






一主一从两台k8s集群启动后,master节点全部正常,work节点的calico-node一直启动失败。查看日志发现如下错误:
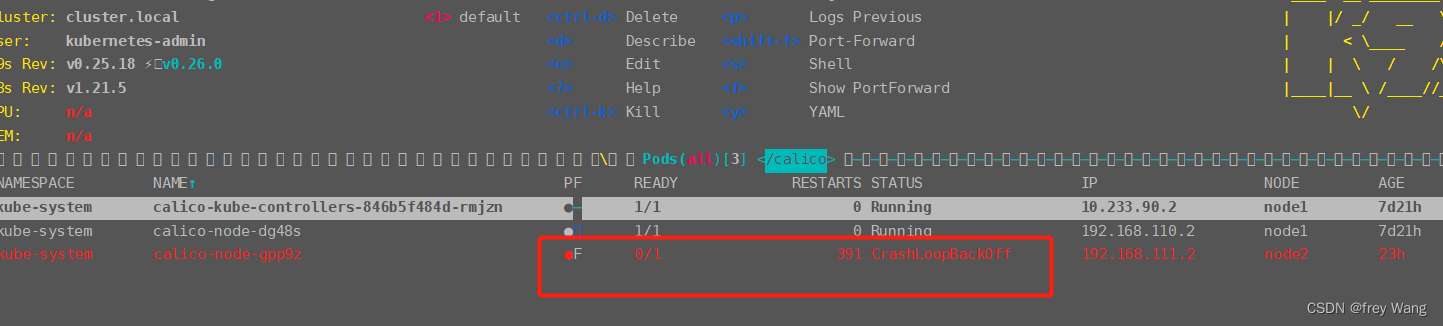
检查容器事件及日志,发现有如下报错:
Liveness probe failed: calico/node is not ready: Felix is not live: Get "http://localhost:9099/liveness": dial tcp [
│ :1[]:9099: connect: connection refused
Liveness probe failed: calico/node is not ready: bird/confd is not live: exit status 1
-----------------------------------------------------------------------------------------
2022-07-21 08:08:10.064 [INFO][9] startup/startup.go 416: Hit error connecting to datastore - retry error=Get "https://10.233.64.1:443/api/v1/nodes/foo": dial tcp 10.233.6
│ 4.1:443: i/o timeout
-----------------------------------------------------------------------------------------
Events:
│ Type Reason Age From Message
│ ---- ------ ---- ---- -------
│ Warning Unhealthy 44m (x10743 over 17d) kubelet Liveness probe failed: calico/node is not ready: Felix is not live: Get "http://localhost:9099/liveness": dial tcp
│ ::1[]:9099: connect: connection refused
│ Normal Pulled 24m (x7006 over 17d) kubelet Container image "calico/node:v3.20.0" already present on machine
│ Warning Unhealthy 9m40s (x55319 over 17d) kubelet Readiness probe failed: calico/node is not ready: BIRD is not ready: Failed to stat() nodename file: stat /var/lib/
│ calico/nodename: no such file or directory
│ Warning BackOff 4m39s (x86064 over 17d) kubelet Back-off restarting failed container 从pod事件来看,是健康检查没过。Failed to stat() nodename file: stat /var/lib/
│ calico/nodename: no such file or directory
从容器日志来看,是 “https://10.233.64.1:443/api/v1/nodes/foo”这个请求没调通。
首先检测网络,在宿主机上执行 ping 10.233.64.1,发现网络是通的。执行 telnet 10.233.64.1 443,发现443端口不通
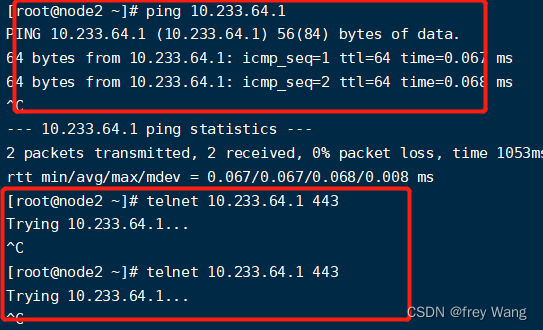
10.233.64.1是service的clusterip

检查 ipvsadm -ln 发现链路都正常。
检查 ipvsadm -lnc 发现tcp状态不对,无法建立tcp连接。
这个问题大概率是历史安装文件没有清理干净,比较靠谱的做法:
1、清理历史配置
rm -rf /etc/cni/net.d/*
rm -rf /var/lib/calico/*
ipvsadm --clear
2、修改网段,让service网段和pod网段区分开
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
3、重新创建calico














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









