






线性回归是预测连续结果的关键数据科学工具。本指南解释了它的原则、用途以及如何使用真实数据在 Python 中实现它。它涵盖了简单线性回归和多元线性回归,重点介绍了它们的重要性、局限性和实际示例。
在本文中,您将了解线性回归,这是机器学习中的一个关键概念。我们将探讨什么是线性回归,它如何作为线性回归模型,以及它在基于数据关系预测结果中的应用。
学习目标
• 了解线性回归的原理和应用。
• 区分简单线性回归和多元线性回归。
• 了解如何在 Python 中实现简单线性回归。
• 掌握梯度下降的概念及其在优化线性回归中的用途。
• 探索用于评估回归模型的评估指标。
• 识别线性回归中的假设和潜在陷阱,例如过度拟合和多重共线性。
什么是线性回归?
线性回归通过假设两个变量具有直线连接来预测它们之间的关系。它找到使预测值和实际值之间的差异最小的最佳线。它用于经济和金融等领域,有助于分析和预测数据趋势。线性回归也可以涉及多个变量(多元线性回归)或适用于是/否问题(逻辑回归)。
简单线性回归
在简单线性回归中,有一个自变量和一个因变量。该模型估计最佳拟合线的斜率和截距,它表示变量之间的关系。斜率表示自变量中每个单位变化的因变量变化,而截距表示自变量为零时因变量的预测值。
线性回归是一种安静且最简单的统计回归技术,用于机器学习中的预测分析。它显示了自(预测)变量(即 X 轴)和因(输出)变量(即 Y 轴)之间的线性关系,称为线性回归。如果存在单个输入变量 X(自变量),则此类线性回归是简单线性回归。

上图显示了 output(y) 和 predictor(X) 变量之间的线性关系。蓝色线称为最佳拟合直线。根据给定的数据点,我们尝试绘制一条最适合这些点的线。
简单回归计算
为了计算最佳拟合线,线性回归使用传统的斜率截距形式,如下所示:
Y i = β 0 + β 1 X i
其中 Y i = 因变量,β 0 = 常数/截距,β 1 = 斜率/截距,X i = 自变量。
此算法使用直线 Y= B 0 + B 1 X 解释因(输出)变量 y 和自(预测变量)变量 X 之间的线性关系。
但是回归如何找出哪条线是最合适的线呢?
线性回归算法的目标是获取 B 0 和 B 1 的最佳值,以找到最佳拟合线。最佳拟合线是误差最小的线,这意味着预测值和实际值之间的误差应该最小。
但是线性回归如何找出哪条线是最好的呢?
线性回归算法的目标是获取B 的最佳值0和 B1以找到最佳拟合线。最佳拟合线是误差最小的线,这意味着预测值和实际值之间的误差应该最小。
随机误差(残差)
在回归中,因变量的观测值 (y i ) 与预测值 (预测) 之间的差值称为残差。
ε I = Y 预测 – Y I
其中 y 预测 = B 0 + B 1 X i
什么是最佳拟合线?
简单来说,最佳拟合线是最适合给定散点图的线。从数学上讲,您可以通过最小化残差平方和 (RSS) 来获得最佳拟合线。
线性回归的 Cost 函数
成本函数有助于计算出 B 0 和 B 1 的最佳值,从而为数据点提供最佳拟合线。
在线性回归中,通常使用均值平方Error (MSE) 成本函数,即 y 预测值与 y i 之间发生的平均平方误差。
我们使用简单的线性方程 y=mx+b 计算 MSE:
使用 MSE 函数,我们将更新 B 0 和 B 1 的值,以便 MSE 值稳定在最小值。可以使用梯度下降法确定这些参数,以使成本函数的值最小。
线性回归的梯度下降
梯度下降 (Gradient Descent) 是一种优化算法,可优化成本函数 (目标函数) 以达到最佳最小解。为了找到最佳解决方案,我们需要降低所有数据点的成本函数 (MSE)。这是通过迭代更新斜率系数 (B1) 和常数系数 (B0) 的值来完成的,直到我们得到线性函数的最佳解。
回归模型通过随机选择系数值来减少成本函数,然后迭代更新系数值以达到最小成本函数,从而优化梯度下降算法以更新线的系数。
梯度下降示例
让我们举个例子来理解这一点。想象一个 U 形坑。你站在坑的最高点,你的动机是到达坑底。假设坑底有个宝藏,您只能走不连续的步数才能到达底部。如果您选择一次迈出一步,您最终会到达坑底,但这需要更长的时间。如果您决定每次都采取更大的步骤,您可能会更快地到达底部,但是,您有可能超过坑底,甚至不会接近底部。在 gradient descent 算法中,您采取的步数可以被视为学习率,这决定了算法收敛到最小值的速度。
为了更新 B 0 和 B 1,我们从成本函数中获取梯度。为了找到这些梯度,我们对 B 0 和 B 1 进行偏导数。
我们需要最小化成本函数 J。实现此目的的方法之一是应用批量梯度下降算法。在 batch gradient descent 中,值在每次迭代中更新。(最后两个方程显示了值的更新)
部分导数是梯度,它们用于更新 B 0 和 B 1 的值。Alpha 是学习率。
为什么线性回归很重要?
线性回归很重要,原因如下:
• 简单性和可解释性:这是一个相对容易理解和应用的概念。生成的简单线性回归模型是一个简单的方程,用于显示一个变量如何影响另一个变量。与更复杂的模型相比,这使得更容易解释和信任结果。
• 预测:线性回归允许您根据现有数据预测未来值。例如,您可以使用它来根据营销支出预测销售额或根据平方英尺预测房价。
• 其他技术的基础:它是许多其他数据科学和机器学习方法的构建块。即使是复杂的算法也经常依赖线性回归作为起点或用于比较目的。
• 广泛的适用性:线性回归可用于各个领域,从金融和经济学到科学和社会科学。它是一个多功能工具,用于揭示许多实际场景中变量之间的关系。
从本质上讲,线性回归为理解数据和进行预测提供了坚实的基础。这是一项为更高级的数据分析方法铺平道路的基础技术。
线性回归的评估指标
任何线性回归模型的强度都可以使用各种评估指标进行评估。这些评估指标通常用于衡量模型生成观察到的输出的程度。
最常用的指标是
- 决定系数或 R 平方 (R2)
- 均方根误差 (RSME) 和残差标准误差 (RSE)
决定系数或 R 平方 (R2)
R 平方是一个数字,用于解释开发的模型解释/捕获的变异量。它总是在0和1之间。总体而言,R 平方的值越高,模型与数据的拟合就越好。
在数学上,它可以表示为,
R2= 1 – ( RSS/TSS )
• 残差平方和 (RSS) 定义为绘图/数据中每个数据点的残差平方和。它是预期和实际观测输出之间差值的度量。
• 总平方和 (TSS) 定义为数据点与响应变量平均值的误差之和。数学上 TSS 是,
其中 y hat 是样本数据点的平均值。
R 平方的显著性如下图所示,
均方根误差
均方根误差是残差方差的平方根。它指定模型与数据的绝对拟合度,即观察到的数据点与预测值的接近程度。在数学上,它可以表示为,
为了使此估计无偏,必须将残差的平方和除以自由度,而不是模型中数据点的总数。该术语称为残差标准误差 (RSE)。在数学上,它可以表示为,
R 平方是比 RSME 更好的度量。由于均方根误差的值取决于变量的单位(即它不是标准化的度量),因此它可以随着变量单位的变化而变化。
线性回归的假设
回归是一种参数方法,这意味着它对要分析的数据做出假设。要成功进行回归分析,必须验证以下假设。
-
残差的线性度:因变量和自变量之间需要存在线性关系。
-
残差的独立性: 误差项不应相互依赖(就像在时间序列数据中一样,其中下一个值依赖于前一个值)。残差项之间不应有关联。这种现象的缺失称为自相关。
错误项中不应有任何可见的模式。
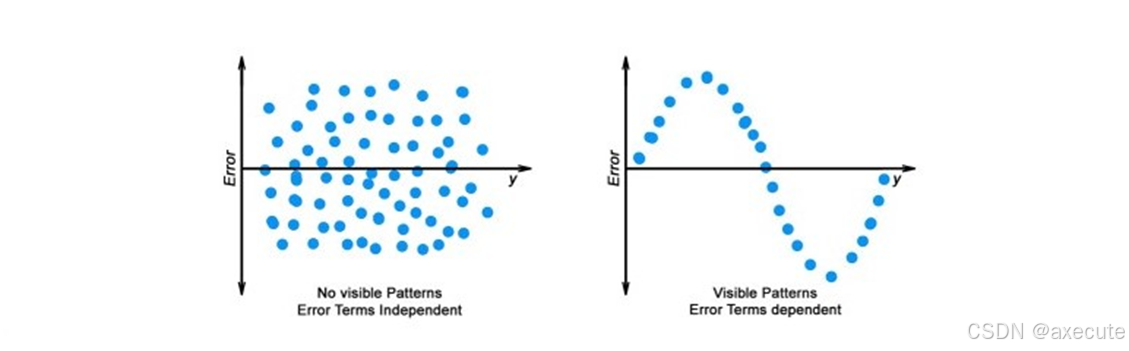
-
残差的正态分布:残差的均值应服从均值等于零或接近零的正态分布。这样做是为了检查所选行是否为最佳行。如果误差项是非正态分布的,则表明必须仔细研究一些不寻常的数据点才能制作出更好的模型。
-
残差的相等方差:误差项必须具有常数方差。这种现象被称为 Homoscedasticity。误差项中存在的非常量方差称为异方差。通常,在存在异常值或极端杠杆值时会出现非常量方差。
线性回归中的假设
在数据上拟合了一条直线后,您需要问:“这条直线是否与数据有显著的拟合?“或者”Is the beta coefficient explain the variance in the drawing data?”这就是对 beta 系数进行假设检验的想法。在这种情况下,Null 和 Alternate 假设是:
H 0 : B 1 = 0
H A : B 1 ≠ 0
为了检验这个假设,我们使用 t 检验,beta 系数的检验统计量由下式给出,
评估模型拟合
评估模型的其他一些参数是:
• t 统计量:它用于确定 p 值,因此有助于确定系数是否显着
• F 统计量:用于评估整体模型拟合是否显著。通常,F 统计量的值越高,模型就越显著。
多元线性回归
多元线性回归是一种用于理解单个因变量和多个自变量之间关系的技术。
多元线性回归的公式也类似于简单线性回归,其中
一个小的变化是,现在所有使用的变量都有 beta 值,而不是一个 beta 变量。公式为:
Y = B0+ B1X1+ B2X2+ … + BpXp + ε
多元线性回归的注意事项
为简单线性回归所做的所有四个假设仍然适用于多元线性回归,还有一些新的附加假设。
• 过拟合:当越来越多的变量被添加到模型中时,模型可能会变得过于复杂,并且通常最终会记住训练集中的所有数据点。这种现象称为模型过拟合。这通常会导致高训练精度和非常低的测试精度。
• 多重共线性:这是具有多个自变量的模型可能具有一些相互关联的变量的现象。
• 功能选择:随着变量的增加,从给定特征池(其中许多可能是多余的)中选择最佳预测因子集成为构建相关且更好的模型的重要任务。
多重共线性
由于多重共线性使得很难找出哪个变量对响应变量的预测有贡献,这会导致人们错误地得出变量对目标变量的影响的结论。虽然它不会影响模型预测的精度,但必须正确检测和处理模型中存在的多重共线性,因为从模型中随机删除任何这些相关变量都会导致系数值剧烈波动,甚至改变符号。
可以使用以下方法检测多重共线性。
• 成对相关:检查不同对自变量之间的成对相关性可以为检测多重共线性提供有用的见解。
• 方差膨胀因子 (VIF):成对关联可能并不总是有用的,因为只有一个变量可能无法完全解释其他变量,但一些组合的变量可能已经准备好执行此操作。因此,要检查变量之间的这些关系,可以使用 VIF。VIF 解释了一个自变量与所有其他自变量的关系。VIF 由下式给出,
其中 i 指的是 ith变量,它被表示为其余自变量的线性组合。
对于 VIF 值,通常遵循的启发式方法是,如果 VIF > 10,则该值很高,应将其删除。如果 VIF = 5,则它可能是有效的,但应首先检查。如果 VIF < 5,则认为它是一个不错的 VIF 值。
线性回归中的过拟合和欠拟合
总有一些情况是,模型在训练数据上表现良好,但在测试数据上表现不佳。虽然在数据集上训练模型,但过拟合和欠拟合是人们面临的最常见问题。
在理解过拟合和欠拟合之前,必须了解偏差和方差。
偏见
偏差是确定模型预测对未来未见数据的准确性的度量。假设有足够的训练数据可用,复杂模型可以做出准确的模型预测。而过于幼稚的模型很可能在模型预测方面表现不佳。简单地说,偏差是训练数据造成的错误。
通常,线性算法具有很高的偏差,这使得它们学习速度快,更容易理解,但一般来说,灵活性较低。这意味着对无法满足预期结果的复杂问题的预测性能较低。
方差
方差是模型对训练数据的敏感度,也就是说,它量化了当输入数据发生变化时模型的反应程度。
理想情况下,模型不应从一个训练数据集到下一个训练数据发生太大变化,这意味着该算法擅长挑选输入和输出变量之间隐藏的潜在模式。
理想情况下,模型应该具有较低的方差,这意味着模型在更改训练数据后不会发生剧烈变化(它是可推广的)。具有更高的方差将使模型发生巨大变化,即使训练数据集中的变化很小。
让我们了解什么是偏差-方差权衡。
偏差方差权衡
为了追求最佳性能,监督式机器学习算法寻求在低偏差和低方差之间取得平衡,以提高稳健性。
在机器学习领域,偏差和方差之间存在内在的关系,其特征是负相关。
• 偏差增加会导致方差减少。
• 相反,方差增加会导致偏倚减少。
在偏差和方差之间找到平衡点至关重要,算法必须驾驭这种权衡以获得最佳结果。
在实践中,由于基础目标函数的未知性,计算精确的偏差和方差误差项具有挑战性。
现在,让我们深入研究过拟合和欠拟合的细微差别。
过拟合
当模型学习数据中的每种模式和噪声,以至于影响模型在看不见的未来数据集上的性能时,它被称为过拟合。该模型与数据拟合得非常好,以至于它将噪声解释为数据中的模式。
当模型具有低偏差和较高方差时,它最终会记住数据并导致过拟合。过拟合会导致模型变得特定于模型,而不是通用模型。这通常会导致高训练精度和非常低的测试精度。
检测过拟合很有用,但它并不能解决实际问题。有几种方法可以防止过拟合,如下所述:
• 交叉验证
• 如果训练数据太小而无法训练,请添加更多相关且干净的数据。
• 如果训练数据太大,请进行一些特征选择并删除不必要的特征。
• 正规化
欠拟合
欠拟合的讨论频率不如讨论过拟合的次数多。当模型无法从训练数据集中学习并且也无法泛化测试数据集时,称为欠拟合。性能指标可以很容易地检测到此类问题。
当模型具有高偏差和低方差时,它最终不会泛化数据并导致欠拟合。它无法在数据中找到隐藏的基础模式。这通常会导致训练准确率低和测试准确率非常低。防止欠拟合的方法如下:
• 增加模型复杂性
• 增加训练数据中的特征数量
• 从数据中去除噪音。
动手编码:线性回归模型
在本节中,您将了解如何在 Python 中执行回归。我们将使用 Advertising 销售渠道预测数据。您可以在此处访问数据。
电视 收音机 报纸 销售
230.1 37.8 69.2 22.1
44.5 39.3 45.1 10.4
17.2 45.9 69.3 12.0
151.5 41.3 58.5 16.5
180.8 10.8 58.4 17.9
8.7 48.9 75.0 7.2
57.5 32.8 23.5 11.8
‘Sales’ 是需要预测的目标变量。现在,根据这些数据,我们的目标是创建一个预测模型,该模型根据在不同营销平台上花费的资金来预测销售额。
让我们直接进行一些动手编码来完成这个预测。如果您没有 Python 经验,请不要感到被忽视。最好的学习方法是通过解决问题来动手解决问题 – 就像我们正在做的问题一样。
第 1 步:导入 Python 库
第一步是启动 Jupyter 笔记本并在 Jupyter 笔记本中加载所有必备库。以下是我们线性回归所需的重要库。
• NumPy (执行某些数学运算)
• pandas (将数据存储在 pandas DataFrame 中)
• matplotlib.pyplot (您将使用 matplotlib 绘制数据)
为了加载这些代码,只需从第一个单元格中的这几行代码开始:
#Importing all the necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Supress Warnings
import warnings
warnings.filterwarnings('ignore')
最后一行代码有助于抑制不必要的警告。
步骤 2:加载数据集
现在让我们将数据导入 DataFrame。DataFrame 是 Python 中的一种数据类型。理解它的最简单方法是它以表格格式存储您的所有数据。
#Read the given CSV file, and view some sample records
advertising = pd.read_csv( "advertising.csv" )
advertising.head()
第 3 步:可视化
让我们在单个图中绘制目标变量与预测变量的散点图,以获得直觉。此外,为所有变量绘制热图
#Importing seaborn library for visualizations
import seaborn as sns
#to plot all the scatterplots in a single plot
sns.pairplot(advertising, x_vars=[ 'TV', ' Newspaper.,'Radio' ], y_vars = 'Sales', size = 4, kind = 'scatter' )
plt.show()
#To plot heatmap to find out correlations
sns.heamap( advertising.corr(), cmap = 'YlGnBl', annot = True )
plt.show()
从散点图和热图中,我们可以观察到“Sales”和“TV”与其他图表相比具有更高的相关性,因为它在散点图中显示出线性模式,并且给出了 0.9 的相关性。
您可以继续使用可视化效果,并从数据中发现有趣的见解。
第 4 步:执行简单线性回归
在这里,由于 TV 和 Sales 具有较高的相关性,我们将对这些变量执行简单线性回归。
我们可以使用 sklearn 或 statsmodels 来应用线性回归。因此,我们将继续使用 statmodels。
在本例中,我们首先将特征变量 ‘TV’ 分配给变量 ‘X’,将响应变量 ‘Sales’ 分配给变量 ‘y’。
X = advertising[ ‘TV’ ]
y = advertising[ ‘Sales’ ]
分配变量后,您需要将变量拆分为训练集和测试集。您将通过从库中导入来执行此操作。通常,最好将 70% 的数据保留在训练数据集中,将其余 30% 的数据保留在测试数据集中。
train_test_splitsklearn.model_selection
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, train_size = 0.7, test_size = 0.3, random_state = 100 )
通过这种方式,您可以将数据拆分为 train 集和测试集。
可以使用以下代码检查训练集和测试集的形状,
print( X_train.shape )
print( X_test.shape )
print( y_train.shape )
print( y_test.shape )
导入 statModels 库以执行线性回归
import statsmodels.api as sm
默认情况下,该库在数据集上拟合一条穿过原点的线。但是为了获得截距,您需要手动使用 的属性。将常量添加到数据集后,您可以继续使用 (Ordinary Least Squares) 的属性拟合回归线,如下所示,statsmodelsadd_constantstatsmodelsX_trainOLSstatsmodels
# Add a constant to get an intercept
X_train_sm = sm.add_constant(X_train)
# Fit the resgression line using 'OLS'
lr = sm.OLS(y_train, X_train_sm).fit()
可以使用以下代码查看 beta 的值,
# Print the parameters,i.e. intercept and slope of the regression line obtained
lr.params
其中,6.948 是截距,0.0545 是变量 TV 的斜率。
现在,让我们看看这个线性回归操作的评估指标。您可以简单地使用以下代码查看摘要,
#Performing a summary operation lists out all different parameters of the regression line fitted
print(lr.summary())
总结
如您所见,此代码为您提供了线性回归的简要摘要。以下是摘要中的一些关键统计数据:
- TV 的系数为 0.054,p 值非常低。该系数具有统计意义。因此,这种关联并非纯粹是偶然的。
- R – 平方为 0.816这意味着“Sales”中 81.6% 的方差由 “TV” 解释。这是一个不错的 R 平方值。
- F 统计量的 p 值非常低(实际上很低)。这意味着模型拟合在统计意义上显著,并且解释的方差并非纯粹是偶然的。
查看这篇关于不同类型的回归模型的文章
步骤 5:对测试集执行预测
现在,您已经简单地在训练数据集上拟合了一条回归线,是时候对测试数据进行一些预测了。为此,您首先需要像 for 一样向数据中添加一个常数,然后您可以简单地继续使用拟合回归线的属性来预测对应的 y 值。
X_testX_trainX_testpredict
# Add a constant to X_test
X_test_sm = sm.add_constant(X_test)
# Predict the y values corresponding to X_test_sm
y_pred = lr.predict(X_test_sm)
您可以使用以下代码查看预测值,
y_pred.head()
为了检查测试数据对值的预测效果,我们将使用 sklearn 库检查一些评估指标。
#Imporitng libraries
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
#RMSE value
print( "RMSE: ",np.sqrt( mean_squared_error( y_test, y_pred ) )
#R-squared value
print( "R-squared: ",r2_score( y_test, y_pred ) )
我们在训练集和测试集上都获得了不错的分数。
除了 ‘statsmodels’,还有另一个包,即 ‘sklearn’,可用于执行线性回归。我们将使用 ‘sklearn’ 中的 ‘linear_model’ 库来构建模型。由于我们已经执行了 train-test 拆分,因此无需再次执行。
不过,我们需要补充一小步。当只有一个特征时,我们需要添加一个额外的列,以便成功执行线性回归拟合。代码如下,
X_train_lm = X_train_lm.values.reshape(-1,1)
X_test_lm = X_test_lm.values.reshape(-1,1)
可以检查上述数据帧的形状变化。
print(X_train_lm.shape)
print(X_train_lm.shape)
要适应模型,请编写以下代码
from sklearn.linear_model import LinearRegression
#Representing LinearRegression as lr (creating LinearRegression object)
lr = LinearRegression()
#Fit the model using lr.fit()
lr.fit( X_train_lm , y_train_lm )
您可以使用以下代码通过 sklearn 获取截距和斜率值,
#get intercept
print( lr.intercept_ )
#get slope
print( lr.coef_ )
这就是我们执行简单线性回归的方法。
结论
总之,线性回归是数据科学的基石,为预测连续结果提供了一个强大的框架。随着我们解开它的复杂性和应用,很明显线性回归统计是一种具有广泛影响的多功能工具。本文是一份全面的指南,介绍了它在 Python 中对关系进行建模中的作用和实际实现。
对于那些渴望深入研究数据科学和机器学习世界的人来说,Analytics Vidhya的AI & ML BlackBelt+计划提供了一种沉浸式的学习体验。通过指导和实践项目提升您的技能并驾驭不断发展的数据科学领域。立即加入 BB+,解锁数据科学之旅的新阶段!
希望你喜欢这篇文章,你会发现线性回归是机器学习中的一个基本概念。线性回归模型通过分析变量之间的关系来预测结果。什么是线性回归?这是一种用于对因变量与一个或多个自变量之间的关系进行建模的技术。
关键要点
• 线性回归通过拟合一条使预测误差最小化的线来预测变量之间的关系。
• 简单线性回归涉及一个预测变量和一个结果变量,而多元线性回归包括多个预测变量。
• 成本函数(通常使用梯度下降法进行最小化)确定线性回归中的最佳拟合线。
• R 平方和 RMSE 等评估指标衡量模型的性能和拟合度。
• 线性、独立性、正态分布和残差常数方差等假设对于有效的回归分析至关重要。
• 适当的特征选择和验证技术有助于减少回归模型中的过拟合和多重共线性。
常见问题解答
问题 1.线性回归的参数是什么?
答:线性回归有两个主要参数:斜率(权重)和截距。斜率表示自变量中单位变化的因变量的变化。截距是自变量为零时因变量的值。目标是找到使预测值和实际值之间的差异最小的最佳拟合线。
问题 2.线性回归线的公式是什么?
一个。线性回归方程的公式为:
y = mx + b
其中 y 是因变量,x 是自变量,m 是斜率(权重),b 是截距。它表示通过最小化实际值和预测值之间的平方差来描述变量之间关系的最佳拟合直线。
问题 3.线性回归的应用是什么?
答:线性回归用于统计、经济学、金融学等领域,以分析变量之间的关系。例如,我在金融领域预测股票价格,或者在营销领域研究广告对销售的影响。一个基本示例涉及根据身高预测体重,其中使用线性方程根据身高数据估计体重。
问题 4.什么是线性回归的基本例子?
一个。一个基本的线性回归示例涉及根据身高预测一个人的体重。在这种情况下,身高是自变量,而体重是因变量。身高和体重之间的关系使用简单的线性方程进行建模,其中体重估计为身高的函数。
问题 5.什么是线性回归算法?
A. 线性回归通过拟合一条直线来预测变量之间的关系,该直线使预测值和实际值之间的差异最小。它分析和预测数据趋势。
最后附一个线性回归计算器:
https://www.graphpad.com/quickcalcs/linear1/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









