







 本文介绍了中文分词的概念,以Lucene为例探讨了基于词典、统计和规则的分词方法,包括最大匹配法、逆向最大匹配法、最小切分以及全切分。并对比了正向和逆向最大匹配法的优缺点,强调了基于统计方法如N元模型在解决歧义中的作用。同时提到了无字典分词和并行分词法。
本文介绍了中文分词的概念,以Lucene为例探讨了基于词典、统计和规则的分词方法,包括最大匹配法、逆向最大匹配法、最小切分以及全切分。并对比了正向和逆向最大匹配法的优缺点,强调了基于统计方法如N元模型在解决歧义中的作用。同时提到了无字典分词和并行分词法。
1、 什么是中文分词
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。而中文则以字为单位,字又组成词,字和词再组成句子。所以对于英文,我们可以简单以空格判断某个字符串是否为一个单词,比如I love China,love 和 China很容易被程序区分开来;但中文“我爱中国”就不 一样了,电脑不知道“中国”是一个词语还是“爱中”是一个词语。把中文的句子切分成有意义的词,就是中文分词,也称切词。我爱中国,分词的结果是:我 爱 中国。
目前中文分词还是一个难题———对于需要上下文区别的词以及新词(人名、地名等)很难完美的区分。国际上将同样存在分词问题的韩国、日本和中国并称为CJK(Chinese Japanese Korean),对于CJK这个代称可能包含其他问题,分词只是其中之一。
2、 中文分词的实现
Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。
Lucene自带了几个分词器WhitespaceAnalyzer, SimpleAnalyzer, StopAnalyzer, StandardAnalyzer, ChineseAnalyzer, CJKAnalyzer等。前面三个只适用于英文分词,StandardAnalyzer对可最简单地实现中文分词,即二分法,每个字都作为一个词,比如:”北京天安门” ==> “北京 京天 天安 安门”。这样分出来虽然全面,但有很多缺点,比如,索引文件过大,检索时速度慢等。ChineseAnalyzer是按字分的,与StandardAnalyzer对中文的分词没有大的区别。 CJKAnalyzer是按两字切分的, 比较武断,并且会产生垃圾Token,影响索引大小。以上分词器过于简单,无法满足现实的需求,所以我们需要实现自己的分词算法。
这样,在查询的时候,无论是查询”北京” 还是查询”天安门”,将查询词组按同样的规则进行切分:”北京”,”天安安门”,多个关键词之间按与”and”的关系组合,同样能够正确地映射到相应的索引中。这种方式对于其他亚洲语言:韩文,日文都是通用的。
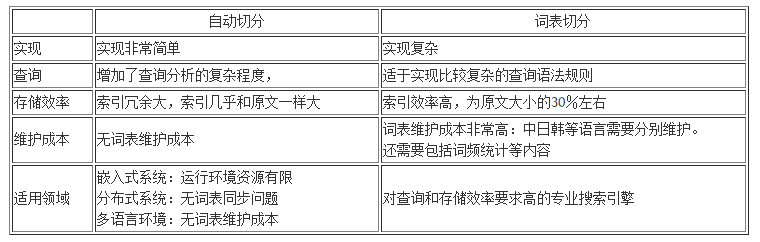
基于自动切分的最大优点是没有词表维护成本,实现简单,缺点是索引效率低,但对于中小型应用来说,基于2元语法的切分还是够用的。基于2元切分后的索引一般大小和源文件差不多,而对于英文,索引文件一般只有原文件的30%-40%不同。
目前比较大的搜索引擎的语言分析算法一般是基于以上2个机制的结合。关于中文的语言分析算法,大家可以在Google查关键词”wordsegment search”能找到更多相关的资料。
以下跟Lucene没啥关系!!!
中文分词技术分类
我们讨论的分词算法可分为三大类:
1.基于词典:基于字典、词库匹配的分词方法;(字符串匹配、机械分词法)
2.基于统计:基于词频度统计的分词方法;
3.基于规则:基于知识理解的分词方法。
第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









