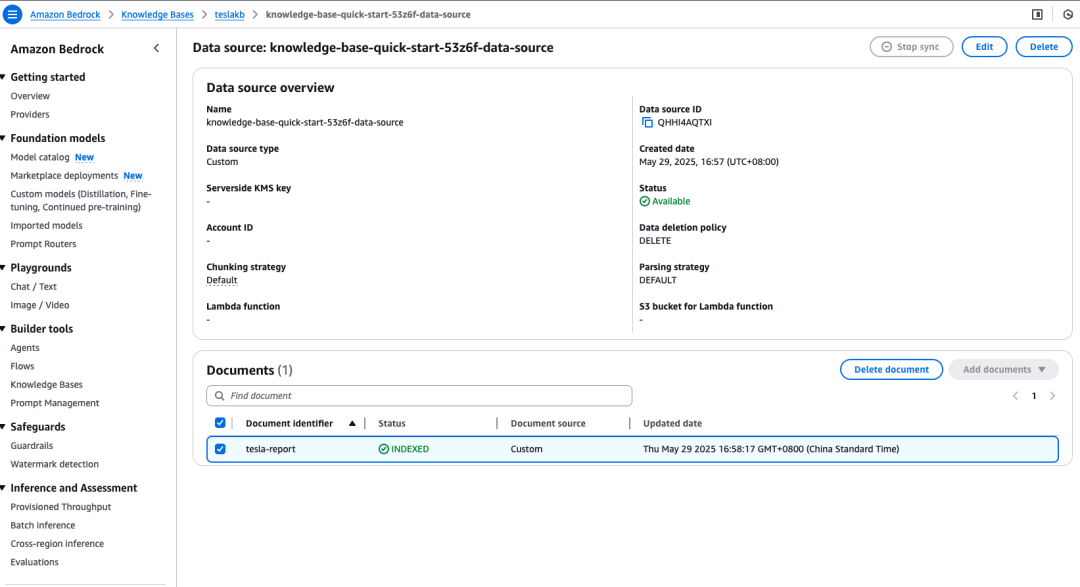
RAG知识库构建完成,接下来配置MCP Server。
MCP支持Amazon Bedrock知识库,可以完成以下任务。
1.发现知识库及其数据源:
查找并浏览所有可用的知识库。
按名称或标签搜索知识库。
列出与每个知识库相关的数据源。
2.使用自然语言查询知识库:
使用对话查询检索信息。
从知识库中获取相关段落。
访问所有结果的引文信息。
3.按数据源筛选结果:
将查询重点放在特定的数据源上。
包括或排除特定的数据源。
优先考虑来自特定数据源的结果。
4.重新排列结果:
提高检索结果的相关性。
使用Amazon Bedrock reranking。
按与查询的相关性对结果进行排序。
使用Amazon Q Developer CLI工具作为客户端。
配置文件(~/.aws/amazonq/mcp.json)如下,修改profile为Amazon Web Services CLI profile,默认为default。
{ "mcpServers": { "awslabs.bedrock-kb-retrieval-mcp-server": { "command": "uvx", "args": ["awslabs.bedrock-kb-retrieval-mcp-server@latest"], "env": { "AWS_PROFILE": "your-profile-name", "AWS_REGION": "us-east-1", "FASTMCP_LOG_LEVEL": "ERROR", "KB_INCLUSION_TAG_KEY": "optional-tag-key-to-filter-kbs", "BEDROCK_KB_RERANKING_ENABLED": "false" }, "disabled": false, "autoApprove": [] } }}左右滑动查看完整示意
配置MCP Server完成后,启用MCP for Mysql与Amazon Bedrock知识库,与Agent应用交互,结合内部知识库和爬虫数据,预测2025年二手车的销售情况。
提示词如下。
Based on Tesla sales revenue in 2024 in knowledge base “GUQMWFBAEO”, and crawl data stored in Mysql from second hand web site, predict the most popular second hand Tesla model and sales revenue in 2025.
输出结果如下。
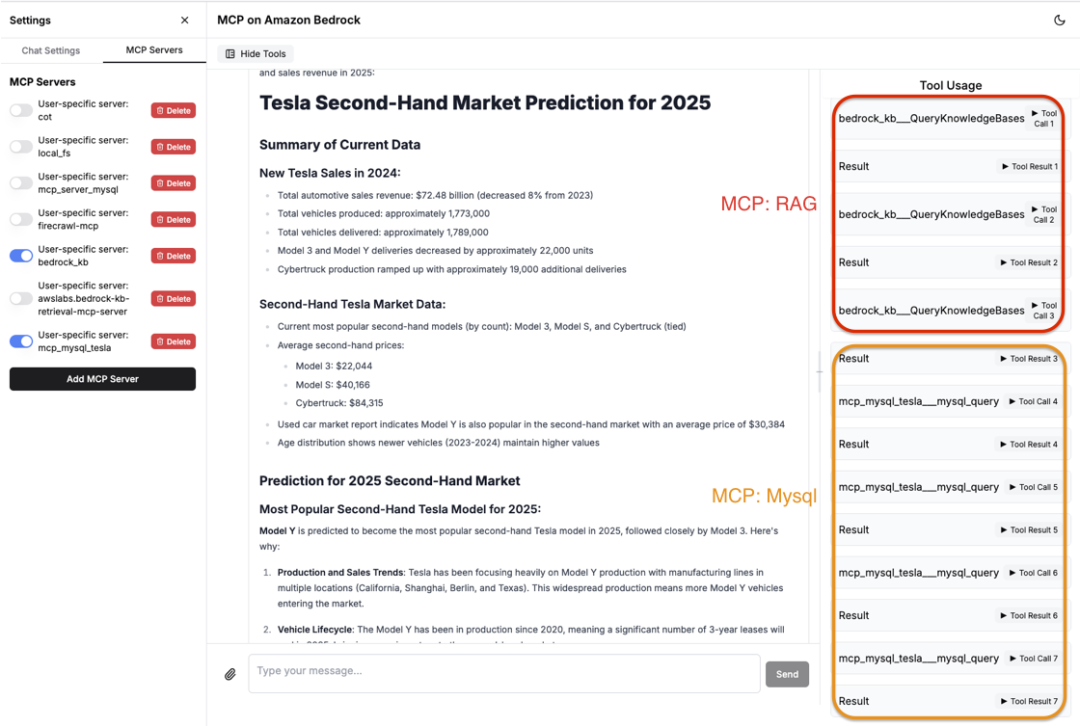
您可点击文末“阅读原文”,获取详细的处理过程。
根据内部销售数据(RAG)和爬虫数据(MySQL),使用MCP工具把内外数据结合起来,可为业务提供更精准的数据来源和分析。
相对于只依赖内部或者外部数据,通过MCP将RAG+Mysql结合使用,能为业务提供更全面的数据,以获得更准确的数据洞察。
*提及的第三方品牌和公司名称仅用于举例说明其在相关技术场景中的应用,示例数据来源于公开互联网信息或模拟生成,用于演示MCP与数据库结合的技术能力,非真实商业案例。
MCP数据库场景:网站前后端开发
生成式AI可以帮助用户轻松创建网站或者APP前后端。作为应用的核心部分,数据库有多种选择。借助MCP,可以根据不同业务需求使用对应的数据库。此过程可以让MCP调用相应的数据库工具,完成创建表和业务语句。
以下示例中,使用Amazon Q CLI工具,结合MCP一键式构建车辆销售网站前后端应用,并设计数据库结构。
前端:Amazon Labs Frontend MCP Server。
通过getReactDocsByTopic工具,提供React应用程序开发的全面文档。
基础知识:构建React应用程序的基本概念。
基本用户界面设置:使用Tailwind CSS和shadcn/ui设置React项目。
身份验证:Amazon Amplify身份验证集成。
路由:使用React Router实现路由。
自定义:使用Amazon Amplify组件设置主题。
创建组件:使用亚马逊云科技集成构建React组件。
后端数据库:Mysql MCP Server。
使用MCP构建数据库和表结构,写入网站初始数据。
OLTP交易直接访问数据库,不使用MCP。
以下MCP配置文件(~/.aws/amazonq/mcp.json),包括MCP前端(awslabs.frontend-mcp-server)和Mysql(mcp_mysql_web),注意Mysql要允许读写和DDL。
{ "mcpServers": { "awslabs.frontend-mcp-server": { "command": "uvx", "args": ["awslabs.frontend-mcp-server@latest"], "env": { "FASTMCP_LOG_LEVEL": "ERROR" }, "disabled": false, "autoApprove": [] }, "mcp_mysql_web": { "command": "npx", "args": [ "-y", "@benborla29/mcp-server-mysql" ], "env": { "MYSQL_HOST": "mysql8.c7b8fns5un9o.us-east-1.rds.amazonaws.com", "MYSQL_PORT": "3306", "MYSQL_USER": "admin", "MYSQL_PASS": ”xxxxxxxx", "MYSQL_DB": "web", "ALLOW_INSERT_OPERATION": "true", "ALLOW_UPDATE_OPERATION": "true", "ALLOW_DELETE_OPERATION": "true", "ALLOW_DDL_OPERATION": "true", "PATH": "/usr/bin:/home/ubuntu/.nvm/versions/node/v22.12.0/bin/", "NODE_PATH": "/home/ubuntu/.nvm/versions/node/v22.12.0/lib/node_modules" }, "description": "MySQL_Web" } }}左右滑动查看完整示意
配置完成后,使用Amazon Q CLI,支持MCP Frontend与Mysql,自动构建包括前后端的网站。
各部分提示词如下。
创建前端:
> create vertical web site for vehicle selling
后端应用+数据库:
> based on current project for front-end, add backend application for orders, data is stored in RDS Mysql database.
> MCP server for Mysql is used for web application development. However, in production application, database is accessed directly without MCP for OLTP transaction.
创建过程中,Amazon Q CLI自动执行所有步骤。
最终生成项目如下。
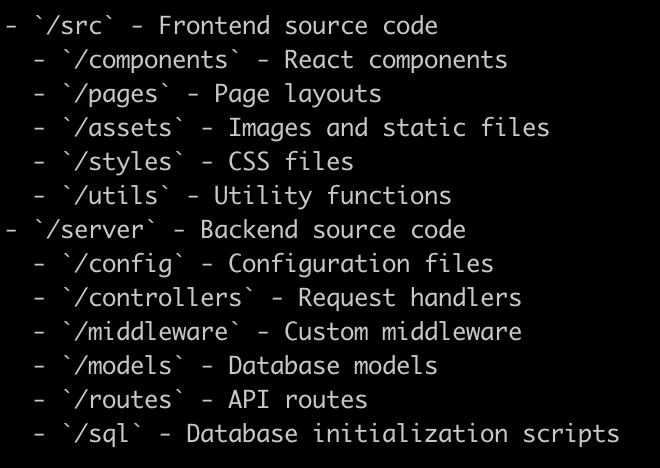
前端:
–React.js
–CSS for styling
–React Router for navigation
后端:
–Node.js with Express
–MySQL database with Sequelize ORM
–JWT for authentication
数据库表结构已经创建,并有测试数据。
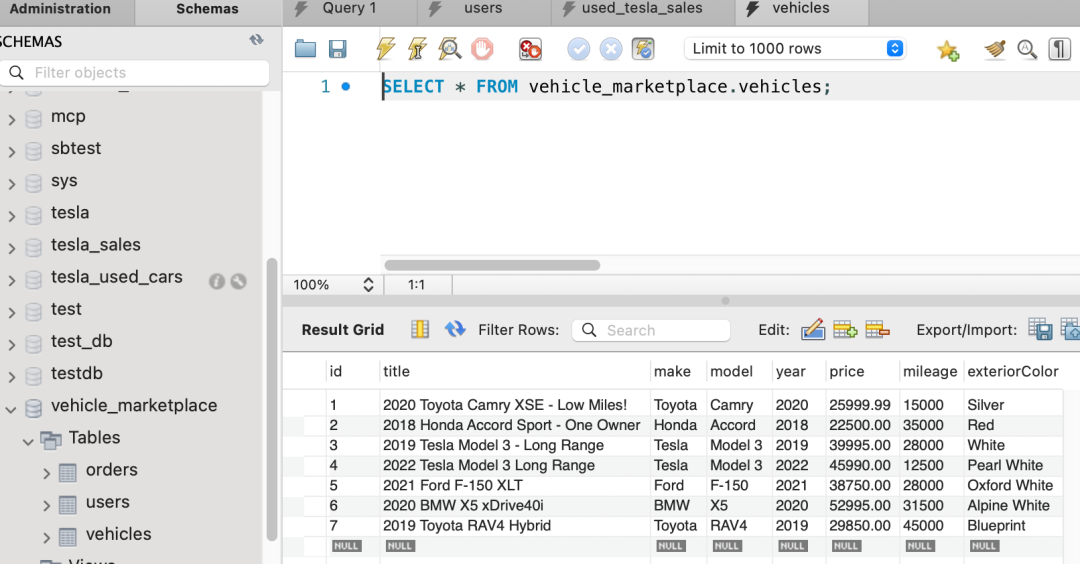
运行整个项目,页面和后端应用都可以运行,包括查询等功能。
需要注意的是,在此场景中,生成数据库结构时使用了MCP工具,此过程由大模型生成,需要较长时间。但是在线交易OLTP系统中,对数据要求实时访问,应用程序应该直接访问数据库,而不是通过MCP访问,否则每次数据库访问都需要大模型生成,速度自然慢很多,客户体验受到影响。
当然,OLTP访问数据库的代码,仍然可以由MCP生成,只是应用程序访问数据库的时候不使用MCP。
MCP数据库场景:审计数据处理
审计事务所需要从多个公司的财务和经营数据中,获取与审计相关的信息。数据源会有很多种,包括企业CRM数据库、Excel表格、PDF文档,有些原始数据的格式并非标准化,还可能会缺少一些数据。需要把如此多种类的数据源,按照审计要求,统一到特定格式报表。此过程会有几个难点:
多种数据源数据统一格式
按照审计需求设计表结构
从多个原始表写入统一审计表
如何从复杂的数据源,抽取并整理成业务数据?
原来的工作模式,需要手动处理这些繁杂的工作,并以审计人员的经验编写SQL语句。如果数据有更新,还需要重新处理。借助大模型,自动整理数据,并按照审计流程写入数据库,可以极大提高效率。MCP赋予大模型更多能力,处理文档,访问数据库。
MCP优化后的审计处理流程如下:
获取相关源数据
Amazon Q CLI
数据整合处理,例如Excel到CSV
MCP Database
按照源数据和审计要求创建表
查询源表相关数据,写入统一格式审计表
审计人员查询
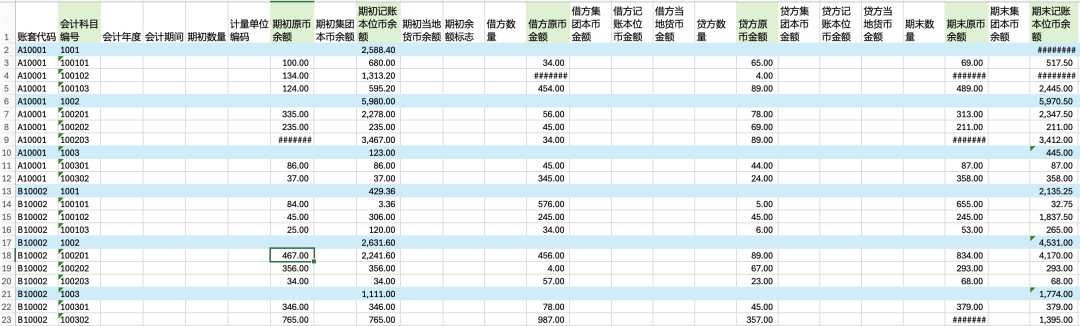
示例数据,科目余额及发生额表。
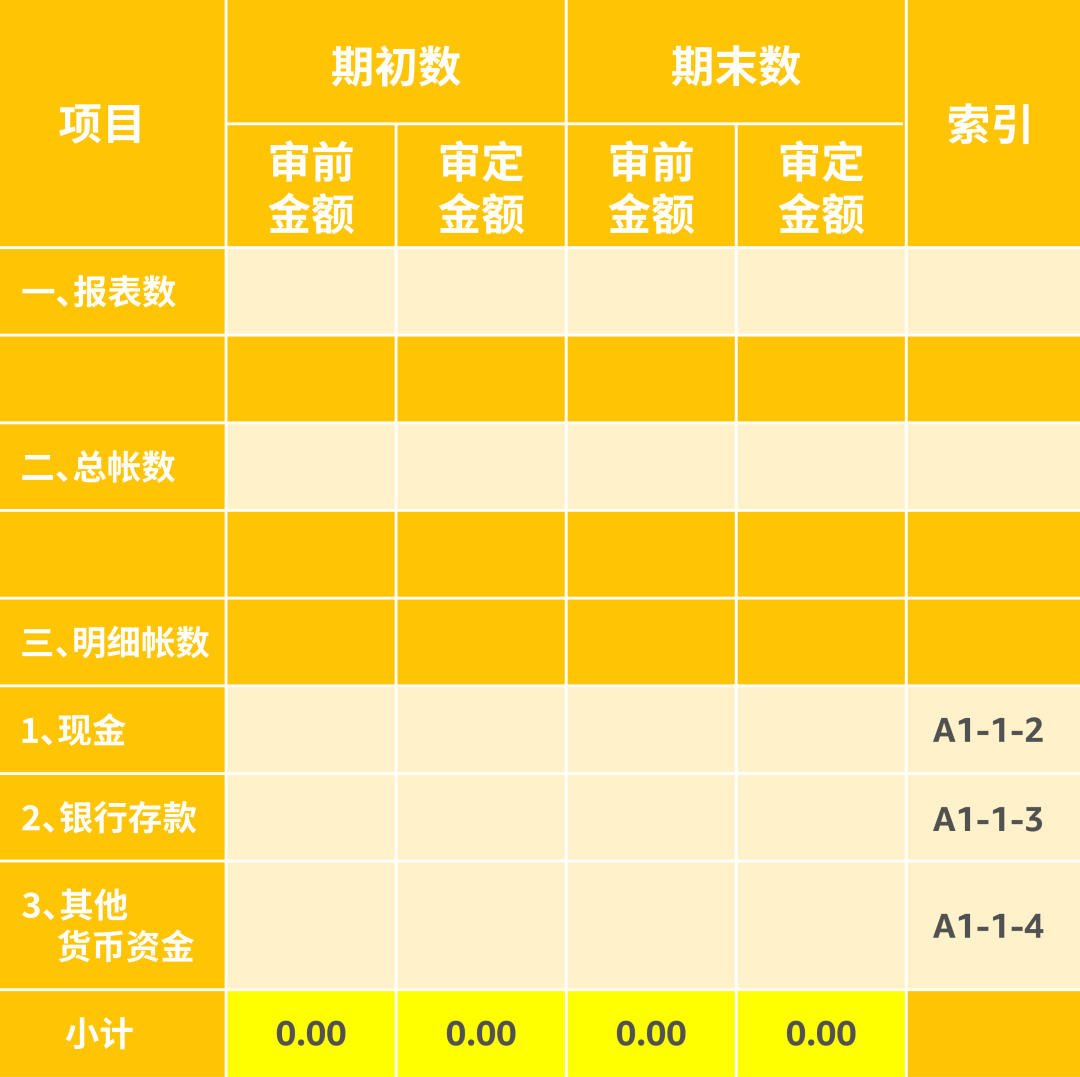
审计需要从多个表中查询货币相关列,生成以下格式的货币资金审定余额表。
配置MCP Server参考之前章节,开始Agent应用交互。
提示词如下。
目录下有三个excel文件。标准库包括财务信息需要的表,底稿视图表示根据标准库取出相关数据后生成的用于审计的表。取数逻辑表示,从标准库的相关表的相关列,查询得到数据后,写入底稿视图对应的表。例如,取数逻辑中的余额表,字段“期初数_本位币_现金”,数据来源表1:会计科目表,数据来源表字段:会计科目名称,搜索值:现金。数据来源表2:科目余额及发生额表,数据来源表字段:期初记账本位币余额。这两个字段构成了字段”期初数_本位币_现金”。需要:1,根据标准库构造Mysql表,生成测试数据。2.根据取数逻辑生成SQL,查询相关表数据,并把结果写入底稿视图相关表。
输出结果如下。
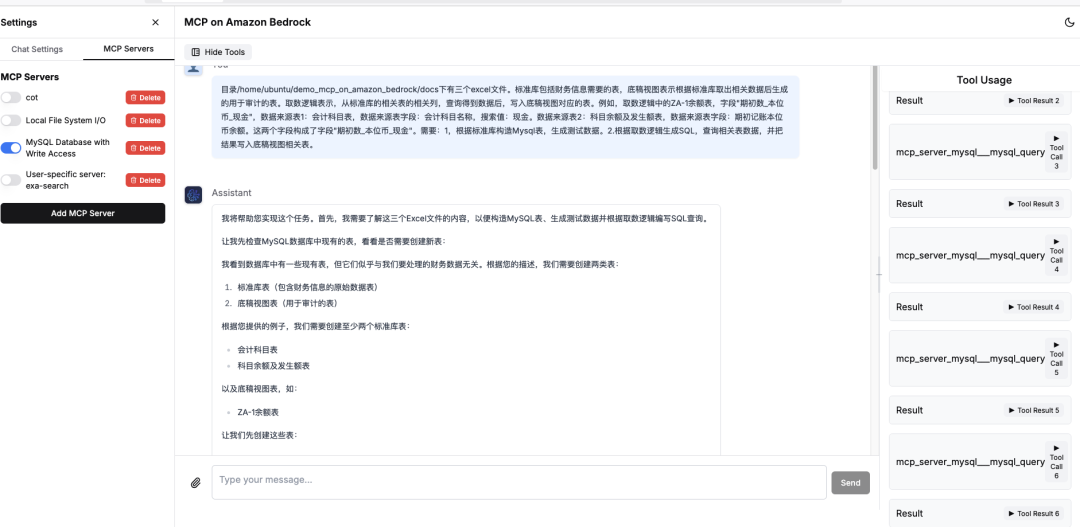
此过程中,已经存在了包含原始数据的Excel文件,定义了源数据格式,进行转换后,形成最终统一的审计表。查看执行过程,依次调用MCP工具,访问文件,生成SQL处理数据。每个工具调用,会按照上次的工具调用结果,来构建下一个工具调用。
例如,根据文件内容,构建原始表结构,再以此构建INSERT SELECT JOIN语句写入审计目标表。所有数据写入之后,以自然语言查询数据。
整个流程全部自动编排,即使遇到错误,也会自动处理。借助大模型的能力,可以很好理解审计人员的需求,构造审计所需要数据的专业SQL。对于业务人员,仅需要简单的交互,即可获得所需要的数据。
需要注意的是,审计可能会包含公司敏感数据,不允许直接调用大模型。可以考虑云上私有化部署模型,需要GPU,这相对于按token收费的直接访问模型服务,成本相对较高。
或者把数据预处理,只让大模型处理不含敏感信息的表头,生成转换Excel到csv的程序和SQL语句,需要访问数据库时,再根据之前生成的语句手工执行。这样既解决了数据敏感问题,又降低了调用大模型的token。
总结
MCP+数据库扩展了大模型的数据访问能力,实现数据全流程自动处理,工具调用自我迭代,只需提出业务需求即可得到结果。
相比传统编程数据库访问方式,无需手工编写SQL和处理执行结果,极大提高效率。
结合各种MCP Server,实现多种应用场景。包括:
AI工具助手
网站前后端开发
广告投放优化
基于爬虫+数据库的市场分析
作为RAG知识库补充,理解自然语言进行精确查询查询,结合内部和外部数据使用
审计数据处理:从Excel、CRM、PDF等多种数据源整理到统一格式数据库,并编写SQL访问语句
AI自动化数据库调优运维
更多MCP结合数据库使用的场景,仍在持续探索。在Agentic AI落地开花的趋势中,需要在业务中不断探索实践如何更智能处理数据。
本篇作者

章平
亚马逊云科技数据库架构师。2014年起就职于亚马逊云科技,先后加入技术支持和解决方案团队,致力于客户业务在云上高效落地。对于各类云计算产品和技术,特别是在数据库和大数据方面,拥有丰富的技术实践和行业解决方案经验。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9520
9520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









