







入门文章:
下面再对GFS读写文件做流程上的总结:
GFS读取文件的整个流程
Google 文件系统(GFS)是一个用于存储大规模数据的分布式文件系统。在GFS中,文件被划分成固定大小的块(chunk),并在多个存储节点上进行复制,以提供高可靠性和高性能的数据访问。下面是GFS读取文件的整个流程,包括与主节点(Master)的交互:
-
客户端请求读取文件:
- 客户端应用程序需要读取文件时,首先会发送一个读取文件的请求给GFS客户端。
-
客户端向Master查询文件位置:
- 客户端将文件名发送给GFS客户端。
- GFS客户端通过网络连接向GFS主节点(Master)发送文件位置查询请求。
-
Master返回文件块位置:
- GFS主节点(Master)收到文件位置查询请求后,会根据文件名查询文件的元数据,包括文件所包含的所有文件块以及它们的位置信息。
- Master返回文件块的位置信息给GFS客户端。
-
客户端选择可用的副本:
- GFS客户端收到文件块的位置信息后,会选择一个可用的文件块副本进行读取。通常选择距离最近或网络负载最轻的副本。
-
客户端向存储节点发送读取请求:
- GFS客户端通过网络连接向存储文件块副本的存储节点发送读取请求。
-
存储节点返回文件块内容:
- 存储文件块副本的存储节点收到读取请求后,会读取文件块的内容,并将其返回给GFS客户端。
-
客户端将文件块内容返回给应用程序:
- GFS客户端收到文件块的内容后,会将其返回给应用程序,完成文件读取操作。
在整个流程中,GFS主节点(Master)起到了协调作用,负责管理文件元数据,包括文件的位置信息等。客户端通过与GFS主节点的交互,获取文件的位置信息,并直接与存储文件块副本的存储节点通信进行文件读取操作。这种分布式的文件读取流程能够有效地提高文件读取的性能和可靠性。
写入文件的整个流程
以下是Google 文件系统(GFS)写入文件的整个流程,包括与主节点(Master)的交互:
-
客户端请求写入文件:
- 客户端应用程序需要写入文件时,首先会发送一个写入文件的请求给GFS客户端。
-
客户端向Master查询文件位置:
- 客户端将文件名发送给GFS客户端。
- GFS客户端通过网络连接向GFS主节点(Master)发送文件位置查询请求。
-
Master返回文件位置信息:
- GFS主节点(Master)收到文件位置查询请求后,根据文件名查询文件的元数据,包括文件所在的位置信息。
- Master返回文件的位置信息给GFS客户端。
-
客户端选择写入位置:
- GFS客户端收到文件位置信息后,会选择一个合适的位置进行文件写入。通常选择距离最近或网络负载最轻的存储节点进行写入。
-
客户端将文件划分成块并发送给存储节点:
- GFS客户端将待写入的文件划分成固定大小的块,并通过网络连接将这些块发送给选择的存储节点。
-
存储节点接收文件块并写入磁盘:
- 存储节点接收到文件块后,会将其写入本地磁盘,并确认写入操作的完成。
-
存储节点向Master报告写入完成:
- 存储节点完成文件块的写入后,会向GFS主节点(Master)发送写入完成的报告。
-
Master更新文件元数据:
- GFS主节点收到存储节点的写入完成报告后,会更新文件的元数据,包括文件的最新版本、文件块的位置等信息。
-
客户端写入完成:
- GFS客户端收到所有存储节点的写入完成报告后,表示文件写入操作完成。
在整个流程中,GFS主节点(Master)负责管理文件元数据,包括文件的位置信息等。客户端通过与GFS主节点的交互,获取文件的位置信息,并将文件块发送给存储节点进行写入操作。一旦所有存储节点完成了文件写入操作,并向主节点报告了写入完成,客户端便完成了文件写入操作。
待续
RocksDB—》以RcoksDB为例
预备知识:
IO速度比较: 磁盘随机IO << 磁盘顺序IO ≈ 内存随机IO << 内存顺序IO.
RocksDB使用Log-Structured Merge(LSM)trees做为基本的数据存储结构。下面来介绍LSM-Tree
LSM-Tree
LSM-Tree 的核心思想是利用顺序写来提升写性能; LSM-Tree 不是一种树状数据结构,仅仅是一种存储结构; LSM-Tree 是为了写密集型的特定场景而提出的解决方案;如日志系统、海量数据存储、数据分析;
LO 层数据重复,文件间无序,文件内部有序;
L1-LN 每层数据没有重复,跨层可能有重复;文件间是有序的;
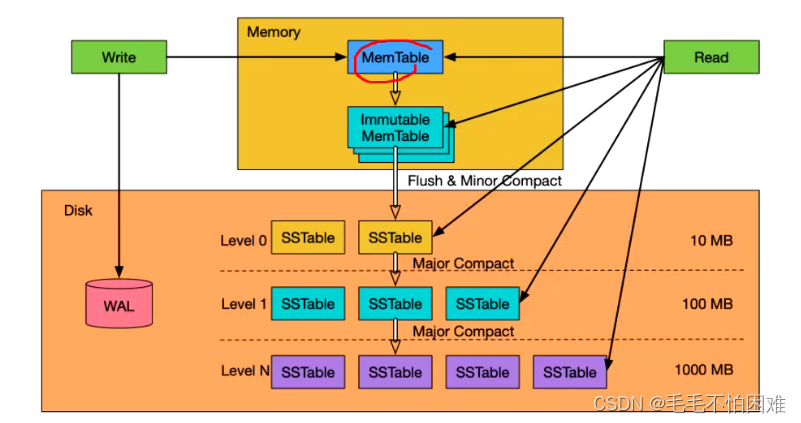
LSM写操作:
当进行写操作时,LSM-Tree通常会经历以下步骤:
-
内存表写入:
- 首先,写入的数据会被追加到内存中的Memtable中 + 磁盘中的WAL中(主要是为了防程序崩溃带来数据丢失)。Memtable是一个位于内存中的数据结构,用于暂时存储最新写入的数据。
-
内存表大小控制:
- 当Memtable达到一定大小或者一定时间间隔后,LSM-Tree会触发一次写入磁盘的操作,将Memtable中的数据转换为不可变的形式,成为Immutable Memtable,然后将其写入磁盘。这个过程称为"flush"。
-
磁盘写入:
- Immutable Memtable被写入磁盘后,称为一个SSTable(Sorted String Table)。SSTables是按照顺序排列的,包含了一批批有序的键值对。
-
合并操作:
- 写入过程中,可能会有多个SSTables存在于磁盘中。定期或根据一定的策略,LSM-Tree会执行合并操作,将多个SSTables合并成一个更大的SSTable。这个合并操作有助于减少磁盘上的碎片和提高读取效率。
-
Compaction过程:
- 合并操作的一种特殊形式是Compaction,它是将多个SSTables合并成一个新的SSTable的过程,同时删除重复的键值对和过期的数据。Compaction过程旨在维护LSM-Tree的性能和空间效率。
-
数据持久化:
- 写入到磁盘的数据是持久化的,确保即使系统重启,数据也不会丢失。
LSM读操作
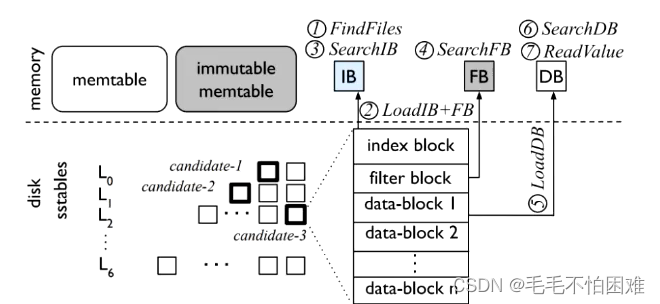
在进行读操作时,结合上图,LSM-Tree通常会经历以下步骤:
-
内存表(Memtable)读取:
- 首先,LSM-Tree会检查内存中的Memtable,这是一个位于内存中的数据结构,用于存储最新写入的数据。
- 如果读取请求的数据在Memtable中找到,则读取操作直接从Memtable中获取数据,跳过后续步骤,加快响应速度。
-
缓存(Cache)查询:
- 如果在Memtable中未找到所需数据,则LSM-Tree可能会查询缓存(如Bloom Filter)以检查所需数据是否可能存在于LSM-Tree的较低层次的磁盘存储结构中。Bloom Filter是一种快速的数据结构,用于判断一个元素是否可能存在于一个集合中,若可能存在,则进一步查询磁盘。
-
磁盘层次读取:
- 如果在缓存中未找到数据,LSM-Tree会依次查询磁盘上不同层次的存储结构,包括:
- Immutable Memtable:写入Memtable后,将其转换为不可变的形式,称为Immutable Memtable,如果数据不在当前的Memtable中,可能在Immutable Memtable中。
- SSTables(Sorted String Table):LSM-Tree将写入的数据批量转存到磁盘上的SSTables中,这些SSTables按照顺序排列,读取时可根据索引快速定位所需数据。
- Bloom Filters:可能会使用Bloom Filters来快速排除某些SSTables,避免不必要的磁盘访问。
- Merge Process:LSM-Tree可能会在查询时执行一些合并操作,将多个SSTables合并为一个更大的SSTable,以减少后续查询时需要访问的磁盘文件数目。
- 如果在缓存中未找到数据,LSM-Tree会依次查询磁盘上不同层次的存储结构,包括:
-
数据返回:
- 当找到所需数据时,LSM-Tree将其返回给调用者。
BlockCache
在LSM树(Log-Structured Merge-Tree)中,BlockCache是一个重要的组件,用于提高数据读取性能。LSM树通常用于键值存储系统,如LevelDB、RocksDB和Cassandra等,它们将数据存储在磁盘上的有序不可变文件中,这些文件通常被称为SSTables(Sorted String Tables)。
BlockCache的工作原理如下:
- 缓存机制:BlockCache缓存的是SSTable中的数据块(通常是连续的键值对序列)。当LSM树需要读取数据时,它会首先检查BlockCache,看所需的数据块是否已经被加载到内存中。如果数据块在缓存中,就直接从内存中读取,这比从磁盘读取要快得多。
- 读取优化:由于LSM树中的数据是分层和有序的,读取操作可能需要访问多个SSTable。BlockCache通过缓存热点数据块来减少磁盘I/O,从而加速读取操作。
- 写入和更新:当新的数据被写入LSM树时,可能会生成新的SSTable,或者更新现有的SSTable。在这个过程中,BlockCache可能需要更新或失效相应的缓存块,以确保缓存的一致性。
- 缓存策略:BlockCache通常使用一些缓存替换策略,如LRU(Least Recently Used)、LFU(Least Frequently Used)或ARC(Adaptive Replacement Cache)等,来决定哪些数据块应该被保留在缓存中,哪些应该被淘汰,以优化缓存的空间利用率和命中率。
- 内存管理:BlockCache的大小是有限制的,因为它占用的是宝贵的内存资源。系统管理员可以根据服务器的内存容量和工作负载来配置BlockCache的大小。
总的来说,BlockCache是LSM树中的一个关键组件,它通过缓存磁盘上的数据块来减少磁盘I/O,从而提高数据的读取性能。正确配置和管理BlockCache对于优化LSM树存储的性能至关重要。
其他
-
rocksDB是顺序写—> 追加更新,因此有数据冗余,后台线程不断地进行一个compaction的合并压缩操作。
-
LSM-Tree解决了什么问题?
通过放大读和写,来减少空间放大。即:读和写性能低一点,但是占用的空间少了。 -
Q: 对于LSMtree来说,每一个在磁盘中的SSTable都有一个对应的布隆过滤器对吗?每次先通过布隆过滤器来判断是否在当前这一块SSTABLE,不在就去判断下一块?我说的对吗,不对请指出?
A:对于LSM树(Log-Structured Merge-Tree)来说,布隆过滤器(Bloom Filter)是一种常用的优化技术,用于减少对磁盘上SSTable(Sorted String Table)的不必要读取。布隆过滤器是一种空间效率极高的数据结构,用于测试一个元素是否属于集合,它能够以很小的错误率返回“可能存在”或“肯定不存在”的答案。
在你的描述中,有一个基本的概念是对的:LSM树中的每个SSTable可以有一个对应的布隆过滤器。这个布隆过滤器会为SSTable中的每个键创建一个概率性的存在位序列,这样在查询时,如果布隆过滤器判断一个键不存在于某个SSTable中,那么这个SSTable就肯定不包含这个键,从而可以跳过对它的磁盘I/O操作。
但是,你的描述中有一些不准确的地方需要指出: -
并非所有的SSTable都会有一个布隆过滤器。在一些LSM树的实现中,布隆过滤器是可选的,并且可以根据数据集的大小、访问模式和工作负载来决定是否为每个SSTable创建布隆过滤器。在某些情况下,为了节省空间或计算资源,可能会选择不为某些SSTable创建布隆过滤器。
-
布隆过滤器的使用通常是在查询操作中。当进行键的查找时,LSM树会首先检查内存中的数据结构(如MemTable和Immutable MemTable),如果没有找到,则会按照SSTable的层次结构从新到旧逐个检查。在每个SSTable上,会先使用其布隆过滤器来判断键是否可能存在。如果布隆过滤器说“可能存在”,则实际读取SSTable以确认键的存在。如果布隆过滤器说“肯定不存在”,则可以跳过这个SSTable,继续检查下一个。
-
布隆过滤器可能会有误报(false positive),即它可能会错误地判断一个键存在于SSTable中,但实际上不存在。因此,布隆过滤器的“不存在”判断是确定的,而“存在”判断是概率性的。即使布隆过滤器显示键可能存在,也需要实际检查SSTable来验证。
-
布隆过滤器可用于在查询时候减少磁盘IO.
总结来说,布隆过滤器是LSM树中用来优化查询性能的一种工具,但它的使用是可选的,并且它的“不存在”判断是确定的,而“存在”判断是概率性的。在查询时,LSM树会逐个检查SSTable的布隆过滤器,以决定是否需要读取相应的SSTable。















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









