






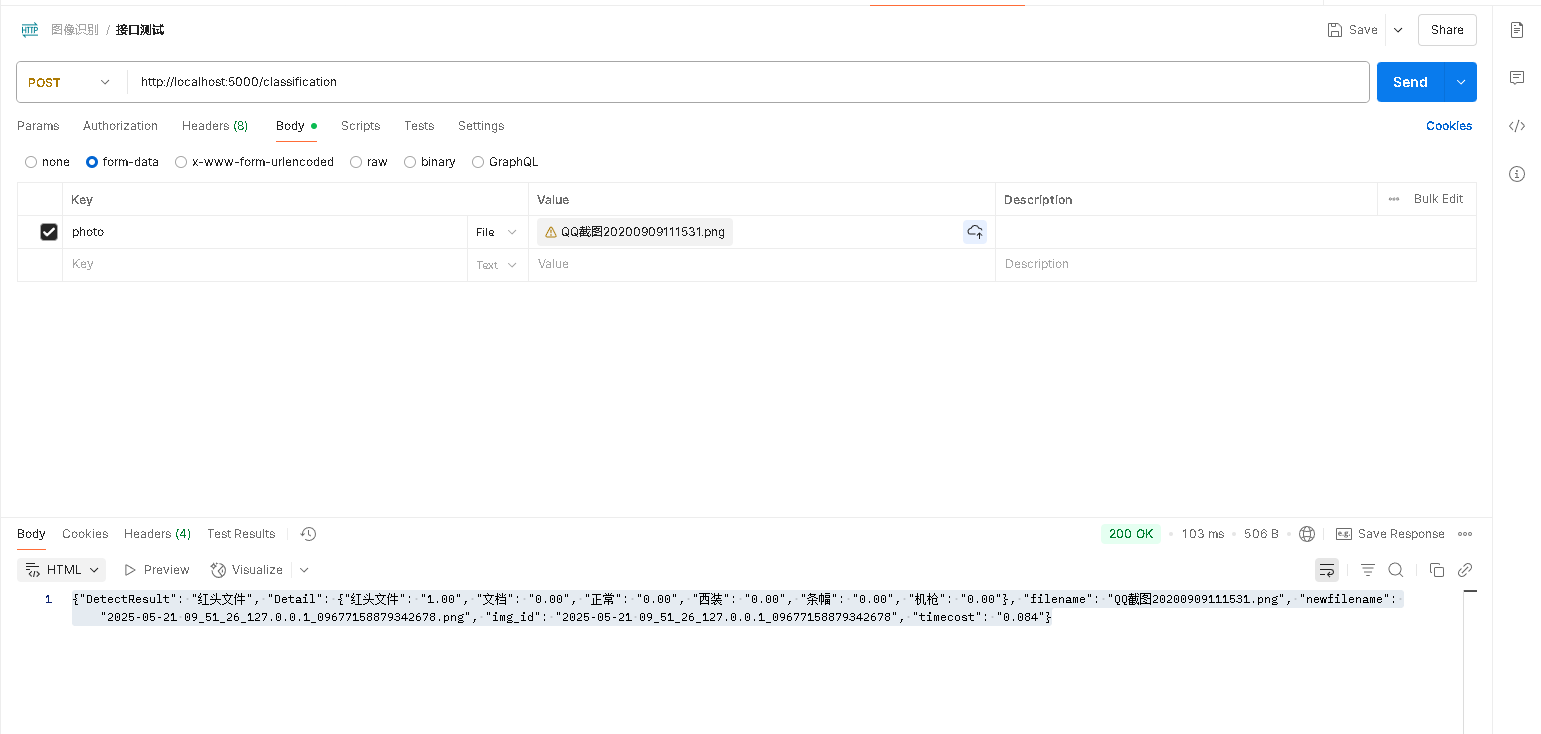
配置 Postman 接口步骤如下:
1. 请求方法和URL
-
Method:
POST -
URL:
http://localhost:5000/classification
2. Headers(可以不填,Postman 会自动处理 multipart/form-data)
3. Body 设置
-
选择 Body → 选择 form-data
-
添加一项:
-
Key:
photo(和 HTML 表单中一致) -
Type:选择为
File -
Value:选择你本地的图片文件,如
微信图片_20250521085740.jpg
-
4. 示例 JSON 响应格式
你将收到类似这样的返回:
{
"DetectResult": "正常",
"Detail": {
"正常": "0.63",
"人像": "0.34",
"西装": "0.03",
"色情图片": "0.00",
"一般卡通": "0.00",
"集体照": "0.00"
},
"filename": "微信图片_20250521085740.jpg",
"newfilename": "2025-05-21 09_34_43_127.0.0.1_09974683778800802.jpg",
"img_id": "2025-05-21 09_34_43_127.0.0.1_09974683778800802",
"timecost": "0.536"
}
当然,下面是你收到的这份 JSON 报文的字段含义详细解释:
✅ 完整报文:
{
"DetectResult": "正常",
"Detail": {
"正常": "0.63",
"人像": "0.34",
"西装": "0.03",
"色情图片": "0.00",
"一般卡通": "0.00",
"集体照": "0.00"
},
"filename": "微信图片_20250521085740.jpg",
"newfilename": "2025-05-21 09_34_43_127.0.0.1_09974683778800802.jpg",
"img_id": "2025-05-21 09_34_43_127.0.0.1_09974683778800802",
"timecost": "0.536"
}
🔍 字段含义逐项说明:
| 字段名 | 类型 | 含义 |
|---|---|---|
DetectResult | 字符串 | 最终分类结果,即系统对该图片的主观判断分类,如“正常”、“色情图片”、“人像”等。这里是 "正常",表示未检测出异常内容。 |
Detail | 字典(JSON对象) | 对该图片的每个类别的分类置信度(一般是 softmax 概率),值为字符串形式的浮点数。所有值加起来接近 1。目前只返回前5名的值 |
Detail["正常"] | 字符串 | 分类为“正常”内容的概率,这里是 0.63(63%) |
Detail["人像"] | 字符串 | 分类为“人像”的概率(34%),可能表示图中有人物但不属于不良内容 |
Detail["西装"] | 字符串 | 表示检测到“穿西装”的可能性(3%) |
Detail["色情图片"] | 字符串 | 判断为色情图的概率(这里是 0.00,说明无风险) |
Detail["一般卡通"] | 字符串 | 检测到“卡通”内容的概率 |
Detail["集体照"] | 字符串 | 图像被判断为“集体合影”的概率 |
filename | 字符串 | 上传的原始图片文件名 |
newfilename | 字符串 | 系统保存的重命名后的文件名,格式通常包含时间、IP、唯一编号等信息 |
img_id | 字符串 | 图像的唯一 ID,可用于后续追溯或查看检测历史,通常和 newfilename 同步生成 |
timecost | 字符串/浮点数 | 处理这张图片花费的时间(单位:秒),用于性能监控 |
📌 举例说明:
这份返回结果表示:
-
这张图系统判断为“正常”内容(63%置信度)。
-
其中包含 人像(34%)和 西装(3%)的概率。
-
没有任何色情、卡通或集体照等高风险内容。
-
接口处理耗时 0.536 秒,整体较快。
下面是python调用的方法
import requests
import os
#url = 'http://localhost:5000/classification' # 自己想要请求的接口地址
#url = 'http://10.10.10.16:5000/classification'
url = 'http://localhost:5000/classification'
#url = 'http://10.10.10.191:5000/classification'
def sendImg(img_path,img_type='image/jpeg'):
img_name=os.path.basename(img_path)
with open(img_path , "rb")as f_abs: # 以2进制方式打开图片
body = {
# 有些上传图片时可能会有其他字段,比如图片的时间什么的vim,这个根据自己的需要
'photo': (img_name, f_abs, img_type)
}
# 上传图片的时候,不使用data和json,用files
response = requests.post(url=url, files=body)
return response.text
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'JPG', 'PNG', 'gif', 'GIF', 'JPEG', 'jpeg' ])
#是否是可以检测的图片类型
def allowed_file(filename):
global basedir, orihtml, imageSize, labels, ALLOWED_EXTENSIONS
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
if __name__ == '__main__':
# 批量上传目录下的文件
check_path = r'./testImg'
for root, dirs, files in os.walk(check_path):
for file in files:
file_path = os.path.join(root, file)
if allowed_file(file_path):
res = sendImg(file_path) # 调用sendImg方法
print(file_path,res)
# 单个的文件检测
# file_path = r'e:\4.jpg'
# if allowed_file(file_path):
# res = sendImg(file_path) # 调用sendImg方法
# print(file_path, res)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









