




 本文深入探讨Elasticsearch中Doc(文档)与Segment(段)的工作原理,包括Doc的元数据、底层机制,以及如何通过Segment进行索引、删除和更新操作,揭示了Elasticsearch高效搜索背后的秘密。
本文深入探讨Elasticsearch中Doc(文档)与Segment(段)的工作原理,包括Doc的元数据、底层机制,以及如何通过Segment进行索引、删除和更新操作,揭示了Elasticsearch高效搜索背后的秘密。
Elasticsearch学习-Doc与Segment原理
0x00 系列文章目录
0x01 摘要
本文主要讲下ES中Doc(文档)和Segment(段)的底层原理。
0x02 Doc概念
2.1 术语介绍
首先我们说几个ES中跟Doc相关的概念,以免后面混淆:
- Index(索引)
这里指ES的索引概念,有1个或多个type,由若干shard分片组成 - Shard(分片)
是一个Lucene索引。一个ES Index分为多个Shard,可分布到不同节点上 - Doc(文档)
ES中的最小的、整体的数据单位,比如一条用户订单信息是一个Doc。一个index中存放了很多Doc - Lucene Index
注意和Es Index区别。Lucene Index是由若干段和提交点文件组成。 - Segment(段)
Lucene里面的一个数据集概念 - 提交点
有一个列表存放着所有已知的所有段
2.2 Doc简介
根据ES官网文档说法,术语“文档”具有特定含义。 它指的是序列化为JSON并以唯一ID存储在Elasticsearch中的顶级或根对象。
2.3 Doc元数据
Doc中包括以下几个重要字段:
- _source
Doc的内容主体 - _index
Doc从属的索引名称 - _type
Doc从属的type名称,6.x版本中被废弃 - _id
就像人的身份证号一样,_id是Doc的唯一编号
更多元数据字段可以点击这里
2.4 Doc底层原理简述
前面说过ES中的文档是带有字段和值的结构化JSON文档,对于每个被索引字段(field)都有自己的倒排索引。关于倒排索引更多信息可以点击这里。
注意,因为倒排索引被写入磁盘后是不可变的,而后会在使用时读入文件系统缓存,加快查询速度。如果你想修改一个Doc,那就必须重建整个待排索引。
ES解决不变形和更新索引的方式是使用多个索引,利用新增的索引来反映修改,在查询时从旧的到新的依次查询,最后来一个结果合并,perfect。
ES底层是基于Lucene,最核心的概念就是Segment(段),每个段本身就是一个倒排索引。
ES中的Index由多个段的集合和commit point(提交点)文件组成。
提交点文件中有一个列表存放着所有已知的段,下面是一个带有1个提交点和3个段的Index示意图:

0x03 Doc新增
3.1 Doc提交过程
Doc提交主要过程如下:
3.1.1 Doc写入Buffer
Doc会先被搜集到内存中的Buffer内,这个时候还无法被搜索到,如下图所示:

3.1.2 Doc Commit
每隔一段时间,会将buffer提交,在flush磁盘后打开新段使得搜索可见,详细过程如下:
- 创建一个新段,作为一个追加的倒排索引,写入到磁盘(文件系统缓存)
- 将新的包含新段的Commit Point(提交点)写入磁盘(文件系统缓存)
- 磁盘进行
fsync,主要是将文件系统缓存中等待的写入操作全部物理写入到磁盘,保证数据不会在发生错误时丢失 - 这个新的段被开启, 使得段内文档对搜索可见
- 将内存中buffer清除,又可以把新的Doc写入buffer了
下面展示了这个过程完成后的段和提交点的状态:

通过这种方式,可以使得新文档从被索引到可被搜索间的时间间隔在数分钟,但是还不够快。因为磁盘需要fsync,这个就成为性能瓶颈。我们前面提到过Doc会先被从buffer刷入段写入文件系统缓存(很快),那么就自然想到在这个阶段就让文档对搜索可见,随后再被刷入磁盘(较慢)。
3.2 refresh
Lucene支持对新段写入和打开-可以使文档在没有完全刷入硬盘的状态下就能对搜索可见,而且是一个开销较小的操作,可以频繁进行。
下面是一个已经将Docs刷入段但还没有完全提交的示意图:

我们可以看到,新段虽然还没有被完全提交,仍然还在文件系统缓存中,但是已经对搜索可见了。
这种对新段的巧妙操作过程被称为refresh,默认执行的时间间隔是1秒,这就是ES被称为近实时搜索的原因。
可以使用refreshAPI进行手动操作,但一般不建议这么做。还可以通过合理设置refresh_interval在近实时搜索和索引速度间做权衡,点击这里查看详情
3.3 translog
3.3.1 带有translog的文档索引流程
为了避免在两次commit操作间隔时间发生异常导致Doc丢失,ES中采用了一个和HBase中WAL log类似概念的translog,成为事务日志记录每次对ES的操作。加上translog后新增文档流程如下:
- 文档被添加到buffer同时追加到translog(先写translog),如图:

- 进行
refresh操作,清空buffer,文档可被搜索但尚未flush到磁盘。translog不会清空,如图:

- 继续步骤1的过程
- 每隔一段时间(例如translog变得太大),index会被flush到磁盘,新的translog文件被创建,这个commit完整执行结束。在这个操作后,会发生以下事件:
- 所有内存中的buffer会被写入新段
- buffer被清空
- 一个提交点被写入磁盘
- 文件系统缓存通过
fsyncflush到磁盘 - 之前的旧translog被删除
下面示意图展示了这个状态:

3.3.2 translog的作用
通过前文描述我们知道translog其实就记录了还尚未被flush到磁盘的操作。
当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过ID来RUD一个Doc,它会在从相关的段检索之前先检查 translog 中最新的变更。
3.3.3 translog的安全性
默认translog是每5秒或是每次请求完成后被fsync到磁盘(在主分片和副本分片都会)。也就是说,如果你发起一个index, delete, update, bulk请求写入translog并被fsync到主分片和副本分片的磁盘前不会反回200状态。
这样会带来一些性能损失,可以通过设为异步fsync,但是必须接受由此带来的丢失少量数据的风险:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
关于translog的更多信息,请点击这里
3.4 flush
flush就是执行commit清空、干掉老translog的过程。默认每个分片30分钟或者是translog过于大的时候自动flush一次。可以通过flush API手动触发,但是只会在重启节点或关闭某个索引的时候这样做,因为这可以让未来ES恢复的速度更快(translog文件更小)。
0x04 Doc删除
4.1 ES对Doc删除的处理
删除一个ES文档不会立即从磁盘上移除,它只是被标记成已删除。因为段是不可变的,所以文档既不能从旧的段中移除,旧的段也不能更新以反映文档最新的版本。
ES的做法是,每一个提交点包括一个.del文件(还包括新段),包含了段上已经被标记为删除状态的文档。所以,当一个文档被做删除操作,实际上只是在.del文件中将该文档标记为删除,依然会在查询时被匹配到,只不过在最终返回结果之前会被从结果中删除。ES将会在用户之后添加更多索引的时候,在后台进行要删除内容的清理。
4.2 Doc删除与段合并的关系
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了,每个段消费大量文件句柄,内存,cpu资源。更重要的是,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
ES通过后台合并段解决这个问题。ES利用段合并的时机来真正从文件系统删除那些version较老或者是被标记为删除的文档。被删除的文档(或者是version较老的)不会再被合并到新的更大的段中。
ES对一个不断有数据写入的索引处理流程如下:
- 索引过程中,refresh会不断创建新的段,并打开它们。
- 合并过程会在后台选择一些小的段合并成大的段,这个过程不会中断索引和搜索。合并过程如图:
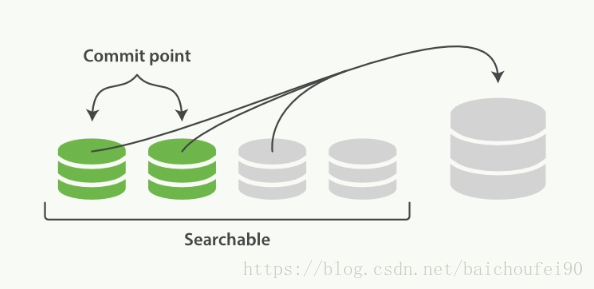
图:两个已提交的段 和一个未提交的段合并为一个更大的段
从上图可以看到,段合并之前,旧有的Commit和没Commit的小段皆可被搜索。
- 段合并后的操作:
- 新的段flush到硬盘
- 编写一个包含新段的新提交点,并排除旧的较小段。
- 新的段打开供搜索
- 旧的段被删除
合并完成后新的段可被搜索,旧的段被删除,如下图所示:

注意:段合并过程虽然看起来很爽,但是大段的合并可能会占用大量的IO和CPU,如果不加以控制,可能会大大降低搜索性能。关于此项调优会有专门文章讲到,官方文章请点击这里。
段合并的optimize API 不是非常特殊的情况下千万不要使用,默认策略已经足够好了。不恰当的使用可能会将你机器的资源全部耗尽在段合并上,导致无法搜索、无法响应
0x05 Doc更新
文档的更新操作和删除是类似的:当一个文档被更新,旧版本的文档被标记为删除,新版本的文档在新的段中索引。
该文档的不同版本都会匹配一个查询,但是较旧的版本会从结果中删除。
0xFE 总结
本文主要分析了ES中的Doc和其底层的段的原理和他们之间的关系,相信看了本文大家可以对这一部分了解更深。


















 304
304




 到【灌水乐园】发言
到【灌水乐园】发言







