






作者:大数据技术与架构
By 大数据技术与架构
场景描述:大数据开发岗位技能树,学习和复习总纲。
关键词:面试 大数据 大纲
正所谓,无招胜有招。
愿读到这篇文章的技术人早日明白并且脱离技术本身,早登彼岸。
一切技术最终只是雕虫小技。
大纲
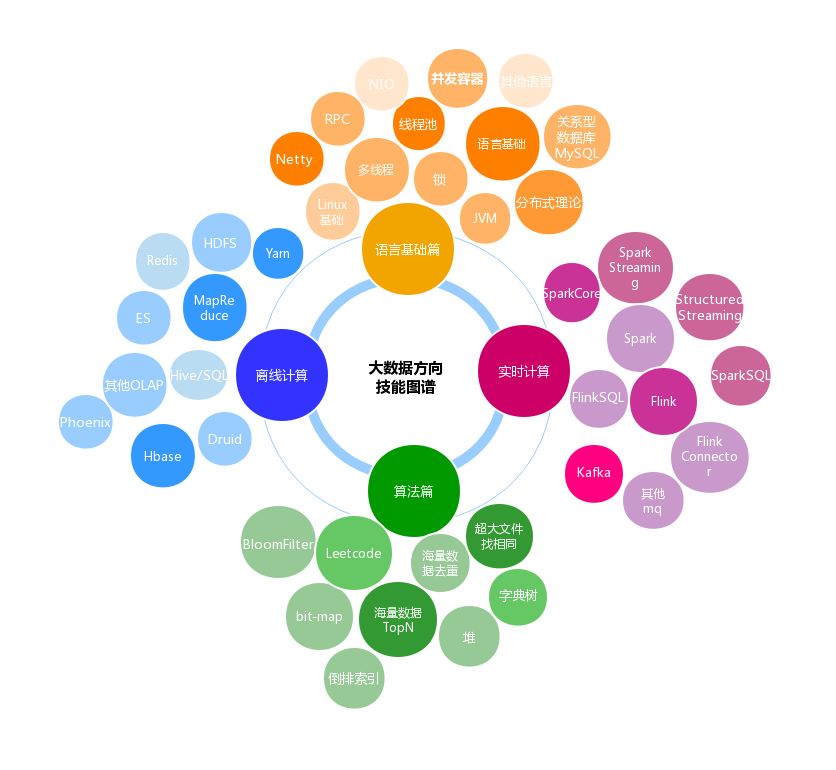
语言基础篇
语言基础
锁
多线程
并发包中常用的并发容器(J.U.C)
语言基础
Java 的面向对象
Java 语言的三大特征:封装、继承和多态
Java 语言数据类型
Java 的自动类型转换,强制类型转换
String 的不可变性,虚拟机的常量池,String.intern() 的底层原理
Java 语言中的关键字:final、static、transient、instanceof、volatile、synchronized的底层原理
Java 中常用的集合类的实现原理:ArrayList/LinkedList/Vector、SynchronizedList/Vector、HashMap/HashTable/ConcurrentHashMap 互相的区别以及底层实现原理
动态代理的实现方式
锁
CAS、乐观锁与悲观锁、数据库相关锁机制、分布式锁、偏向锁、轻量级锁、重量级锁、monitor
锁优化、锁消除、锁粗化、自旋锁、可重入锁、阻塞锁、死锁
死锁的原因
死锁的解决办法
CountDownLatch、CyclicBarrier 和 Semaphore 三个类的使用和原理
多线程
并发和并行的区别
线程与进程的区别
线程的实现、线程的状态、优先级、线程调度、创建线程的多种方式、守护线程
自己设计线程池、submit() 和 execute()、线程池原理
为什么不允许使用 Executors 创建线程池
死锁、死锁如何排查、线程安全和内存模型的关系
ThreadLocal 变量
Executor 创建线程池的几种方式:
newFixedThreadPool(int nThreads)
newCachedThreadPool()
newSingleThreadExecutor()
newScheduledThreadPool(int corePoolSize)
newSingleThreadExecutor()
ThreadPoolExecutor 创建线程池、拒绝策略
线程池关闭的方式
并发容器(J.U.C)
JUC 包中 List 接口的实现类:CopyOnWriteArrayList
JUC 包中 Set 接口的实现类:CopyOnWriteArraySet、ConcurrentSkipListSet
JUC 包中 Map 接口的实现类:ConcurrentHashMap、ConcurrentSkipListMap
JUC包中Queue接口的实现类:ConcurrentLinkedQueue、ConcurrentLinkedDeque、ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque
Java 进阶篇
JVM
class 文件格式、运行时数据区:堆、栈、方法区、直接内存、运行时常量池
Java 中的对象一定在堆上分配吗?
计算机内存模型、缓存一致性、MESI 协议、可见性、原子性、顺序性、happens-before、内存屏障、synchronized、volatile、final、锁
GC 算法:标记清除、引用计数、复制、标记压缩、分代回收、增量式回收、GC 参数、对象存活的判定、垃圾收集器(CMS、G1、ZGC、Epsilon)
-Xmx、-Xmn、-Xms、Xss、-XX:SurvivorRatio、-XX:PermSize、-XX:MaxPermSize、-XX:MaxTenuringThreshold
oop-klass、对象头
即时编译器、编译优化
jps、jstack、jmap、jstat、jconsole、 jinfo、 jhat、javap、btrace、TProfiler、Arthas
classLoader、类加载过程、双亲委派(破坏双亲委派)、模块化(jboss modules、osgi、jigsaw)
NIO
用户空间以及内核空间
Linux 网络 I/O 模型:阻塞 I/O (Blocking I/O)、非阻塞 I/O (Non-Blocking I/O)、I/O 复用(I/O Multiplexing)、信号驱动的 I/O (Signal Driven I/O)、异步 I/O
灵拷贝(ZeroCopy)
BIO 与 NIO 对比
缓冲区 Buffer
通道 Channel
反应堆
选择器
AIO
RPC
RPC 的原理编程模型
常用的 RPC 框架:Thrift、Dubbo、SpringCloud
RPC 的应用场景和与消息队列的差别
RPC 核心技术点:服务暴露、远程代理对象、通信、序列化
Linux 基础
了解 Linux 的常用命令
远程登录
上传下载
系统目录
文件和目录操作
Linux 下的权限体系
压缩和打包
用户和组
Shell 脚本的编写
管道操作
分布式理论篇
分布式中的一些基本概念:集群(Cluster)、负载均衡(Load Balancer)等
分布式系统理论基础:一致性、2PC 和 3PC
分布式系统理论基础:CAP
分布式系统理论基础:时间、时钟和事件顺序
分布式系统理论进阶:Paxos
分布式系统理论进阶:Raft、Zab
分布式系统理论进阶:选举、多数派和租约
分布式锁的解决方案
分布式事务的解决方案
分布式 ID 生成器解决方案
大数据框架网络通信基石——Netty
Netty 三层网络架构:Reactor 通信调度层、职责链 PipeLine、业务逻辑处理层
Netty 的线程调度模型
序列化方式
链路有效性检测
流量整形
优雅停机策略
Netty 对 SSL/TLS 的支持
Netty 的源码质量极高,推荐对部分的核心代码进行阅读:
Netty 的 Buffer
Netty 的 Reactor
Netty 的 Pipeline
Netty 的 Handler 综述
Netty 的 ChannelHandler
Netty 的 LoggingHandler
Netty 的 TimeoutHandler
Netty 的 CodecHandler
Netty 的 MessageToByteEncoder
离线计算
掌握 MapReduce 的工作原理
能用 MapReduce 手写代码实现简单的 WordCount 或者 TopN 算法
掌握 MapReduce Combiner 和 Partitioner的作用
熟悉 Hadoop 集群的搭建过程,并且能解决常见的错误
熟悉 Hadoop 集群的扩容过程和常见的坑
如何解决 MapReduce 的数据倾斜
Shuffle 原理和减少 Shuffle 的方法
十分熟悉 HDFS 的架构图和读写流程
十分熟悉 HDFS 的配置
熟悉 DataNode 和 NameNode 的作用
NameNode 的 HA 搭建和配置,Fsimage 和 EditJournal 的作用的场景
HDFS 操作文件的常用命令
HDFS 的安全模式
Yarn 的产生背景和架构
Yarn 中的角色划分和各自的作用
Yarn 的配置和常用的资源调度策略
Yarn 进行一次任务资源调度的过程
OLAP 引擎 Hive
HiveSQL 的原理:我们都知道 HiveSQL 会被翻译成 MapReduce 任务执行,那么一条 SQL 是如何翻译成 MapReduce 的?
Hive 和普通关系型数据库有什么区别?
Hive 支持哪些数据格式
Hive 在底层是如何存储 NULL 的
HiveSQL 支持的几种排序各代表什么意思(Sort By/Order By/Cluster By/Distrbute By)
Hive 的动态分区
HQL 和 SQL 有哪些常见的区别
Hive 中的内部表和外部表的区别
Hive 表进行关联查询如何解决长尾和数据倾斜问题
HiveSQL 的优化(系统参数调整、SQL 语句优化)
列式数据库 Hbase
Hbase 的架构和原理
Hbase 的读写流程
Hbase 有没有并发问题?Hbase 如何实现自己的 MVVC 的?
Hbase 中几个重要的概念:HMaster、RegionServer、WAL 机制、MemStore
Hbase 在进行表设计过程中如何进行列族和 RowKey 的设计
Hbase 的数据热点问题发现和解决办法
提高 Hbase 的读写性能的通用做法
HBase 中 RowFilter 和 BloomFilter 的原理
Hbase API 中常见的比较器
Hbase 的预分区
Hbase 的 Compaction
Hbase 集群中 HRegionServer 宕机如何解决
实时计算篇
分布式消息队列 Kafka
Kafka 的特性和使用场景
Kafka 中的一些概念:Leader、Broker、Producer、Consumer、Topic、Group、Offset、Partition、ISR
Kafka 的整体架构
Kafka 选举策略
Kafka 读取和写入消息过程中都发生了什么
Kakfa 如何进行数据同步(ISR)
Kafka 实现分区消息顺序性的原理
消费者和消费组的关系
消费 Kafka 消息的 Best Practice(最佳实践)是怎样的
Kafka 如何保证消息投递的可靠性和幂等性
Kafka 消息的事务性是如何实现的
如何管理 Kafka 消息的 Offset
Kafka 的文件存储机制
Kafka 是如何支持 Exactly-once 语义的
通常 Kafka 还会要求和 RocketMQ 等消息中间件进行比较
Spark
Spark的集群搭建和集群架构(Spark 集群中的角色)
Spark Cluster 和 Client 模式的区别
Spark 的弹性分布式数据集 RDD
Spark DAG(有向无环图)
掌握 Spark RDD 编程的算子 API(Transformation 和 Action 算子)
RDD 的依赖关系,什么是宽依赖和窄依赖
RDD 的血缘机制
Spark 核心的运算机制
Spark 的任务调度和资源调度
Spark 的 CheckPoint 和容错
Spark 的通信机制
Spark Shuffle 原理和过程
原理剖析(源码级别)和运行机制
Spark Dstream 及其 API 操作
Spark Streaming 消费 Kafka 的两种方式
Spark 消费 Kafka 消息的 Offset 处理
数据倾斜的处理方案
Spark Streaming 的算子调优
并行度和广播变量
Shuffle 调优
Spark SQL 的原理和运行机制
Catalyst 的整体架构
Spark SQL 的 DataFrame
Structured Streaming 的模型
Structured Streaming 的结果输出模式
事件时间(Event-time)和延迟数据(Late Data)
窗口操作
水印
容错和数据恢复
Flink
Flink 集群的搭建
Flink 的架构原理
Flink 的编程模型
Flink 集群的 HA 配置
Flink DataSet 和 DataSteam API
序列化
Flink 累加器
状态 State 的管理和恢复
窗口和时间
并行度
Flink 和消息中间件 Kafka 的结合
Flink Table 和 SQL 的原理和用法
大数据算法
两个超大文件找共同出现的单词
海量数据求 TopN
海量数据找出不重复的数据
布隆过滤器
bit-map
堆
字典树
倒排索引
企业期望的你是什么样子?



1~2 门语言基础
扎实的后台开发基础
离线计算方向(Hadoop/Hbase/Hive 等)
实时计算方向(Spark/Flink/Kafka 等)
知识面更宽优先(对口经验 + 其他)
漂亮的排版,杜绝使用 word,格式化的模板,推荐使用 MarkDown 生成 PDF
不要堆砌技术名词,不会的不了解的不要写,否则你会被虐的体无完肤
1~2 个突出的项目经历,不要让你的简历看起来像Demo一样浅显
写在简历上的项目我建议你要熟悉每一个细节,即使不是你开发的也要知道是如何实现的
如果有一段知名企业的实习或者工作经历那么是很大的加分
轮子
的优劣,也要对未来的技术发展有一定的前瞻性和预见性。


扫码关注我们
过往记忆大数据
ID : iteblog_hadoop
个人微信号:fangzhen0219
后台回复888获取大数据学习资料














 7584
7584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









