







Flink学习-DataStream-KafkaConnector
Flink系列文章
摘要
本文主要介绍Flink1.9中的DataStream之KafkaConnector,大部分内容翻译、整理自官网。以后有实际demo会更新。
如果关注Table API & SQL中的KafkaConnector,请参考Flink学习3-API介绍-SQL
1 Maven依赖
FlinkKafkaConnector版本很多,如果使用的Kafka版本0.11以前的版本就必须仔细核对使用的包的版本,而在0.11开始可以使用统一KafkaConnectorApi,会使用该Flink版本发布时的最新Kafka版本,用法如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11-SNAPSHOT</version>
</dependency>
2 KafkaConsumer
2.1 KafkaConsumer构建
创建一个KafkaConsumer例子(如果Kafka版本在1.0.0及以后,就直接使用FlinkKafkaConsumer来初始化):
// 1. get streaming runtime
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2. build a kafka source
val properties = new Properties()
properties.setProperty("bootstrap.servers", "192.168.1.111:9092")
properties.setProperty("group.id", "test")
import org.apache.flink.api.scala._
val stream = env
// 这里使用Kafka 0.10 Consumer,
// 并使用SimpleStringSchema来反序列化Kafka中的二进制数据为Scala对象
// SimpleStringSchema使用默认的UTF-8来将Kafka传来的byte[]转为String
.addSource(new FlinkKafkaConsumer010[String]("topic", new SimpleStringSchema(), properties))
.print()
2.2 反序列化DeserializationSchema
反序列化Kafka数据时,可以使用DeserializationSchema或者 KafkaDeserializationSchema:
- DeserializationSchema
每条消息会调用DeserializationSchema的public String deserialize(byte[] message)方法 - KafkaDeserializationSchema
每条消息会调用deserialize(ConsumerRecord<byte[], byte[]> record)方法,可用来访问Kafka消息的key、value和元数据。
Flink还提供了:
- SimpleStringSchema
最简单的序列化类,默认使用UTF-8来把收到的二进制byte[]反序列化为String。 - 基于TypeInformation的
TypeInformationSerializationSchema和TypeInformationKeyValueSerializationSchema,适用于数据读写全由Flink完成的场景; - 解析序列化JSON为ObjectNode的
JsonDeserializationSchema和JSONKeyValueDeserializationSchema,可直接用objectNode.get("field").as(Int/String/...)()来使用数据,还有个可选的metadatafiled可访问该条记录的offset/partition/topic。 - 解析Avro格式数据的的AvroDeserializationSchema
需要注意的是,如果deserialize方法反序列化失败抛出异常,则会导致该job失败,从而重启。而由于消费者错误容忍,所以重启后又会去读这条无法反序列化的数据,如此反复陷入死循环。
所以我们必须处理异常,并返回null跳过这条数据。
2.3 设置offset
val myConsumer = new FlinkKafkaConsumer08[String](...)
// 尽可能从最早的记录开始,忽略Group存储的offset
myConsumer.setStartFromEarliest()
// 从最新的记录开始,忽略Group存储的offset
myConsumer.setStartFromLatest()
// 从指定的时间开始(毫秒)
myConsumer.setStartFromTimestamp(...)
// 默认的方法,设置为用groupId放在ZK的offset,
// 如果找不到就用配置文件中的auto.offset.reset来决定
myConsumer.setStartFromGroupOffsets()
// 指定每个分区的要消费的起始offset;未指定的分区使用setStartFromGroupOffsets
val specificStartOffsets = new java.util.HashMap[KafkaTopicPartition, java.lang.Long]()
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L)
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 1), 31L)
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 2), 43L)
myConsumer.setStartFromSpecificOffsets(specificStartOffsets)
val stream = env.addSource(myConsumer)
注意,以上方法不影响此行为:从checkpoint/savepoint恢复消费时用存在checkpoint/savepoint里面的offset开始消费。
2.4 offset提交与checkpoint容错
开启了checkpoint时,KafkaConsumer在不断消费数据的同时也会周期性、一致性地保存offset以及其他算子的State到checkpoint。这样,在作业失败出错的时候,就可以从最近的checkpoint中恢复我们的流应用,并继续从出错之前的offset开始消费Kafka。所以,chekpoint的间隔至关重要。
开启checkpoint:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// checkpoint every 5000 ms
env.enableCheckpointing(5000)
注意,只有当可用的 slots 足够时,Flink 才能重启。因此,如果Flink程序拓扑是由于丢失了 TaskManager 而失败,那么之后必须要一直有足够可用的 solt。Flink on YARN 支持自动重启丢失的 container。
注意:
-
如果没开启checkpoint,则KafkaConsumer只会周期性提交offset到ZK。
可设置enable.auto.commit和auto.commit.interval.ms来控制提交offset行为 -
而开启了checkpoint,则此时提交到Kafka的那份offset的唯一的作用就是监控Flink程序消费情况。
此时,每当完成checkpoint,就会将存于checkpoint的offset提交到Kafka,这样保证了两处offset的一致性。如果不想自动提交offset到Kafka,可通过
kafkaConsumer.setCommitOffsetsOnCheckpoints(false)关闭。
2.5 Topic和分区发现
动态发现默认关闭,需要设置flink.partition-discovery.interval-millis为非负数表示发现新分区/Topic时间间隔。
-
动态分区
Flink KafkaConsumer支持动态创建的Kafka分区,且Consumer会精准一次的消费。在程序初始启动后发现的新分区会从earliest开始消费。 -
动态Topic
支持正则表达式发现新Topic:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
val myConsumer = new FlinkKafkaConsumer08[String](
// 发现test-topic-开头,数字结尾的topic
java.util.regex.Pattern.compile("test-topic-[0-9]"),
new SimpleStringSchema,
properties)
val stream = env.addSource(myConsumer)
...
2.6 时间戳抽取和水位
Flink支持两种数位抽取:
- AssignerWithPeriodicWatermarks
周期性地发送记录中包含的作为水位的timestamp。 - AssignerWithPunctuatedWatermarks
不规律的发送,比如根据kafka数据流里包含当前事件时间的 watermark 的特殊记录。
更多内容可参考:
内置的预定义时间戳提取器/水位发送器可参考Pre-defined Timestamp Extractors / Watermark Emitters
自定义的时间戳提取器/水位发送器可参考Generating Timestamps / Watermarks
注意,如果watermark assigner依赖于从Kafka中读到的信息来提升水位(通常都是这么干的),那么所有topic/partition都必须拥有连续记录,否则会导致水位无法提升、基于时间的算子比如时间窗口、时间函数都失效无法进行。目前Flnk社区正在尝试解决此隐患,目前我们需要避免空闲分区等异常情况。
3 KafkaProducer
3.1 KafkaProducer构建
注意,如果Kafka版本在1.0.0及以后,就直接使用FlinkKafkaProducer来初始化
// 5. create a kafka producer
val kafkaProducer = new FlinkKafkaProducer010[String](
"192.168.1.111:9092", // broker list
"test-topic", // target topic
new SimpleStringSchema) // serialization schema
// 6. 0.10+版本允许附上记录的event时间戳,然后再写入kafka
kafkaProducer.setWriteTimestampToKafka(true)
// 7. create the sink with a kafka producer
kafkaStream.addSink(kafkaProducer)
其他还在初始化FlinkKafkaProducer的时候设置:
- 自定义生产者Properties
参考Apache Kafka documentation - 自定义Partitioner
请参阅自定义Partitioner - 自定义SerializationSchema
与Consumer类似,Producer可以指定写入数据到Kafka前对数据序列化的方法,
3.2 自定义Partitioner
不指定时,KafkaProducer默认使用FlinkFixedPartitioner,每个task内的记录都发送到固定某个的partition。注意,如果task并行数小于partition数,则会造成部分partition无数据!
可以自定义Partitioner,以下是一个根据某个field的hash进行分配partition的示例:
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner;
import org.apache.flink.util.Preconditions;
import java.util.Map;
/**
* @Author: chengc
* @Date: 2019-12-05 16:49
*/
public class HashPartitioner<T> extends FlinkKafkaPartitioner<T> {
// 必须可序列化
private static final long serialVersionUID = 8103823686368682159L;
private ObjectMapper objectMapper;
/**
* 每个FlinkSink并行实例初始化时会调用一次本方法
* @param parallelInstanceId 并行Sink实例ID,从0开始
* @param parallelInstances 并行Sink实例总数
*/
@Override
public void open(int parallelInstanceId, int parallelInstances) {
Preconditions.checkArgument(parallelInstanceId >= 0, "Id of this subtask cannot be negative.");
Preconditions.checkArgument(parallelInstances > 0, "Number of subtasks must be larger than 0.");
this.objectMapper = new ObjectMapper();
}
/**
* 决定每条record被写往哪个partition的核心方法
* @param record 该条record
* @param key 该条record序列化后的key
* @param value 该条record序列化后的value
* @param targetTopic 该条record要写入的topic
* @param partitions 该条record要写入的topic的已发现的分区
* @return 该条record要写入的partition号
*/
@Override
public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
Preconditions.checkArgument(
partitions != null && partitions.length > 0,
"Partitions of the target topic is empty.");
try {
Map content = objectMapper.readValue(new String(value), Map.class);
String customId = String.valueOf(content.get("field1"));
// 注意这里一定要加绝对值,因为hashCode可能为负数
return partitions[Math.abs(customId.hashCode()) % partitions.length];
}catch (Exception e){
return partitions[0];
}
}
@Override
public boolean equals(Object o) {
return this == o || o instanceof HashPartitioner;
}
@Override
public int hashCode() {
return HashPartitioner.class.hashCode();
}
}
注意:
- Partitioner必须是可序列化的,因为需要在 Flink 节点之间传输。
- Partitioner中的任何状态都将在作业失败时丢失,因为Partitioner并不是 producer 的
checkpoint state的一部分。 - 也可以传入null作为CustomPartitioner,此时仅使用record的序列化后的key作为分区依据。
3.3 KafkaProducer的容错性
-
Kafka 0.8
在 0.8及之前版本,不能保证at least once或exactly once的语义。 -
Kafka 0.9 / 0.10
启用 Flink 的checkpointing后,FlinkKafkaProducer09和 FlinkKafkaProducer010可提供at least once的语义。除了启用checkpoint,还应注意以下内容:
-
setLogFailuresOnly
默认为 false,此时如果发生异常会向上抛出自重导致job失败,从而导致flink程序进入恢复重启模式,实现at least once;如果设为true,将使 producer 仅将异常记录日志,也就是说即使某条记录未写入Kafka也不会导致程序崩溃,此时当然就不能实现
at least once。 -
setFlushOnCheckpoint
默认为true,进行中的Checkpoint会等到所有写入中的记录(即KafkaProducer Buffer中的数据)已经得到Kafka确认才算成功。对at least once的语义而言,这个方法必须启用。 -
retries
KafkaProducer的Properties配置项。默认为0。这是Producer发送数据到Kafka错误时的重试次数。 -
无法保证写入
exactly once
0.10及以前版本Kafka还没有producer事务 ,所以 Flink 不能保证写入 Kafka topic 的exactly once语义。
-
-
Kafka 0.11及以后版本
启用 Flink 的 checkpoint后,FlinkKafkaProducer011和适用于 Kafka 1.0.0及以后版本的 FlinkKafkaProducer都可以提供exactly once的语义保证。除了启用checkpoint,还可以通过将适当的
semantic参数传递给 FlinkKafkaProducer011或FlinkKafkaProducer来选择三种不同的语义:-
Semantic.NONE:Flink 不会有任何语义的保证,产生的记录可能会丢失或重复。
-
Semantic.AT_LEAST_ONCE(默认):类似 FlinkKafkaProducer010 中的
setFlushOnCheckpoint(true),可以保证不会丢失任何记录(记录可能重复)。 -
Semantic.EXACTLY_ONCE:使用 Kafka 生产者事务提供
exactly once的语义。注意,在使用事务写入 Kafka 时,记得为所有消费 Kafka的应用程序设置所需的
isolation.level(read_committed或read_uncommitted,后者为默认)。
-
-
Kafka 0.11及以后版本注意事项
Semantic.EXACTLY_ONCE模式依赖于事务提交的能力。事务提交发生于触发 checkpoint 之前,以及从 checkpoint 恢复之后。如果从 Flink 应用程序崩溃到从checkpoint恢复重启之间的时间超过了 Kafka 的事务超时时间,那么将会有数据丢失(Kafka 会自动丢弃超出超时时间的事务)。所以,请根据预期的flink宕机恢复时间来合理地配置事务超时时间。默认情况下,Kafka broker 将
transaction.max.timeout.ms设置为15分钟。此属性不允许为大于其值的producer设置事务超时时间。 但默认情况下,FlinkKafkaProducer011 将 producer config 中的transaction.timeout.ms属性设置为 1 小时,因此在使用Semantic.EXACTLY_ONCE模式之前应该增加Broker的transaction.max.timeout.ms的值。在 KafkaConsumer 的
read_committed模式中,任何未结束(既未中止也未完成)的事务将阻塞来自给定 Kafka topic 的未结束事务之后的所有读取数据。 比如,在遵循如下一系列事件之后:- 用户启动了 transaction1 并使用它写了一些记录
- 用户启动了 transaction2 并使用它写了一些其他记录
- 用户提交了 transaction2
即使 transaction2 中的记录已提交,在提交或中止 transaction1 之前,消费者也不会看到未完成的transaction1之后的记录。这有 2 层含义:
-
首先,在 Flink 应用程序的正常工作期间,用户应该预见到Kafkac中生成的数据的可见性会延迟差不多等于完成checkpoint 之间的平均间隔时间。
-
其次,在 Flink 应用程序失败的情况下,此应用程序正在写入的供消费者读取的topic将被阻塞,直到应用程序重新启动或配置的生产者事务超时时间耗尽后,才恢复正常读取。此项仅适用于有多个 agent 或者应用程序写入同一 Kafka topic的情况。
-
注意:
Semantic.EXACTLY_ONCE模式为每个 FlinkKafkaProducer011 实例使用固定大小的 KafkaProducer池,且每个 checkpoint 使用其中一个 producer。如果并发 checkpoint 的数量超过KafkaProducer池的大小,则FlinkKafkaProducer011 将抛出异常,并导致整个应用程序失败。所以,务必合理地配置最大池大小和最大并发 checkpoint 数量。
-
注意:Semantic.EXACTLY_ONCE 会尽一切可能不留下任何逗留的事务,否则会阻塞其他消费者从这个 Kafka topic 中读取数据。但是,如果 Flink 应用程序在第一次 checkpoint 之前就失败了,那么在重新启动此类应用程序后,系统中不会有任何关于之前KafkaProducer池大小的相关信息。因此,在第一次 checkpoint 完成前对 Flink 应用程序进行缩容,且并发数缩容倍数大于安全系数
FlinkKafkaProducer011.SAFE_SCALE_DOWN_FACTOR的值的话,是不安全的。
4 Kafka timestamp & EventTime
4.1 Consumer & Timestamp
从Kafka 0.10开始,只要配置了StreamExecutionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime),FlinkKafkaConsumer010就会在发送记录时附带上timestamp。
4.2 Watermark
但是Consumer不会发送watermark,需要显示使用watermark发送里提到的方法显示发送watermark。
4.3 Extract Timestamp
使用Kafka Timestamp时,无需再定义timestamp extractor,因为extractTimestamp方法的previousElementTimestamp参数已经包含了kafka消息的timestamp。
4.4 Producer & Timestamp
只有设置了 setWriteTimestampToKafka(true),则 FlinkKafkaProducer010 才会发出记录的时间戳。
FlinkKafkaProducer010.FlinkKafkaProducer010Configuration config = FlinkKafkaProducer010.writeToKafkaWithTimestamps(streamWithTimestamps, topic, new SimpleStringSchema(), standardProps);
config.setWriteTimestampToKafka(true);
5 更多例子
-
Flink官方-datastream_api
从预备知识、环境准备、工程构建、样例代码、代码分析、实战等多个方面详细介绍了datastream_api。代码展示了如何实现简单的DataStream应用,并且扩展为有状态的,还是用了时间概念。
6 源码分析
6.1 FlinkKafkaConsumer
6.2 FlinkKafkaProducer
6.2.1 TwoPhaseCommitSinkFunction
这里以org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer为例。
public class FlinkKafkaProducer<IN>
extends TwoPhaseCommitSinkFunction<IN, FlinkKafkaProducer.KafkaTransactionState, FlinkKafkaProducer.KafkaTransactionContext>
继承了一个重要的抽象类TwoPhaseCommitSinkFunction
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT>
extends RichSinkFunction<IN>
implements CheckpointedFunction, CheckpointListener
可看到该类又继承了RichSinkFunction和实现了Checkpoint相关接口。
6.2.2 RichFunction
特点:
-
用于用户定义的富UDF:
- 定义了关于富UDF的全生命周期
open
在调用主流程的如map、join之类的方法前调用本方法,可做一些初始化工作。close
在调用最后一个主流程方法如map、join后调用该方法,一般用来做清理工作。
- 访问富UDF运行上下文
org.apache.flink.api.common.functions.RuntimeContext的方法
RuntimeContext是UDF运行时上下文,且每个并形函数实例都有一个RuntimeContext。内容包含如方法并行度、子任务序号、任务名、Accumulators、广播变量等,使得函数方便访问这些静态的上下文信息。
一个RichFunction实现类例子如下:
public class MyFilter extends RichFilterFunction<String> { private String searchString; public void open(Configuration parameters) { this.searchString = parameters.getString("foo"); } public boolean filter(String value) { return value.equals(searchString); } } - 定义了关于富UDF的全生命周期
6.2.3 两阶段提交
这里讲讲FlinkKafkaProducer是怎么实现两阶段提交的,主要是通过TwoPhaseCommitSinkFunction等相关类和方法。
可参考
6.2.3.1 CheckpointedFunction
CheckpointedFunction可用initializeState方法定义初始时状态相关操作,以及用snapshotState方法定义Checkpoint快照时存储相关状态。
FlinkKafkaProducer语义采用Semantic.EXACTLY_ONCE时,会在Checkpoint时将一个批次所有发出的消息放在一个Kafka事务中保证原子性。
具体来说,会在此语义下初始化一个FlinkKafkaInternalProducer Pool,在每次Checkpoint之间会创建一个Kafka事务,并在notifyCheckpointComplete通知Checkpoint完成后提交该事务。如果该通知迟到了,则可能会导致FlinkKafkaInternalProducer池资源耗尽,此后snapshotState方法会失败导致Checkpoint也失败,此时会一直使用之前Checkpoint周期的FlinkKafkaInternalProducer。要减少这种失败,可以:
- 减少Checkpoint并发度
- 让Checkpoint过程更可控、更快速完成
- 增加两次Checkpoint间隔
- 增加
FlinkKafkaInternalProducerPool大小
TwoPhaseCommitSinkFunction#initializeState:
// 会调用`kafkaProducer.initTransactions()`
// kafkaProducer.beginTransaction
// currentTransactionHolder记录了本次Producer事务Id和时间
currentTransactionHolder = beginTransactionInternal();
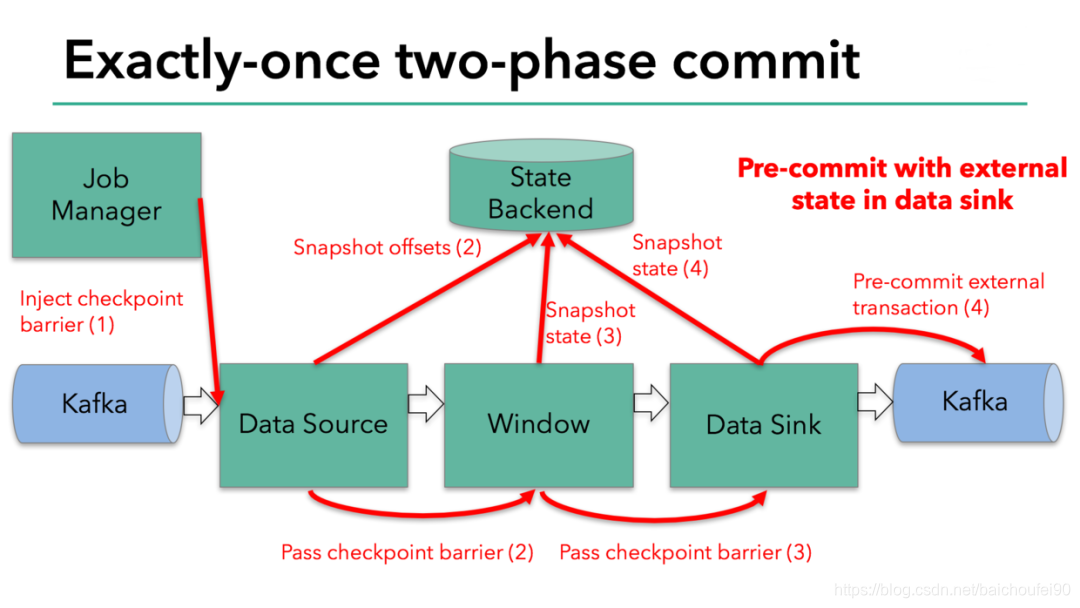
TwoPhaseCommitSinkFunction#snapshotState:就是执行两阶段提交中的第一阶段-PreCommit阶段
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// this is like the pre-commit of a 2-phase-commit transaction
// we are ready to commit and remember the transaction
// 本次快照checkpoint id
long checkpointId = context.getCheckpointId();
// 这是关键代码
// 会根据语义选择
// kafkaProducer 是直接flush kafka 事务
preCommit(currentTransactionHolder.handle);
// 记录本次checkpointId对应的事务状态信息,
// 包括transactionalId、producerId、epoch、KafkaProducer
pendingCommitTransactions.put(checkpointId, currentTransactionHolder);
// 这里会开启新的事务
// 即会调用`kafkaProducer.initTransactions()`
// kafkaProducer.beginTransaction
// 同时注意这里更新了currentTransactionHolder,也就是说还创建了新的FlinkKafkaInternalProducer
// 这个新的FlinkKafkaInternalProducer对应新的事务,用来在invoke时发送数据到kafka
currentTransactionHolder = beginTransactionInternal();
// Operator ListState
state.clear();
// 将pendingCommit状态的事务快照保存到State
state.add(new State<>(
this.currentTransactionHolder,
new ArrayList<>(pendingCommitTransactions.values()),
userContext));
}
上面的preCommit(transaction)->flush(transaction)实际会上执行transaction.producer.flush(),来看看该事务对应的FlinkKafkaInternalProducer#flush
@Override
public void flush() {
// 由于`kafkaProducer#send`为异步发送,所以这里调用flush确保本地缓存队列数据发送到Broker
kafkaProducer.flush();
if (transactionalId != null) {
synchronized (producerClosingLock) {
ensureNotClosed();
flushNewPartitions();
}
}
}
但需要注意,这里数据虽然已经flush到Broker端,但此时如果KafkaConsumer的事务隔离级别isolation.level为read_committed则看不到未提交的这批事务中的数据
6.2.3.3 CheckpointListener
- CheckpointListener有一个
notifyCheckpointComplete定义Checkpoint成功后执行的逻辑。
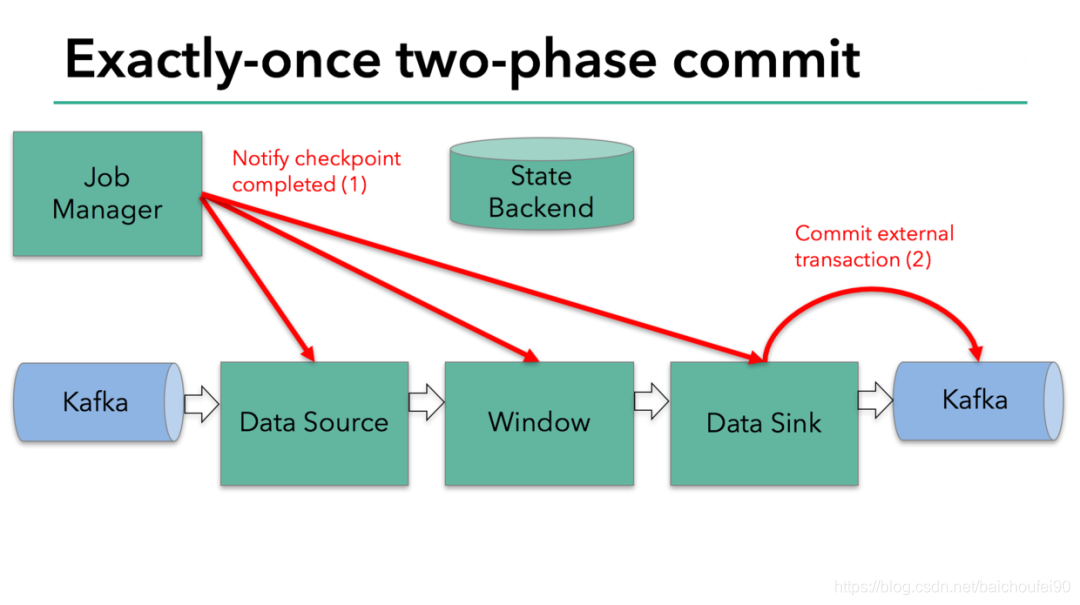
FlinkKafkaProducer在收到notifyCheckpointComplete调用时,即表示Flink JM已经收集到所有算子完成状态快照信息,此次Checkpoint完成,需要大家进行Commit,即第二阶段提交:
@Override
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
Iterator<Map.Entry<Long, TransactionHolder<TXN>>> pendingTransactionIterator = pendingCommitTransactions.entrySet().iterator();
Throwable firstError = null;
while (pendingTransactionIterator.hasNext()) {
// <checkpointId, TransactionHolder>
Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();
Long pendingTransactionCheckpointId = entry.getKey();
TransactionHolder<TXN> pendingTransaction = entry.getValue();
if (pendingTransactionCheckpointId > checkpointId) {
// 如果该pendingCheckpointId比当前成功的checkpointId更大,则说明是后面的,现在不处理
continue;
}
try {
// 提交该事务
// 其实就是调用transaction.producer.commitTransaction();
commit(pendingTransaction.handle);
} catch (Throwable t) {
if (firstError == null) {
firstError = t;
}
}
// 移除已经commit的事务记录
pendingTransactionIterator.remove();
}
}
在commit以后Consumer便能看到已提交的事务数据。
6.2.3.4 Exactly-Once 分析
考虑 Kafka->Flink->Kafka的简单场景,KafkaConsumer使用OffsetCommitMode.ON_CHECKPOINTS模式
-
阶段1-preCommit
- FlinkKafkaConsumer保存offset到状态快照
- FlinkKafkaProducer将此次Checkpoint对应事务缓存中的数据刷入Kafka Broker但未提交事务,并开启新的事务给后面的数据生产时使用。
-
阶段2-commit
- FlinkKafkaConsumer提交Offset到Kafka,这个数据只会被用来做监控使用
- FlinkKafkaProducer提交事务,对其他消费者可见
-
如果阶段1任何一个发生失败,则回滚到上次Checkpoint,则这段时间消费的数据不会被提交事务
保证不会多数据 -
如果阶段2FlinkKafkaConsumer Commit失败,则会被重复提交Offset直到成功
-
如果阶段2FlinkKafkaProducer Commit失败,则会被重复提交事务直到成功
保证不会少数据
所以无论怎样都不会有重复数据或丢数据,实现了精准一次。















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









