









提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
根据ORACLE的优化思想来学习达梦的SQL优化
一、什么是选择性
基数和总行数的比值再乘以100%就是某个列的选择性。
在进行SQL优化的时候,单独看列的基数是没有任何意义的,基数必须对比总行数才有实际的意义。
下面我们查看test各个列的基数与选择性,为了查看选择性,必须先收集统计信息。
二、使用步骤
1.收集 统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SCOTT',
tabname => 'TEST',
estimate_percent => 100,
method_opt => 'for all columns size 1',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE);
END;
/
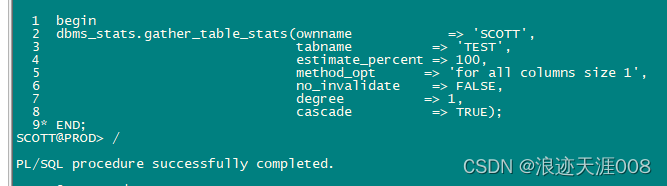
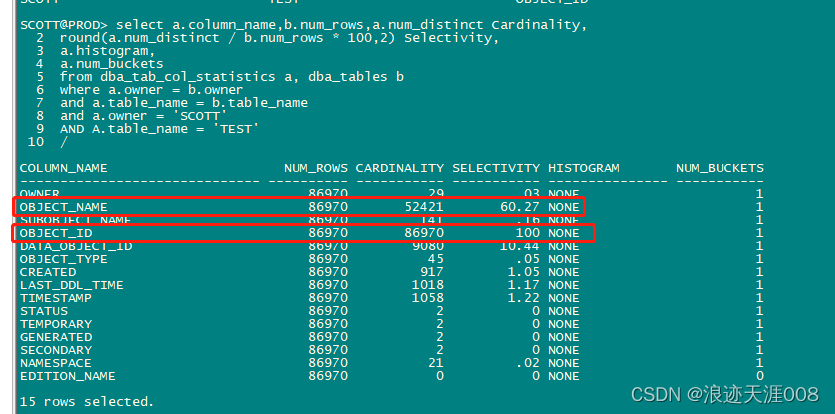
下面的脚本看TEST表中每个列的基数和选择性。
select a.column_name,b.num_rows,a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100,2) Selectivity,
a.histogram,
a.num_buckets
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
AND A.table_name = 'TEST'
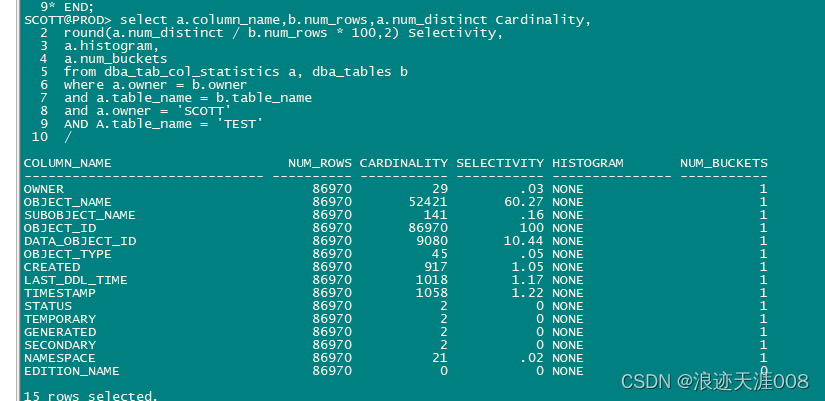
请思考,什么样的列必须创建索引?
有人说基数高的列,有人说在where条件中的列。这些答案并不完美。基数高究竟是多高?没有和总行数进行对比,始终不知道有多高。比如某个列的基数有几万行,但是总行数有几十亿行。那么这个基数还高吗?这就是为什么要用选择性这个概念的根本原因。
当一个列的选择性大于20%,说明该列的数据分布比较均衡了,测试表test中的OBJECT_NAME,OBJECT_ID的选择性都大于20% ,其中OBJECT_NAME的选择性为60.2%,现在我们来看该列的数据分布
set linesize 200;
col object_name for a35;
select * from (select object_name,count(*) from test
group by object_name
order by 2 desc)
where rownum <= 10;
由上面的结果可以知道,object_name列的数据分布非常均衡。我们查询一下sql
select * from test where object_name = :B1;
不管OBJECT_NAME传入什么值,最多返回34行数据。
总结
单一个列出现在where条件中,该列没有创建索引,并且选择性大于20%。那么该列就必须创建索引。从而提升查询性能。当然了,如果表只有几百条数据,我们就不必创建索引了。
SQL优化核心思想第一个观点:只有大表才会产生性能问题。
自动化脚本分享:抓出必须创建索引的列(请根据自己的环境对该脚本适当的修改,以便用于生产环境。)
首先,该类必须出现在where中,那么怎么抓出表的那个列出现在where条件中呢?有两种方法,一种通过v$SQL_PLAN抓取,另一个通过下面的脚本进行抓取。
begin
dbms_stats.flush_database_monitoring_info;
end;
/
执行完上面的命令之后,再运行下面的查询语句就可以查询出哪个表的哪个列出现在where条件中。
select r.name owner,
o.name table_name,
c.name column_name,
equality_preds,---等值过滤
equijoin_preds, ---等值join 比如 where a.id=b.id
nonequijoin_preds, ---不等JOIN
range_preds,---范围过滤次数 > >= < <= between and
like_preds, ---LIKE过滤
null_preds, ---NULL过滤
timestamp
from sys.col_usage$ u, sys.obj$ o, sys.col$ c, sys.user$ r
where o.obj#= u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and r.name = 'SCOTT'
and o.name = 'TEST'
/
下面是实验,我们首先运行一个查询语句,让owner与object_id列的出现在where条件中。
select object_id,owner,object_type from test
where owner = 'SYS'
and object_id < 100
and rownum <=10
/
然后刷新数据库监控信息
exec dbms_stats.flush_database_monitoring_info;
然后查询test表中哪些列出现在where条件中。
select r.name owner,
o.name table_name,
c.name column_name,
equality_preds,---等值过滤
equijoin_preds, ---等值join 比如 where a.id=b.id
nonequijoin_preds, ---不等JOIN
range_preds,---范围过滤次数 > >= < <= between and
like_preds, ---LIKE过滤
null_preds, ---NULL过滤
timestamp
from sys.col_usage$ u, sys.obj$ o, sys.col$ c, sys.user$ r
where o.obj#= u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and r.name = 'SCOTT'
and o.name = 'TEST'
/

接着我们查询出选择性大于20%的列。
select a.column_name,b.num_rows,a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100,2) Selectivity,
a.histogram,
a.num_buckets
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
AND A.table_name = 'TEST'
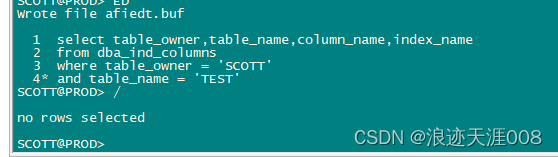
最后,确定这些列没有创建索引
select table_owner,table_name,column_name,index_name
from dba_ind_columns
where table_owner = 'SCOTT'
and table_name = 'TEST'
/
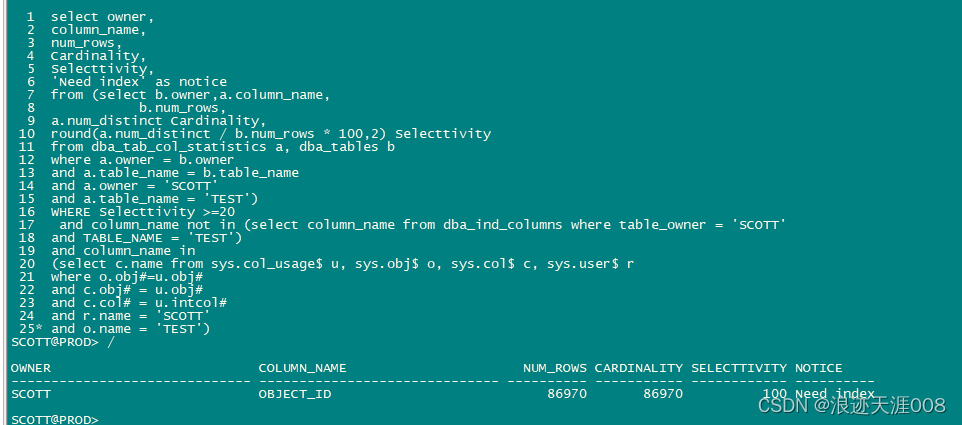
没有索引,把上面的脚本组合起来,我们就可以得到自动优化的脚本了。
select owner,
column_name,
num_rows,
Cardinality,
Selecttivity,
'Need index' as notice
from (select b.owner,a.column_name,
b.num_rows,
a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100,2) Selecttivity
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
and a.table_name = 'TEST')
WHERE Selecttivity >=20
and column_name not in (select column_name from dba_ind_columns where table_owner = 'SCOTT'
and TABLE_NAME = 'TEST')
and column_name in
(select c.name from sys.col_usage$ u, sys.obj$ o, sys.col$ c, sys.user$ r
where o.obj#=u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and r.name = 'SCOTT'
and o.name = 'TEST')
/















 1965
1965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









