







一、江湖环境(基于VirtualBox)
操作系统:Centos7
节点数:3
版本:Hadoop-3.3.0

二、江湖代理人
useradd hadoop 创建用户hadoop
passwd hadoop123 给已创建的用户hadoop 设置密码

三、内功修炼(已修炼可跳过)
- 安装JDK1.8 64位
- 安装openssh-server
sudo apt-get install ssh openssh-server - 安装Hadoop平台
①通过命令下载hadoop:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-3.3.0.tar.gz
②解压文件
tar -zxvf hadoop-3.3.0.tar.gz
四、分身小弟(DataNode)
- 记得更换IP地址(root用户下修改)


四、桃园结义(ssh免密配置)
-
确立江湖名号(hostname)
①sudo vi /etc/hosts
192.168.1.112 namenode
192.168.1.113 datanode1
192.168.1.114 datanode2 -
散发名号


-
老大哥(NameNode)名号归位(小弟们也要记得归位哦)
①sudo vi /etc/hostname localhost -> namenode
②sudo vi /etc/hosts

③reboot

-
各节点创建ssh-key,使用如下命令:
ssh-keygen -t rsa -P ‘’ -
敬酒,获取信任
①datanode1向大哥敬酒
ssh-copy-id hadoop@namenode
②datanode2向大哥敬酒
ssh-copy-id hadoop@namenode
③大哥干了
ssh-copy-id hadoop@namenode
④向小弟们派发信任书
scp ~/.ssh/authorized_keys hadoop@datanode1:~/.ssh/
scp ~/.ssh/authorized_keys hadoop@datanode2:~/.ssh/
⑤校验是否达成信任协议
ssh hadoop@datanode1 //免密登录,即为已达成信任
五、配置Hadoop集群
①加入环境变量
vi /etc/profile
添加如下内容:
export HADOOP_HOME=/home/sri_udap/app/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载profile:
source /etc/profile
②修改配置文件:
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
添加如下内容:
export JAVA_HOME=$JAVA_HOME(根据自己的jdk目录,替换成绝对路径)
core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.3.0/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-3.3.0/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-3.3.0/datas</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
vi workers
datanode1
datanode2
(
以上配置需要发放到小弟节点上,可以使用scp命令:
scp -r ~/hadoop-3.3.0/etc/hadoop/ hadoop@datanode1:~/hadoop-3.3.0/etc/
scp -r ~/hadoop-3.3.0/etc/hadoop/ hadoop@datanode2:~/hadoop-3.3.0/etc/
)
③格式化:(格式化一次就好,多次格式化可能导致datanode无法识别,如果想要多次格式化,需要先删除数据再格式化)
./bin/hdfs namenode -format
④添加配置到hadoop-env.sh
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
⑤启动
./sbin/start-dfs.sh
./sbin/start-yarn.sh
⑥关闭城墙(防火墙)
systemctl stop firewalld
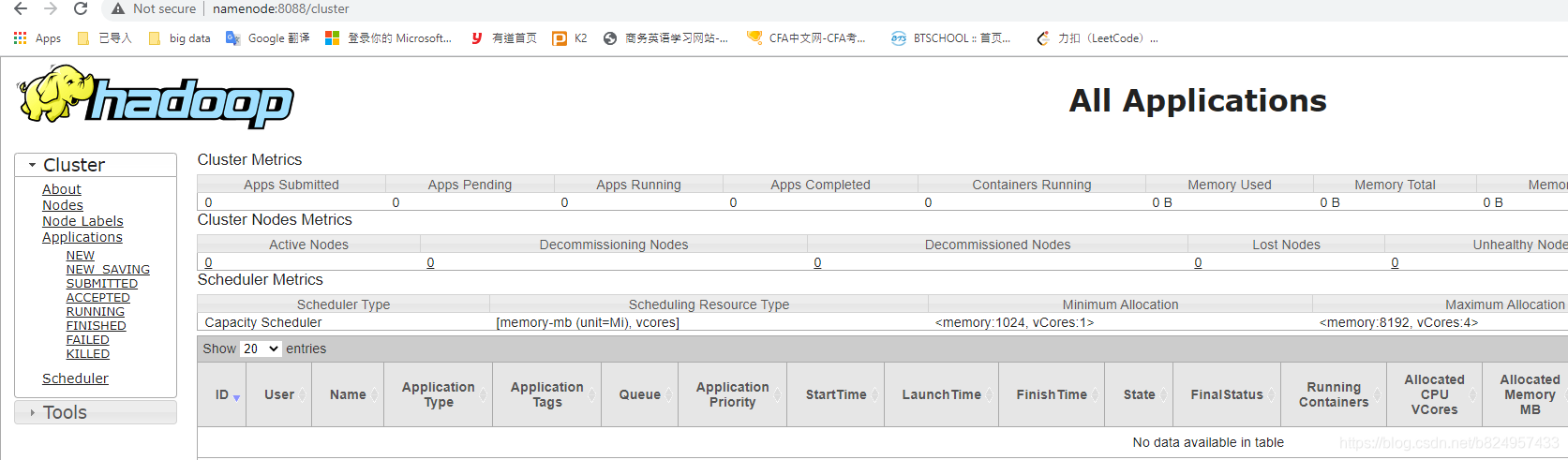
⑦测试是否可以连上














 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









