







黄页88网: 简称黄页网或者黄页88,是由互联网资深人士创办于2009年11月。是一家整合企业黄页、分类信息以及时下流行的SNS社区三方面优势于一体定位于服务B2B平台的网站。主要帮助企业宣传推广公司品牌和产品,黄页88网精细划分了82个大行业分类,并且在每个大的分类下又进行了二级和三级行业细分,更加方便网友对所关注信息的查询和浏览,同时对企业发布的信息进行了整合分类更加方便企业对信息的管理和搜索引擎的收录。
官网: http://www.huangye88.com/
贵州IT企业: http://b2b.huangye88.com/guizhou/it/
时间: 2019/08/10
爬取内容: 公司名称,公司详情,联系电话,地点,主营产品。
操作环境: win10, python3.6, jupyter notebook,谷歌浏览器
技术难点:
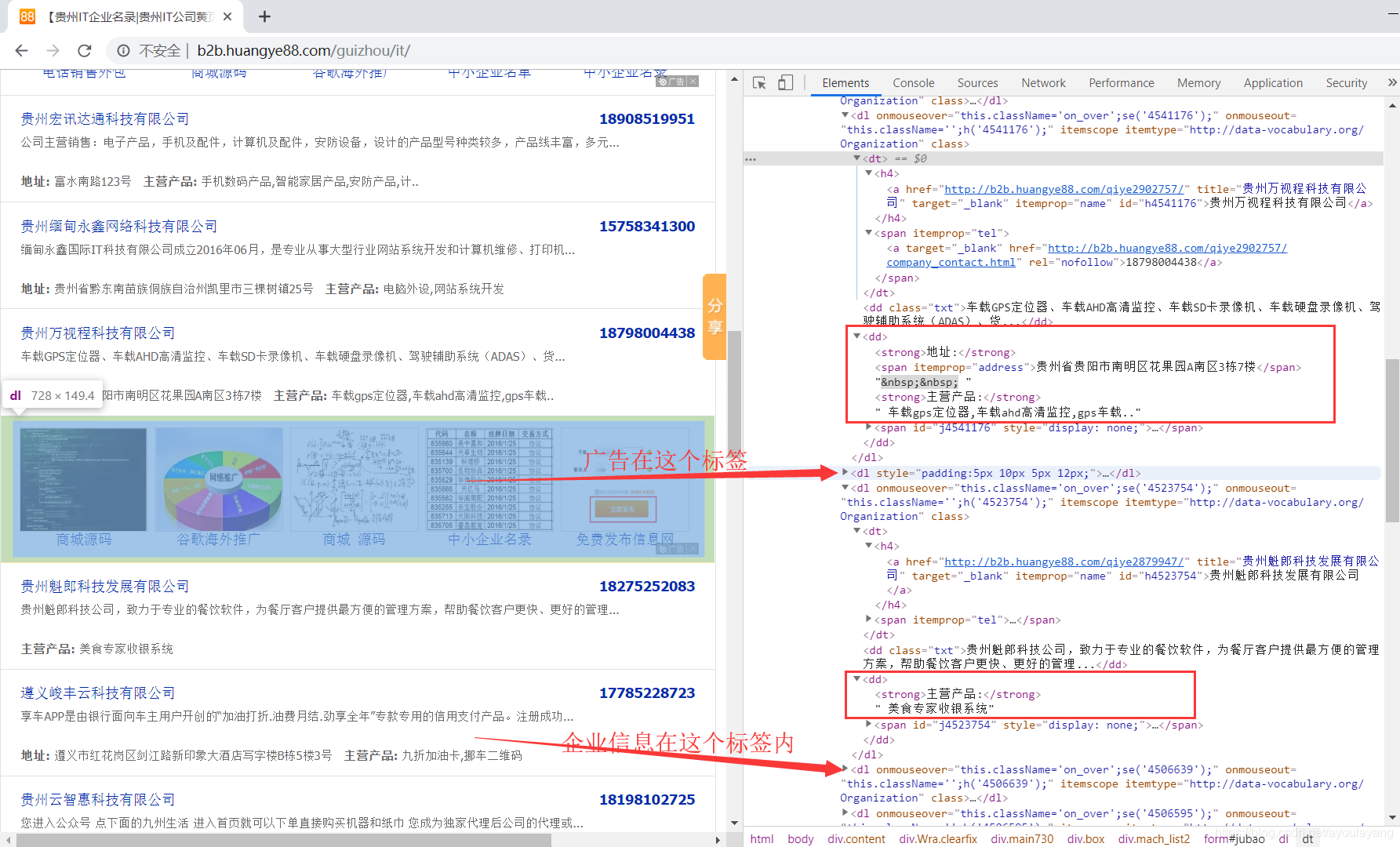
- 该网页的数据不是每一个信息都全面,有很多缺少的内容,企业的信息中经常缺失电话,地址,介绍,主营产品四个信息。
- 唯一不会缺的是企业的名称,但是其中广告的起始标签和企业的一样,而且三个企业就有一条广告,很容易误爬。
- 信息缺少的地方,标签也会缺少
1、请求网页源码
import requests
from lxml import etree
url = 'http://b2b.huangye88.com/guizhou/it/'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
html = etree.HTML(res.text)
2、分析网页
对于这个网页,不建议使用BeautifulSoup,因为广告和企业信息都在dl标签内,不方便定位节点。也不建议使用正则表达式,因为很多信息不全,标签的位置也不一样。
3、提取信息
3.1、先定位企业信息所在的节点,右键Copy Xpath,在其中进行循环查找数据;
for et in html.xpath('//*[@id="jubao"]/dl')
3.2、每个企业一定有的信息是企业名称和详情链接,都在<h4> </h4>标签中,容易区分广告,可以用它来判断其他的信息;
for et in html.xpath('//*[@id="jubao"]/dl'):
k = k + 1
name = et.xpath 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









