







文章代码来源:《deep learning on keras》,非常好的一本书,大家如果英语好,推荐直接阅读该书,如果时间不够,可以看看此系列文章。
这次我们要讲的东西是一个一般的攻击和解决任何机器学习问题的蓝图,将你在本章学到的:问题定义、评估、特征工程、解决过拟合全部联系起来。
定义问题和组装数据集
首先,你必须这样定义手头的问题:
- 你要输入的数据是什么样子?你想要预测的是什么?你只能预测某些事情,例如你在电影评论和感情注释数据都有的时候可以来对电影的评论进行分类。常常数据是限制因素(除非你有方法去让被人帮你手机数据)
- 你手头面临的是什么类型的问题,是二分类吗?多分类吗?标量回归问题吗?向量回归问题吗?多分类多标签分类问题吗?还有一些其它的,如积累,泛化或是强化学习?弄清这些问题类型将会引导你选择模型框架,损失函数等等。
在你弄清输入输出是什么和你要用什么数据之前, 你是无法到下一阶段的。注意下面这些假设: - 你假设你的输出能被你所给的输入所预测
- 你假设你的数据已经足以解释输入和输出之间的关系。
在你有有效的模型之前,这些都只不过是假设罢了,等到被证实或是被证伪。不是所有的问题都能被解决;因为你将输入X和预测Y相组装,这不意味着X包含足够的用来预测Y的信息。举个例子,如果你尝试股票的动态通过股票市场所给出的最近的价格历史,你是不太可能会成功的,因为价格历史就没包含什么可预测信息。
一种你需要特别注意的未解决的问题是非平稳问题。假设你试着做一款衣服推荐引擎,你训练了一个月的数据,八月的,然后你就像开始泛化推荐冬天的。一个大的问题是人们买的衣服的类型随着季节在变,也就是说一幅购买在很少的月份来看不是一个固定的现象。你尝试改变模型。这样一来最好的的方法是不断地训练你最近采集到的数据,或者将问题固定的数据聚起来。对于一些周期问题,例如买衣服,只需要几年的数据就足以捕获到季节的变化,但是你应当记住让时间成为你模型输入的一部分。
记住:机器学习只能记住你在训练数据里面表达的特征。你也只能识别你见过的东西。使用机器学习训练过去的数据来预测将来是基于假设:未来和过去表现会比较相似。然而常常并不是酱紫的。
选择成功的度量
为了控制某个东西,你需要观察它。为了获得成功,你需要定义成功的度量,是准确率?召回精度?客户保留率?你的成功的度量将会指导你选择损失函数,也就是你模型要优化的东西。这度量应当和你高级目标相对齐,比如说你企业的成功。
对于平衡分类问题,每一个类都是等可能的,准确率和roc-auc是常用的度量。对于非均衡分类问题,可能会使用准确率召回。对于排序问题或是多样本分类,将会用平均预测。用你度量成功的方法来定义你的客户的度量并不少见。为了得到机器学习的成功度量的意义以及他们是如何和不同领域的问题联系起来的,在kaggle.com
决定评估方案
一旦你知道你的目标,你就必须建立如何衡量当前的进度。我们有三种常见的评估方案:
- 保持一个不变的验证集;这当你有很多数据的时候这是一个方法。
- 做k-fold交叉验证;这是当你的数据样本太少的时候采取的方法。
- 做循环k-fold验证;这是为了少样本时提高模型估计。
直接选其中一个;在大多数情况,第一种就已经表现得足够好了。
准备你的数据
一旦你知道你在训练什么数据,你在优化什么,以及如何评估你的方法,你已经准备好开始训练模型了。但是,你首先应当把你的数据的格式处理到能够喂进机器学习模型——这里我们假设是深度神经网络。
- 正如我们之前看到的,你的数据应当格式化成张量。
- 这些张量中的值应当被化为小的值。
- 如果不同的特征在不同的范围变化,那么应当标准化。
- 你或许想要做一些特征工程,特别是对于小数据问题。
一旦你的输入张量和目标数据准备好了,你就可以开始训练模型了。
发展一个模型使得比基础的做得好
你的目标是达到“统计功效”,即弄一个小模型来对抗原来的小的。在MNIST数字分类例子中,任何准确率高于0.1的都可以说是具有统计功效的;在我们IMDB例子中就需要高于0.5。
注意,不是总是能达到统计功效。如果你不能击败原来的基础版本的,在试了很多可能的结构以后,这可能是问题的答案在输入数据中就没有。记住你做了两个假设:
- 你假设你的输出能够被你的输入预测
- 你假设你给的数据已经足够学习输入和输出之间的关系了。
可能这些假设是错的,这样的话,你就必须回头回到原来的画板上。
假设一切顺利,这里有三个关键的选择,你需要做的,来建立你的第一个模型:
- 最后一层激活函数的选择。这对网络的输出做了有用的限制:例如我们的IMDB分类例子中我们使用sigmoid在最后一层,在回归例子中,我们没有用任何激活函数。
- 选择损失函数。这就应当匹配你试图解决的问题的类型了:在IMDB分类例子中我们使用二交叉,在回归例子中我们使用最小均方误差。
- 选择优化模块:用什么样的优化器?学习率是什么?在大多数情况,使用rmsprop和其学习率很安全。
说到选择损失函数:注意直接优化度量问题成功的很亮不总是可行的。有时没有捷径来将度量转化为损失函数;损失函数只有在少量样本数据可以被计算(理想情况下,一个损失函数应当对于像一个点那样少的数据都可计算)并且需要可区分。(否则你无法使用向后传播来训练你的网络)。举个例子,广泛用于分类度量的roc-auc不能直接被优化。因此在分类任务中去优化roc-auc的替代品很常见,比如交叉熵。一般的,交叉熵越低,roc-auc就越高。
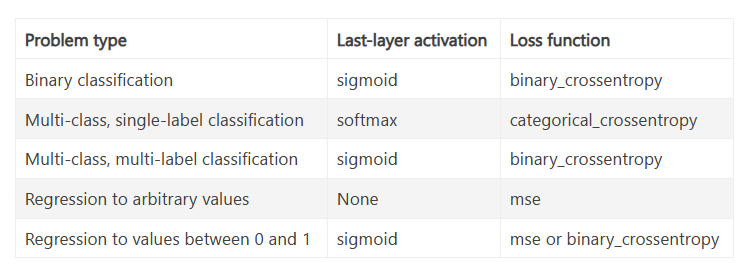
这里给了一张表格,来帮助你选择最后一层的激活函数和损失函数在一些常见的问题类型上。
按比例放大:改进过拟合模型
一旦你得到了一个有统计功效的模型,这问题就变成了:你的模型是否足够有效?手头有足够多的层数和参数来适当的对问题建模吗?例如,一个有单个隐藏层,两个独立单元的网络对MNIST具有统计功效,但还不足以很好的解决问题。记住,一般的机器学习中的张力介于优化和泛化之间;理想的模型是在过拟合和欠拟合的边界上,同时也在容量不足和容量冗余的边界上。为了弄清楚边界在哪里,你必须通过它。
为了弄清楚你究竟需要多大的模型,你必须改进一个过拟合的模型,这相当的简单:
- 加层数
- 让你的层更大
- 训练更多的批次
持续监察训练损失和验证损失,以及在任意你关心的度量下训练和验证值。当你看到模型在验证数据开始下降时,你就已经开始过拟合了。
正则化你的模型并调节超参数
这将是花你最多时间的部分:你将会反复修改你的模型,训练它,在验证集上评估,再修改直到你的模型能表现得如它能做到的那么好为止。
这里有很多事情你应当去尝试:
- 加dropout
- 尝试不同的结构,加或者移除层
- 加L1/L2正则化
- 尝试不同的超参数(例如每一层的单元数,优化器的学习速率)来寻找优化结构
- 在特征工程的基础上优化迭代:加新的特征,移除那些看着没有信息量的特征。
时刻牢记如下:每次你使用你验证集的带的反馈来调节你的模型的时候,你就在将验证集的数据渗透进你的模型。重复少数几次,无伤大雅,但是系统地循环了很多次以后最终就会导致你的模型对于验证集来说过拟合(尽管没有任何验证数据直接在模型上训练)这将会使你的评估不再那么可靠,记住这个。
一旦你改进出了一个足够好的模型,你能在训练集和验证集上训练并在最后放在测试集上评估。如果在测试集上的表现明显比在验证集上的表现差,这就说明的你的验证集不是那么可靠的,或者说在调参的时候使得模型在验证集上过拟合了。在这种情况下,你可能想要改用一些更加可靠的评估方法(如循环k-fold验证)
总的来说,这是机器学习的一般流程:
- 1)定义手头你要去训练的问题和数据;收集数据或标注标签如果需要的话。
- 2)选择如何成功衡量你的问题,什么样的度量是你的验证集需要监控的。
- 3)弄清楚你的评价协议:持续验证?k-flod验证?你应当拿哪一部分来验证?
- 4)改进模型使得比原始模型表现好,让模型具有统计功效。
- 5)改进过拟合的模型
- 6)正则化你的模型,并调节其超参数,基于验证集的表现。
大多数的机器学习研究都倾向于集中注意力在最后一步——但需要牢记这个大的框架。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









