







1.Self-supervised Learning

Supervised是要有label的资料
Self-supervised是让资料一部分作为model,一部分作为label
2.Masking Input

两种方法,要么随机盖住某个token,要么将此token随机换成别的词。

对其做Linear transform(矩阵)然后进行softmax得到一个分布
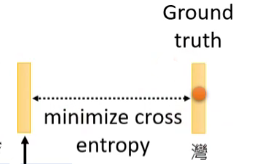
我们知道盖住的词是什么,BERT不知道,所以看输出的词与原来词的最小交叉熵
3.How to use BERT - case1(Sentiment analysis)

init by pre-train better than random
Case2(POS tagging词性标注)

Case3 (Natural Language Inference (NLI))

premise:前提 ; hypothesis:假设
根据前提是否能推出假设,如果矛盾输出contradiction……

Case4 QA

文章document和问题Query都是句子,丢进QA Model里,输出标志s,e。 那么答案就是……
表示文章里第一个词汇

橙色表示起始位置,蓝色表示终止位置,是唯二需要随机初始化的
先用橙色向量与document的token输出值进行卷积,得到数值最大的下标作为起始位置
同理,蓝色向量作为终止位置。















 2062
2062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









