







一、键排序
原数据:两列分别是品牌、销售额
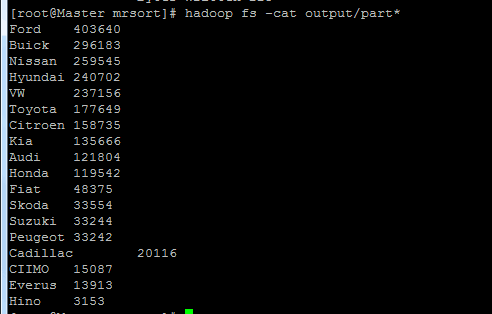
Hino 3153 Toyota 177649 Buick 296183 Cadillac 20116 Audi 121804 Skoda 33554 VW 237156 Nissan 259545 Hyundai 240702 Kia 135666 Ford 403640 Fiat 48375 CIIMO 15087 Everus 13913 Honda 119542 Citroen 158735 Peugeot 33242 Suzuki 33244
排序后结果:
在shuffle(洗牌)过程中,会将map的输出结果按照key进行排序,所以只需要将Bean作为map输出的key值,前提是
Bean实现了Comparable接口。在hadoop中既实现Writable接口,又实现Comparable接口,可以简写为实现了
WritableComparable接口。
Bean.java
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class Bean implements WritableComparable<Bean> { private String carName; private long sum; public Bean() { } public Bean(String carName, long sum) { this.carName = carName; this.sum = sum; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(carName); out.writeLong(sum); } @Override public void readFields(DataInput in) throws IOException { this.carName = in.readUTF(); this.sum = in.readLong(); } public String getCarName() { return carName; } public void setCarName(String carName) { this.carName = carName; } public long getSum() { return sum; } public void setSum(long sum) { this.sum = sum; } @Override public String toString() { return "" + sum; } @Override public int compareTo(Bean o) { return this.sum > o.sum ? -1 : 1; } }
SortMapReduce.java
import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SortMapReduce { public static class SortMapper extends Mapper<LongWritable, Text, Bean, NullWritable> { @Override protected void map( LongWritable k1, Text v1, Mapper<LongWritable, Text, Bean, NullWritable>.Context context) throws IOException, InterruptedException { String line = v1.toString(); String[] fields = StringUtils.split(line, "\t"); String carName = fields[0]; long sum = Long.parseLong(fields[1]); context.write(new Bean(carName,sum),NullWritable.get()); } } public static class SortReducer extends Reducer<Bean, NullWritable, Text, Bean> { @Override protected void reduce(Bean k2, Iterable<NullWritable> v2s, Reducer<Bean, NullWritable, Text, Bean>.Context context) throws IOException, InterruptedException { String carName = k2.getCarName(); context.write(new Text(carName), k2); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(SortMapReduce.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(Bean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Bean.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
二、二次排序
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class SecondSort extends Configured implements Tool{ public static void main(String[] args) throws Exception { ToolRunner.run(new SecondSort(), args); } @Override public int run(String[] args) throws Exception { Configuration conf = getConf(); @SuppressWarnings("deprecation") Job job = new Job(conf); job.setJarByClass(getClass()); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setOutputKeyClass(MyPairWritable.class); job.setOutputValueClass(NullWritable.class); job.setSortComparatorClass(PairKeyComparator.class); job.waitForCompletion(true); return 0; } } class SortMapper extends Mapper<LongWritable, Text, MyPairWritable, NullWritable>{ MyPairWritable pair= new MyPairWritable(); protected void map(LongWritable key, Text value, Context context) throws java.io.IOException ,InterruptedException { String[] strs = value.toString().split(" "); Text keyy = new Text(strs[0]); IntWritable valuee = new IntWritable(Integer.parseInt(strs[1])); pair.set(keyy, valuee); context.write(pair, NullWritable.get()); }; } class SortReducer extends Reducer<MyPairWritable, NullWritable,MyPairWritable, NullWritable>{ protected void reduce(MyPairWritable key, java.lang.Iterable<NullWritable> values, Context context) throws IOException ,InterruptedException { context.write(key, NullWritable.get()); }; } class PairKeyComparator extends WritableComparator{ public PairKeyComparator() { super(MyPairWritable.class,true); } @SuppressWarnings("rawtypes") @Override public int compare(WritableComparable a, WritableComparable b) { MyPairWritable p1 = (MyPairWritable)a; MyPairWritable p2 = (MyPairWritable)b; if(!p1.getFirst().toString().equals(p2.getFirst().toString())){ return p1.first.toString().compareTo(p2.first.toString()); }else { return p1.getSecond().get() - p2.getSecond().get(); } } } class MyPairWritable implements WritableComparable<MyPairWritable>{ Text first; IntWritable second; public void set(Text first, IntWritable second){ this.first = first; this.second = second; } public Text getFirst(){ return first; } public IntWritable getSecond(){ return second; } @Override public void readFields(DataInput in) throws IOException { first = new Text(in.readUTF()); second = new IntWritable(in.readInt()); } @Override public void write(DataOutput out) throws IOException { out.writeUTF(first.toString()); out.writeInt(second.get()); } @Override public int compareTo(MyPairWritable o) { if(this.first != o.getFirst()){ return this.first.toString().compareTo(o.first.toString()); }else if(this.second != o.getSecond()){ return this.second.get() - o.getSecond().get(); } else return 0; } @Override public String toString() { return first.toString() + " " + second.get(); } @Override public boolean equals(Object obj) { MyPairWritable temp = (MyPairWritable)obj; return first.equals(temp.first) && second.equals(temp.second); } @Override public int hashCode() { return first.hashCode() * 163 + second.hashCode(); } }
GitHub :Sort















02-23
 6713
6713
6713
06-12
1963
1963
05-19
2474
2474
07-01
2469
2469
07-17
1637
1637
07-31
1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









