







(本文HashMap源码取自AndroidSDK中集成的JDK,与OracleJDK的代码实现有出入,但底层原理思想二者一致)
在讨论HashMap前,有必要先谈谈数组和链表这两种常用数据结构。
- 数组在内存中开辟的空间是连续的,如果要插入或者删除一个node,那么这个node之后的所有数据都要整体move,但数组的查询快(二分查找)。其特点是:寻址容易,增删困难
- 链表在内存中离散存储,插入和删除十分轻松,但查询较慢,每次都要从头到尾遍历一遍。其特点是:寻址困难,增删容易
正所谓美美与共天下大同,有木有一种即结合了两者优点又摒弃了两者缺点(寻址容易,增删容易)的数据结构呢?答案就是哈希表。
哈希表有多种不同的实现方案,本文接下来介绍的是最常用的一种(也是JDK中HashMap的实现方案)—— 拉链法,我们可以理解为“数组+链表” 。如图:
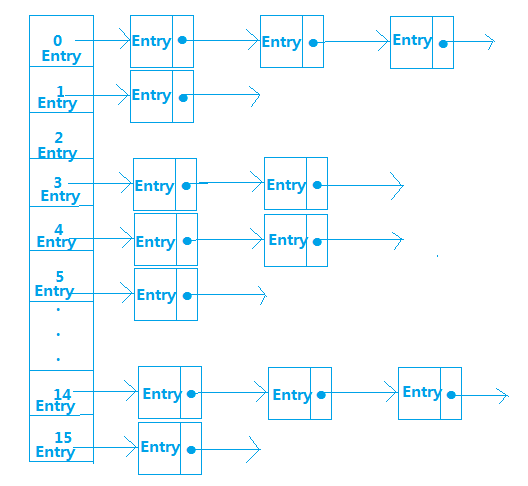
HashMap内部其实就是一个Entry数组(table),数组中每个元素都可以看成一个桶,每一个桶又构成了一条链表。代码如下:
/**
* The hash table. If this hash map contains a mapping for null, it is
* not represented this hash table.
*/
transient HashMapEntry<K, V>[] table;
...
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
...
}从中我们得知Entry存储的内容有key、value、hash值、和next(下一个Entry),那么,Entry数组是按什么规则来确定元素的存放下标的呢(或者说是按什么规则将数据放入桶中)?一般情况是通过hash(key)%len获得,也就是拿元素key的哈希值对数组长度取模得到。
假设hash(14)=14,hash(30)=30,hash(46)=46,数组len假设16,我们分别对len取余,得到 hash(14)%16=14,hash(30)%16=14,hash(46)%16=14,所以key为14、30、46的这三个元素存储在数组下标为14的位置。
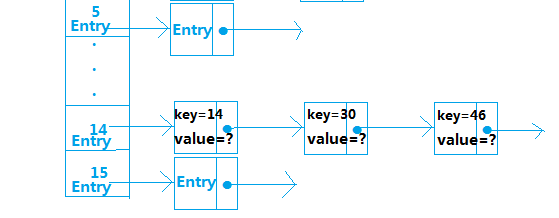
从中可以看出,在HashMap中put数据时,如果有多个元素key的hash值相同的话,后一个元素并不会覆盖上一个元素,而是采取链表的方式,把新进来的元素追加到链表头部(为什么是头部而不是尾部,在接下来的代码中将会看到)代码如下:
@Override
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value); // 数组的第一个位置可以放一个null对象
}
// 取key的hash值
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
// 根据hash值获取坐标,按位取并,相当于对length取模
int index = hash & (tab.length - 1);
// 遍历当前index元素的链表
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
// 如果key在链表中已存在,新value覆盖老value,并返回老value
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
// 如果size超过threshold,则双倍扩容table大小。
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
// 添加新的Entry
addNewEntry(key, value, hash, index);
return null;
}
void addNewEntry(K key, V value, int hash, int index) {
// 将老Entry作为新建Entry对象的next节点返回给当前数组元素
//(物理空间上其实是在链表头部添加新节点)
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}由此我们知道HashMap中处理hash冲突的方法是链地址法,在此补充一个知识点,处理hash冲突的方法有以下几种:
- 开放地址法
- 再哈希法
- 链地址法
- 建立公共溢出区
讲到这里,重点来了,当我们new出一个HashMap对象时,即使里面没有任何元素,它也会创建一个默认大小的Entry数组,AndroidJDK默认数组大小是2,OracleJDK默认数组大小是16。而我们不断向HashMap里put数据总会达到一定的容量限制,当达到某一阈值时,Entry数组将会被二倍扩容。*
注意:OracleJDK中的阈值计算公式是:当前Entry数组长度*加载因子,其默认的加载因子是0.75,加载因子也可以通过构造器来设置。AndroidJDK的加载因子也是0.75,不同的是,AndroidJDK不支持其他数值的加载因子:
public HashMap(int capacity, float loadFactor) {
this(capacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Load factor: " + loadFactor);
}
/*
* Note that this implementation ignores loadFactor; it always uses
* a load factor of 3/4. This simplifies the code and generally
* improves performance.
*/
}虽然AndroidJDK提供了带有加载因子参数的构造方法,但是并没有使用这个参数,原因注释说是为了简单,总是将阈值设为3/4,之后的分析将会展示google如何风骚的使用这个3/4
总之不管OracleJDK还是AndroidJDK,默认情况下,当HashMap里put的数据个数超过了容量的75%,容量会变成原来的两倍
// 默认的加载因子是0.75
static final float DEFAULT_LOAD_FACTOR = .75F;// OracleJDK中HashMap默认大小是16。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16// AndroidSDK中默认大小仅为2(4 >>> 1,可能考虑到移动终端内存比较小)
private static final int MINIMUM_CAPACITY = 4;
private static final Entry[] EMPTY_TABL =
new HashMapEntry[MINIMUM_CAPACITY >>> 1];put方法中元素个数超过阈值就会二倍扩容
if (size++ > threshold) {
// 如果size超过threshold,则双倍扩容table大小。
tab = doubleCapacity();
index = hash & (tab.length - 1);
}而threshold在HashMap的无参构造函数中的初始值是-1,
/**
* Constructs a new empty {@code HashMap} instance.
*/
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
// Forces first put invocation to replace EMPTY_TABLE
threshold = -1;
}也就是说,在AndroidJDK的HashMap中使用无参构造方法后,第一次put数据就会触发哈希表的二倍扩容,因为扩容后数组的长度发生了变化,所以数据入桶的位置也会发生变化,这个时候需要新构建Hash表:
/**
* Doubles the capacity of the hash table. Existing entries are placed in
* the correct bucket on the enlarged table. If the current capacity is,
* MAXIMUM_CAPACITY, this method is a no-op. Returns the table, which
* will be new unless we were already at MAXIMUM_CAPACITY.
*/
private HashMapEntry<K, V>[] doubleCapacity() {
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
return oldTable;
}
//扩容后是原来的二倍
int newCapacity = oldCapacity * 2;
//拿扩容后的容量作为参数去构建一个新的Entry数组
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
//size是当前哈希表中元素个数
if (size == 0) {
return newTable;
}
for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
// 上面的注释翻译过来就是:这段是这个类中最巧妙最微妙的代码
// 重设数据的位置,构建新表
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}根据传入的容量参数分配新的阈值(新容量的3/4),并返回新的Entry数组
/**
* Allocate a table of the given capacity and set the threshold accordingly.
* @param newCapacity must be a power of two
*/
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
//新阈值 = 新容量/2 + 新容量/4
//google工程师的风骚写法,相当于乘以容量的3/4,直接没加载因子的事了
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}至于取元素就简单了,HashMap会根据key的hash值得到元素入桶的位置,从而找到Entry链表(二分查找),再去遍历链表去找对应的value:
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}结尾:HashMap的每一次扩容都会重新构建一个length是原来两倍的Entry表,这个二倍扩容的策略很容易造成空间浪费,试想一下,假如我们总共有100万条数据要存放,当我put到第75万条时达到阈值,Hash表会重新构建一个200万大小的数组,但是我们最后只放了100万数据,剩下的100万个空间将被浪费。而且HashMap在存储这些数据的过程中需要不断扩容,不断的构建Entry表,不断的做hash运算,此外,HashMap获取数据是通过遍历Entry链表来实现的,在数据量很大时候会慢上加慢,所以google又推出了SparseArray和ArrayMap来代替HashMap(尽管google已经针对android平台优化了HashMap),这两个类的分析我会在之后给大家分享出来。















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









