










一、配置Heritrix项目
1.下载heritrix编译后的字节码包与源码包
heritrix-1.14.4.zip
heritrix-1.14.4-src.zip
注:以下文件未强调时均为源码包中的文件。2.创建Java Project项目
3.复制src/java目录下的com、org、st包到项目的src下
4.将lib文件夹复制到项目根目录下,并将所有jar添加到Bulid Path
5.右键项目Properties
->Java Compiler
->Errors/Warnings
->Configure WorkPlace Settings
->Deprecated and restricted API 把error修改为warning
6.复制conf到根目录下 修改heritrix.properties中以下两项
heritrix.version = @VERSION@为heritrix.version = 1.14.4
heritrix.cmdline.admin = admin:admin (即登录账号与密码均为admin)
7.复制webapps到根目录下,复制字节码包下webapps的admin.war到webapps
8.复制src\resources\org\archive\util中的tlds-alpha-by-domain.txt到org.archive.util包
9.添加conf:
->run configurations
->classpath(此时注意项目名称是否为你选择的项目名,若不是则手动选择)
->Advanced
->Add Folders
->选择项目下的conf文件夹
->Run
控制台输出如下:
10.访问127.0.0.1:8080并登录(默认情况下是8080端口)
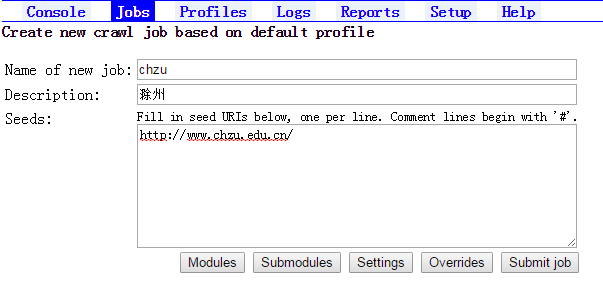
11.创建任务Jobs
->With defaults 输入job名、描述、url地址(如http://www.chzu.edu.cn)
->选择Modules
->Select Writers Processors选择org.archive.crawler.writer.MirrorWriterProcessor并Add
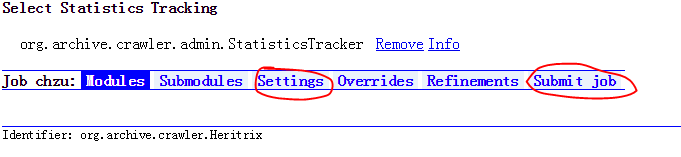
->选择Setting
->user-agent:修改版本号、from处填写符合邮箱格式的邮箱地址
->提交作业Submit job
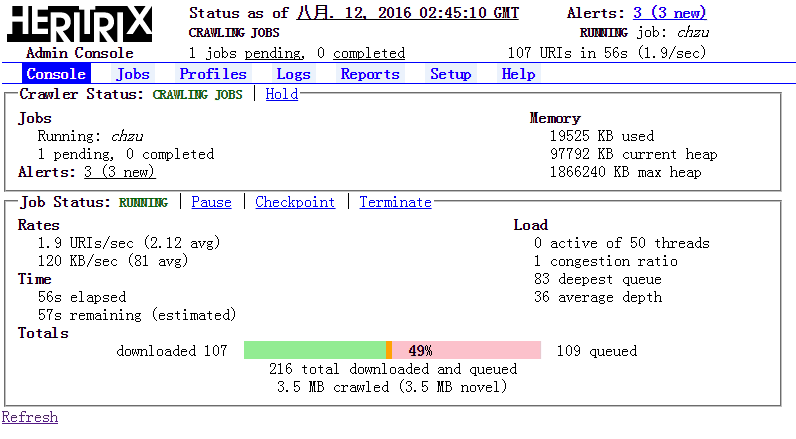
->Console
->Start
->Refresh
如下:
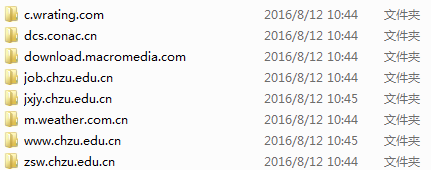
抓取结果存储在项目根目录下的jobs文件夹中:
可以看出结果中存在一些与chzu.edu.cn不相关的网站数据,下面我们对其进行简单过滤。



二、主题抓取
1 . 使用FrontierScheduler类过滤抓取的域名
在org.archive.crawler.postprocessor包中创建MyFrontierScheduler类,继承FrontierScheduler,并重写protected void schedule(CandidateURI caUri)方法,以下我们过滤域名中存在"chzu.edu.cn"的网站。
package org.archive.crawler.postprocessor; import org.archive.crawler.datamodel.CandidateURI; public class MyFrontierScheduler extends FrontierScheduler { private static final long serialVersionUID = -1074778906898000967L; public MyFrontierScheduler(String name) { super(name); } protected void schedule(CandidateURI caUri) { //过滤URI if(caUri.toString().contains("chzu.edu.cn")){ getController().getFrontier().schedule(caUri); } } }
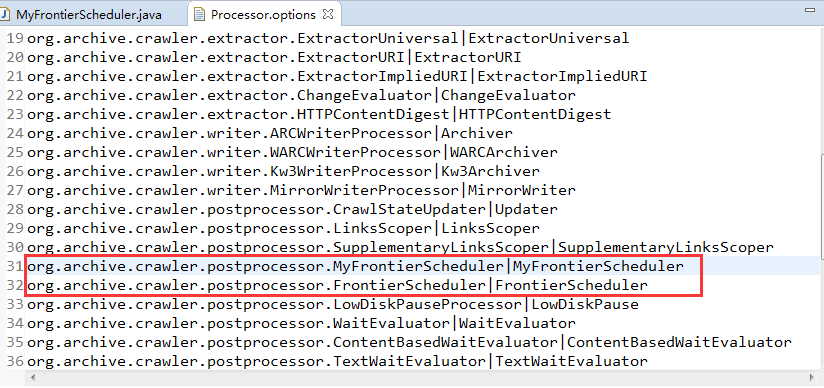
在配置文件conf\modules\Processor.options中配置MyFrontierScheduler类
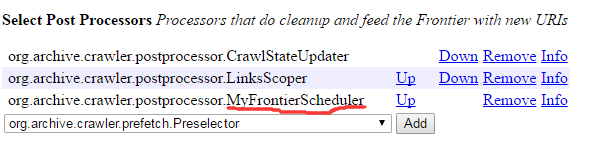
在job中选择自定义的FrontierScheduler如下
2 . 使用Extractor抽象类过滤url
编写继承org.archive.crawler.Extractor的子类实现其抽象方法,以下以抓取滁州学院信息学院官网为例。
package org.archive.crawler.extractor; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.archive.crawler.datamodel.CrawlURI; import org.archive.io.ReplayCharSequence; import org.archive.util.HttpRecorder; public class ExtractorChzu extends Extractor { private static final long serialVersionUID = 8082386142013745017L; public ExtractorChzu(String name, String description) { super(name, description); } public ExtractorChzu(String name) { super(name, "CSCI"); } //匹配a标签中的有效链接 //<a href='/s/15/t/199/e0/e4/info123108.htm' target=_blank title="xxxxxxx"> private static final String A_HREF="<a(.*)href\\s*=\\s*(\'/\\w/\\d+/\\w/\\d+/\\w+/\\w+/info\\d+.htm\')(.*)>"; private static final String DOMAIN="http://csci.chzu.edu.cn"; @Override protected void extract(CrawlURI curi) { String url =""; try { HttpRecorder hr = curi.getHttpRecorder(); if(hr==null){ throw new IOException("HttpRecorder IOException"); } ReplayCharSequence rc= hr.getReplayCharSequence(); if(rc==null){ return; } String content = rc.toString(); Pattern pattern = Pattern.compile(A_HREF, Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(content); while(matcher.find()){ url = matcher.group(2).replaceAll("'", ""); curi.createAndAddLinkRelativeToBase(DOMAIN+url, content, Link.NAVLINK_HOP); } } catch (Exception e) { e.printStackTrace(); } } }
在配置文件中配置
在job配置页面选择


三、错误解决
运行时报错:
ERROR: '无法编译样式表'
FATAL ERROR: 'java.net.MalformedURLException'
:null
2016-08-10 23:39:11.870 严重 thread-40 org.archive.crawler.framework.WriterPoolProcessor.getFirstrecordBody() Failed transform javax.xml.transform.TransformerConfigurationException: java.net.MalformedURLException
2016-08-10 23:39:11.878 严重 thread-40 org.archive.io.arc.ARCWriter.getMetadataLength() Unsupported metadata type: null
解决:
heritrix里面的arcMetaheaderBody.xsl文件就copy到Eclipse 工程src目录下运行下即可
运行时报错:
Heritrix version: 1.14.4
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/cli/UnrecognizedOptionException
at org.archive.crawler.Heritrix.doCmdLineArgs(Heritrix.java:607)
at org.archive.crawler.Heritrix.main(Heritrix.java:556)
Caused by: java.lang.ClassNotFoundException: org.apache.commons.cli.UnrecognizedOptionException
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
... 2 more
解决:
在Run Configurations中的Classpath下单击Restore Default Entries,重新选择conf文件夹运行。















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









