







先定位找到元素,然后,才能操作元素
常见的操作(如果定位的是一个元素可以使用):
点击元素, click() 方法
元素内输入文本, fill() 方法
获取元素内部文本, inner_text() 方法
如果定位到的是多个元素用 .all() 获取列表后在遍历使用Locator 对象
根据 tag名 、 id 属性 和 class属性 来 选择元素
locators = page.locator('div') # 直接标签名
locators = page.locator('#id名') # #号 加上id名
locators = page.locator('.class名') # .点 加类名
# 同时有多人class名: chinese 或 student
<span class="chinese student">张三</span>
page.locator('.chinese.student') # 可定位一个# 如果定位到多个元素 .all()获取全部元素, 在遍历
locators = page.locator('div').all()
for one in locators:
print(one.inner_text())
# 或打印全部
#texts = page.locator('div').all_inner_texts()验证 CSS Selector
开发者工具栏 ---- > F12 ----->Ctr + F
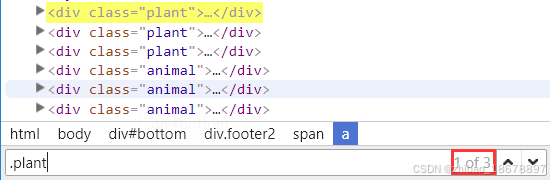
匹配多个元素
locators = page.locator('.plant').all()
# 如果只是想知道有多少个匹配的值
count = page.locator('.plant').count()
# 匹配到的元素第一个 first 与最后一个 last
lct = page.locator('.plant')
print(lct.first.inner_text(), lct.last.inner_text())
# nth 指定匹配位置,从0开始
lct = page.locator('.plant')
print(lct.nth(1).inner_text())
元素内部定位
lct = page.locator('#bottom') #从网页上找到对象后实例化
# 在 #bottom 对应元素的范围内 寻找标签名为 span 的元素。
eles = lct.locator('span').all()
for e in eles:
print(e.inner_text())选择 子元素 > 和 后代元素 空格
元素 内部可以 包含其他元素

如果 元素2 是 元素1 的 直接子元素, CSS Selector 选择子元素的语法是这样的
元素1 > 元素2 > 元素3 > 元素4
如果 元素2 是 元素1 的 后代元素, CSS Selector 选择后代元素的语法是这样的
元素1 元素2 元素3 元素4
根据属性选择 [ ]
<a href="https://www.baidu.com/">百度一下</a># 根据属性选择元素
element_1 = page.locator('[href="https://www.baidu.com"]') # 属性等于指定值
element_2 = page.locator('a[href="https://www.baidu.com"]') # a标签中,并且是指定值
element_3 = page.locator('[href]') # 所有指定属性
element_4 = page.locator('a[href*="baidu"]') # 包含指定字符串的指定值
element_5 = page.locator('a[href$=".com"]') # 指定字符结尾
element_6 = page.locator('a[href^="http"]') # 指定字符开头<div class="misc" ctype="gun">沙漠之鹰</div>element_6 = page.locator('div[class=misc][ctype=gun]') # 指定多个属性选择语法联合使用
element_7 = page.locator(".footer1 > .copyright[name=cp1]")
1.定位 footer1 类
2.直接下阶的子元素 copyright 类
3.中属性名有叫 name=cp1组选择 逗号
element_8 = page.locator(".footer1,#copyright") # 同时选择多个(选了一个类与id)
element_9 = page.locator("#t1 > span,p") # 选择定义ID下的所有的span,与单独的p标签
element_10 = page.locator("#t1 > span,#t1 > p") # 分别选ID下的span 与 P按次序选择子节点
父元素的第n个子节点 nth-child
# 选择的是 第2个子元素,并且是span类型
span:nth-child(2)
# 如果你不加节点类型限制,直接这样写 :nth-child(2)
# 就是选择所有位置为第2个的所有元素,不管是什么类型父元素的倒数第n个子节点 nth-last-child
# 选择的是 倒数第1个子元素,并且是 p 类型
p:nth-last-child(1)父元素的第几个某类型的子节点 nth-of-type
# 可以像上面那样思考:选择的是 第2个子元素,并且是span类型
# 所以这样可以这样写 span:nth-child(2) ,
# 还可以这样思考,选择的是 第1个span类型 的子元素
# 所以也可以这样写 span:nth-of-type(1)父元素的倒数第几个某类型的子节点 nth-last-of-type
# 选择父元素的 倒数第几个某类型 的子节点
p:nth-last-of-type(2)奇数节点和偶数节点
如果要选择的是父元素的 某类型偶数节点,使用 nth-of-type(even)
如果要选择的是父元素的 某类型奇数节点,使用 nth-of-type(odd)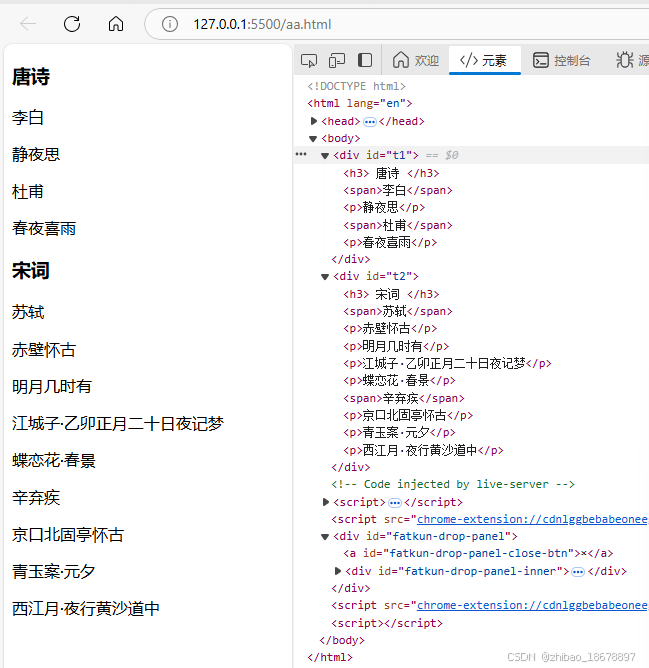
# -*- coding: utf-8 -*-
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('http://127.0.0.1:5500/aa.html')
# 父元素的第n个子节点
# 选择的是 第2个子元素,并且是span类型
loc = page.locator('span:nth-child(2)').all_inner_texts()
# 打印结果
print('选择的是 第2个子元素,并且是span类型')
print(loc)
# 父元素的倒数第n个子节点
# 选择的是 倒数第1个p元素,并且是p类型
loc2 = page.locator('p:nth-last-child(1)').all_inner_texts()
# 打印结果
print('选择的是 倒数第1个p元素,并且是p类型')
print(loc2)
print('------------------------------------------------')
# 父元素的第几个某类型的子节点
loc3 = page.locator('span:nth-of-type(1)').all_inner_texts()
print('选择的是 父元素的第1个span元素')
print(loc3)
# 选择父元素的 倒数第几个某类型 的子节点
loc4 = page.locator('p:nth-last-of-type(1)').all_inner_texts()
print('选择的是 父元素的倒数第1个p元素')
print(loc4)
print('------------------------------------------------')
# 奇数节点和偶数节点
loc5 = page.locator('span:nth-child(odd)').all_inner_texts()
print('选择的是 父元素的奇数子元素')
print(loc5)
loc6 = page.locator('span:nth-child(even)').all_inner_texts()
print('选择的是 父元素的偶数子元素')
print(loc6)
browser.close()

兄弟节点选择
相邻兄弟节点选择 +
选择 h3 后面紧跟着的兄弟节点 span
h3 + span后续所有兄弟节点选择 ~
如果要选择是 选择 h3 后面所有的兄弟节点 span
h3 ~ spanfrom playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('http://127.0.0.1:5500/aa.html')
# 相邻兄弟节点选择
loc = page.locator('h3+span').all_inner_texts()
print('相邻兄弟节点选择')
print(loc)
# 后续所有兄弟节点选择
loc = page.locator('h3~span').all_inner_texts()
print('后续所有兄弟节点选择')
print(loc)
browser.close()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









