







一、elasticsearch聚合语法
#其中的aggs为aggregations缩写形式,两种都可以。
GET /goods/_search
{
"query": {
"这是你的查询条件"
},
"aggs": {
"聚合名称": {
"聚合方式": {
"field": "字段"
}
}
}
}单个聚合
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-avg-aggs": {
"avg": {
"field": "skuPrice"
}
}
}
}多个聚合
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-avg-aggs": {
"avg": {
"field": "skuPrice"
}
},
"skuprice-sum-aggs": {
"sum": {
"field": "skuPrice"
}
}
}
}嵌套聚合
GET /goods/_search
{
"size": 0,
"aggs": {
"category-aggs": {
"terms": {
"field": "catagoryName.keyword"
},
"aggs": {
"brands-aggs": {
"terms": {
"field": "brandName.keyword"
}
}
}
}
}
}
二、elasticsearch聚合类型
有三种常用类型:metrics,buckets和pipeline
三、elasticsearch metrics 介绍,主要是计算数值类型
| avg | 单值聚合。计算数值的平均值。 |
| sum | 单值聚合。计算数值的和。 |
| min | 单值聚合。计算数值的最小值。 |
| max | 单值聚合。计算数值的最大值。 |
| stats | 多值聚合。计算的结果中包含min,max,sum,count和avg |
| extended_stats | 多值聚合,计算的结果中除了包含stats有的,还包含sum_of_squqres,variance,std_deviation和std_deviation_bounds |
| value_count | 单值聚合。用于统计文档值的个数,不会忽略重复值,重复值也会计算在内。 |
| cardinality | 单值聚合。计算不同值的个数。 |
| percentiles | 多值聚合。计算数值类型的一个或者多个百分比值。默认返回的是[1,5,25,50,75,95,99]对应的百分位数。 |
| percentile_ranks | 多值聚合,计算数值类型的一个或者多个百分排名 |
| top_hits | 跟踪最相关的文档。此聚合器目的是作为子聚合器,为了每个bucket来聚合最匹配文档。不建议top_hits作为最外层聚合。 |
| geo_bounds | 计算包含所有地理位置值的边界框 |
| scripted_metric | 执行脚本提供度量输出 |
1. avg ,求skuPrice的平均值,为了方便查看聚合结果,设置size为0
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-avg-aggs": {
"avg": {
"field": "skuPrice"
}
}
}
}聚合结果在aggregations下,对应的你命名的aggs
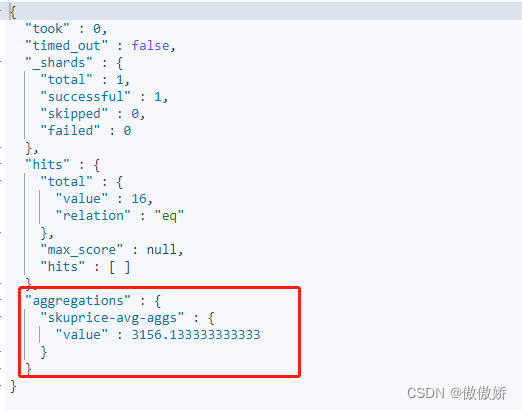
2. sum 计算skuPrice的和
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-sum-aggs":{
"sum": {
"field": "skuPrice"
}
}
}
}3. min 计算最小的skuPrice的值
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-min-aggs":{
"min": {
"field": "skuPrice"
}
}
}
}4. max 计算最大的skuPrice值
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-max-aggs":{
"max": {
"field": "skuPrice"
}
}
}
}5. stats
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-stats-aggs":{
"stats": {
"field": "skuPrice"
}
}
}
}结果为sum,min,max,avg,count

6. extend_stats
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-extend_stats-aggs":{
"extended_stats": {
"field": "skuPrice"
}
}
}
}
结果为除了stats之外的其他数值指标
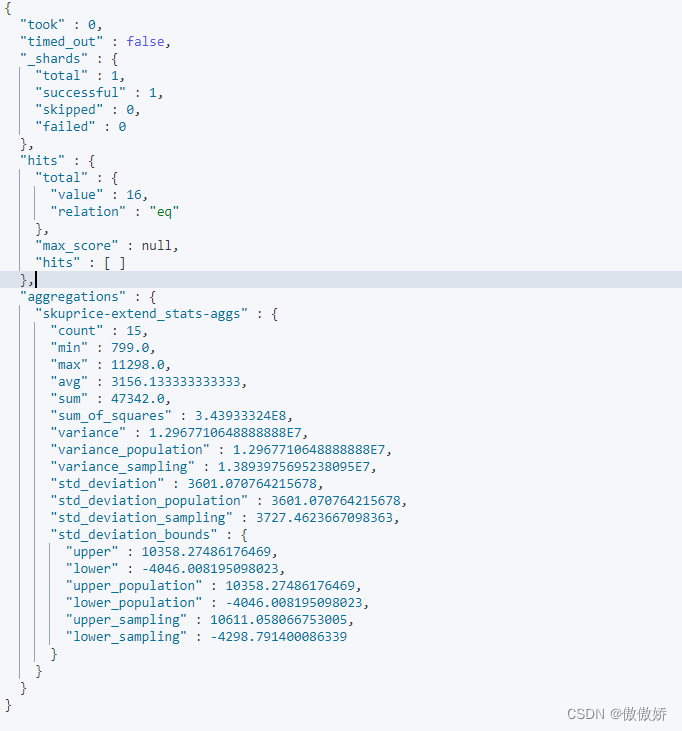
7. value_count 返回skuPrice记录数
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-value_count-aggs":{
"value_count": {
"field": "skuPrice"
}
}
}
}
8. cardinality 得到skuPrice不同的个数
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-cardinality-aggs":{
"cardinality": {
"field": "skuPrice"
}
}
}
}9. percentiles
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-percentiles-aggs":{
"percentiles": {
"field": "skuPrice"
}
}
}
}结果如下
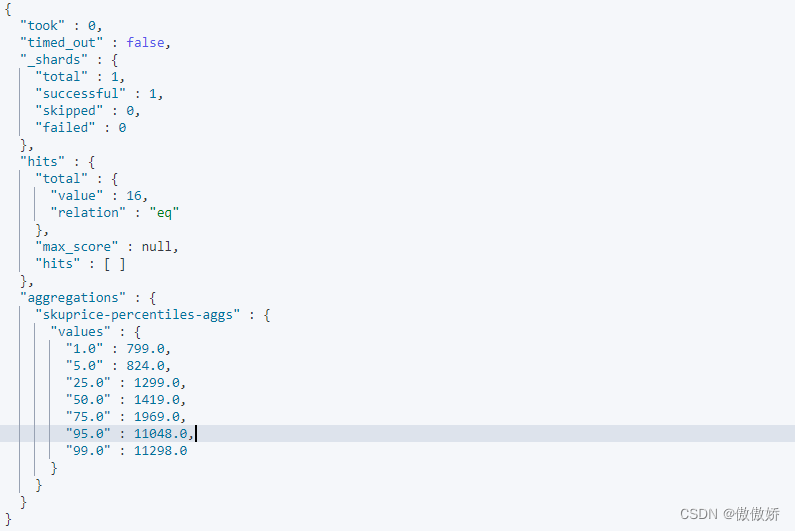
10. percentile_rank
GET /goods/_search
{
"size": 0,
"aggs": {
"skuprice-percentile_ranks-aggs":{
"percentile_ranks": {
"field": "skuPrice",
"values": [
799,
1419,
11298
]
}
}
}
}四、elasticsearch buckets 介绍
| filter | 在当前的文档集合上下文中定义一个匹配指定过滤器的所有文档bucket。通过用于减小当前聚合上下文到一个指定的文档集合中。 |
| filters | 定义多个bucket聚合,每个bucket与一个过滤器匹配。每个bucket收集匹配相关的过滤器的文档。 |
| terms | 基于源的多个bucket值的聚合,每个bucket是动态创建的,每个是唯一值。 |
| range | 基于源的多个bucket值的聚合,通过from,to定义区间范围,to值不包含 |
| date_range | 用于日期值的区间聚合,与range的区别在于from,to的值可以使用日期数学表达式计算的值。 |
| ip_range | 与date_range相似,专门用于ip地址的。除了from,to来定义区间,也可以使用mask来定义 |
| missing | 单个bucket聚合。在缺少字段值时在当前的文档上下文中创建所有文档的一个bucket。 |
| histogram | 多个bucket值的聚合,应用于数值。 |
| date_histogram | 与histogram相似,用于日期类型数据 |
| geo_distance | 多bucket聚合,用于geo_point类型字段,与range相似。 |
| geohash_grid | 多bucket聚合,根据geo_point和geo_shape值分组到表示网格的bucket中。 |
| global | 定义在搜索执行上下文内所有文档的一个bucket. |
| significant_terms | 返回感兴趣的或者经常出现的词条。 |
| sampler | 用于限制子聚合处理最高分文档的采样。 |
| children | 一个特殊的单bucket聚合。选择指定类型,在join字段中定义的子文档。 |
| nested | 一个特殊的单bucket聚合,使得能够聚合嵌套文档。 |
| reverse_nested | 一个特殊的单bucket聚合,在嵌套文档中聚合父文档。必须定义在nested聚合中 |
1. filter 过滤,这里将hasStock为true的分到同一个bucket中
GET /goods/_search
{
"size": 0,
"aggs": {
"filter-aggs": {
"filter": {
"match":{
"hasStock":true
}
}
}
}
}
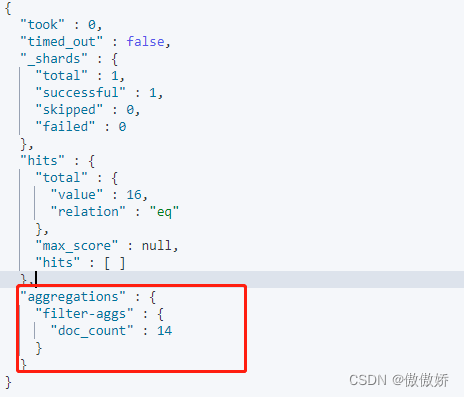
2. filters,分组
GET /goods/_search
{
"size": 0,
"aggs": {
"filters-aggs": {
"filters": {
"filters": {
"xiaomi": {
"match": {
"skuTitle": "小米"
}
},
"huawei": {
"match": {
"skuTitle": "华为"
}
}
}
}
}
}
}
结果如下
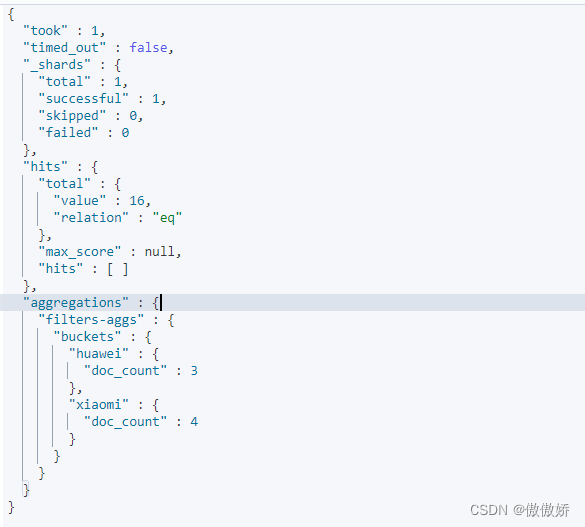
3. terms 根据brandName进行bucket统计
GET /goods/_search
{
"size": 0,
"aggs": {
"terms-aggs": {
"terms": {
"field": "brandName.keyword"
}
}
}
}结果如下,会将有多少个brandName统计出来
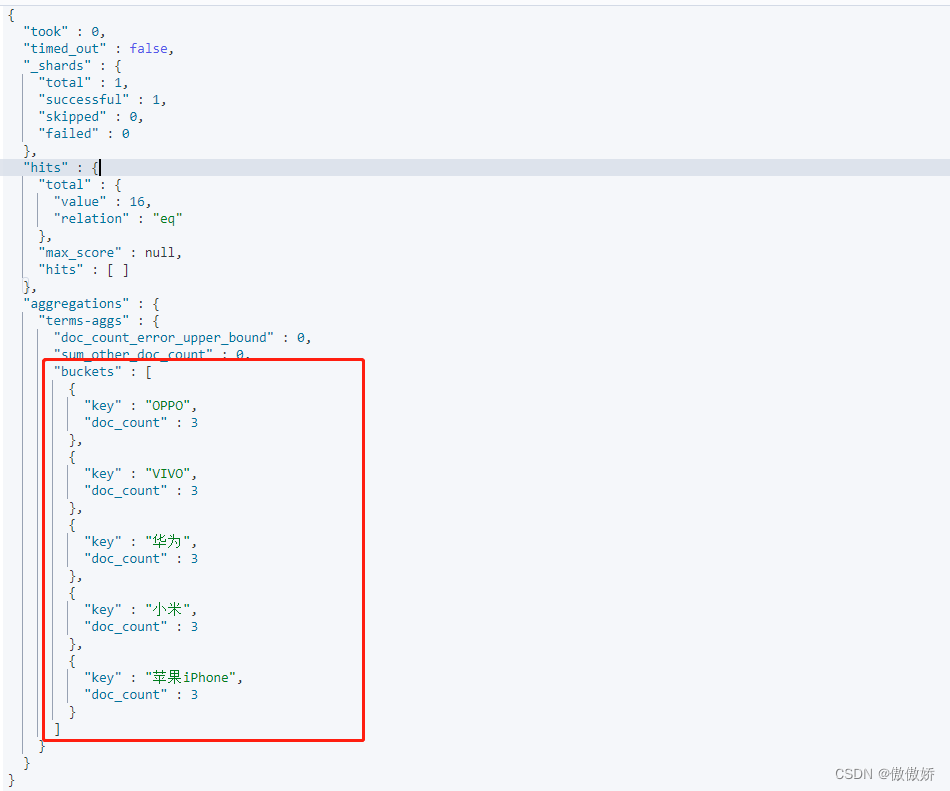
4. range 这里统计skuPrice从0到1000和1000到4000的数据统计,其中to的数值不包含在统计中。
GET /goods/_search
{
"size": 0,
"aggs": {
"range-aggs": {
"range": {
"field": "skuPrice",
"ranges": [
{
"from": 0,
"to": 1000
},
{
"from": 1000,
"to": 4000
}
]
}
}
}
}结果如下
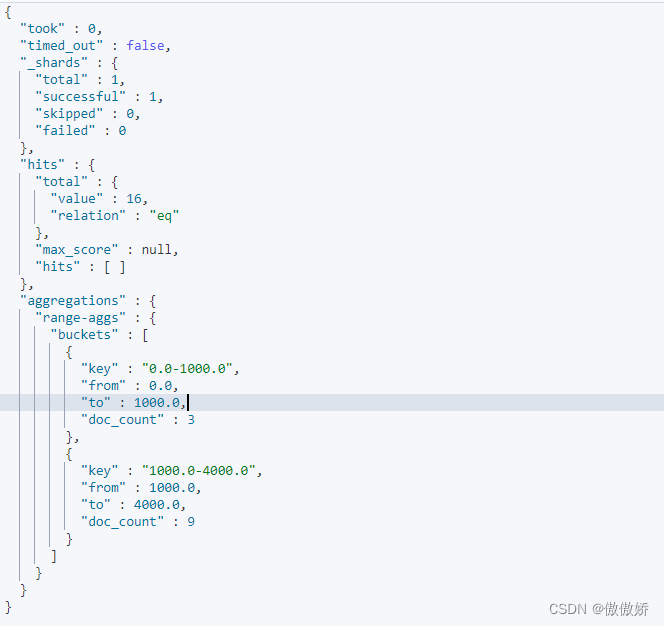
5. date_range
#创建一个日期索引
PUT /date-test-index
{
"mappings": {
"properties": {
"create_date":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
#插入一些数据
POST /date-test-index/_doc/1
{
"create_date":"2022-06-12 03:03:12"
}
POST /date-test-index/_doc/2
{
"create_date":"2022-08-20 03:03:12"
}
POST /date-test-index/_doc/3
{
"create_date":"2022-09-06 03:03:12"
}
POST /date-test-index/_doc/4
{
"create_date":"2022-08-30 03:03:12"
}from 为 now-10d/d to 为now,现在日期为2022-09-08
GET /date-test-index/_search
{
"size": 0,
"aggs": {
"date-aggs": {
"date_range": {
"field": "create_date",
"ranges": [
{
"from": "now-10d/d",
"to": "now"
}
]
}
}
}
}结果为:

6. missing 查看缺少这个字段的数据统计
GET /goods/_search
{
"size": 0,
"aggs": {
"missing-aggs": {
"missing": {
"field": "fee"
}
}
}
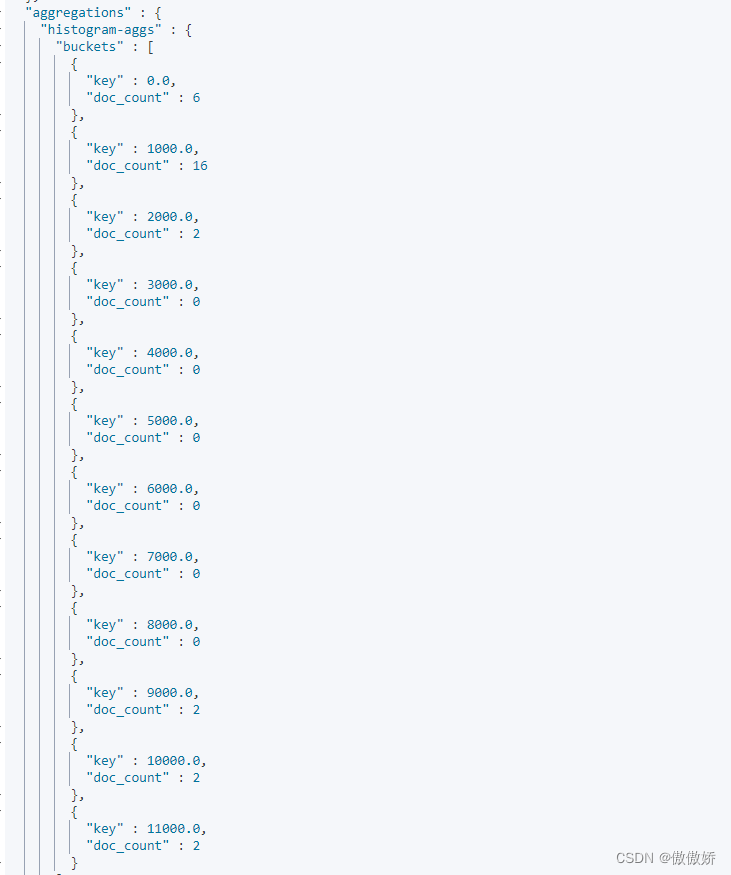
}7. histogram 统计skuPrice中数据个数,从最低的到最高的,间隔为interval的值
GET /goods/_search
{
"size": 0,
"aggs": {
"histogram-aggs": {
"histogram": {
"field": "skuPrice",
"interval": 1000
}
}
}
}
五、elasticsearch pipeline 介绍
1. 单层,先根据brandName聚合,并获取其中的saleCount的stats聚合结果,然后pipeline-max-salecount 根据buckets_path获取数据,同理,pipeline-min-salecount也一样
GET /goods/_search
{
"size": 0,
"aggs": {
"brand-aggs": {
"terms": {
"field": "brandName.keyword"
},
"aggs": {
"brand-stats-aggs": {
"stats": {
"field": "saleCount"
}
}
}
},
"pipeline-max-salecount":{
"max_bucket": {
"buckets_path": "brand-aggs>brand-stats-aggs.max"
}
},
"pipeline-min-salecount":{
"min_bucket": {
"buckets_path": "brand-aggs>brand-stats-aggs.min"
}
}
}
}2. 多层pipeline,这里是先把结果写道pipeline_catagory_brand_salecount_max中,然后外层pipeline_catagory_salecount_max根据buckets_path获取内层pipeline_catagory_brand_salecount_max的数据
GET goods/_search
{
"size": 0,
"aggs": {
"catagory-aggs": {
"terms": {
"field": "catagoryName.keyword"
},
"aggs": {
"brand-aggs": {
"terms": {
"field": "brandName.keyword"
},
"aggs": {
"stats-salecount-aggs": {
"stats": {
"field": "saleCount"
}
}
}
},
"pipeline_catagory_brand_salecount_max":
{
"max_bucket": {
"buckets_path": "brand-aggs>stats-salecount-aggs.max"
}
}
}
},
"pipeline_catagory_salecount_max":{
"max_bucket": {
"buckets_path": "catagory-aggs>pipeline_catagory_brand_salecount_max"
}
}
}
}3. 滑动聚合,必须和histogram聚合操作一起使用。
#moving_fn
GET /goods/_search
{
"size": 0,
"aggs": {
"histogram-aggs": {
"histogram": {
"field": "skuPrice",
"interval": 1000
},
"aggs": {
"sum-salecount": {
"sum": {
"field": "saleCount"
}
},
"pipeline-salecount-avg":{
"moving_fn": {
"buckets_path": "sum-salecount",
"window": 1000,
"script":"MovingFunctions.sum(values)"
}
}
}
}
}
}
# moving_avg 这个已经过期
GET /goods/_search
{
"size": 0,
"aggs": {
"histogram-aggs": {
"histogram": {
"field": "skuPrice",
"interval": 1000
},
"aggs": {
"sum-salecount": {
"sum": {
"field": "saleCount"
}
},
"pipeline-avg":{
"moving_avg": {
"buckets_path": "sum-salecount",
"window": 1000
}
}
}
}
}
}七、总结
elasticsearch的这种查询语法还是挺容易理解的,哈哈。
下一篇学习Java elasticsearch api的使用。















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









