







前言
Once is an object that will perform exactly one action.
sync.Once是Go语言中sync包提供的一种同步原语,用于执行且只会执行一次的动作,通常用于单例对象的初始化等场景。
在Go 1.18中,sync.Once的有效代码只有14行,非常简洁。
虽然有很多关于sync.Once的介绍文章,但大多数都是从某个版本的源码进行解释,少有文章解释作者是如何编写这段优秀代码以及其中的思考过程。因此,本文通过作者提交源代码的Git记录,尝试分析实现一个once语义的优化过程,来帮助读者更好地理解sync.Once。
这是一段go1.18版本中的源码,非常短小精悍,也很容易看懂:
package sync
import (
"sync/atomic"
)
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}不过阅读之后,却产生一些疑问:
-
为啥源码引入Mutex而不是CAS操作
-
为啥要有fast path, slow path
-
加锁之后为啥要有done==0,为啥有double check,为啥这里不是原子读
-
使用atomiic store的地方为啥要加defer
-
为啥是atomic.store,不是直接赋值1
读到这里,大家不妨也尝试思考并回答上面的一些疑问!
代码进化过程
Once开始的地方
type Once struct {
m Mutex
done bool
}
func (o *Once) Do(f func()) {
o.m.Lock()
defer o.m.Unlock()
if !o.done {
o.done = true
f()
}
}这是2010.8.15日作者提交的代码,在这段代码中,作者借助Mutex 实现Once语义,执行的时候先加一把互斥锁,保证只有一个协程操作 done变量,等f()函数执行完解锁。
这段代码怎么说呢,能用,但还是稍微有些粗糙,一个最显而易见的缺点:每次都要执行Mutex加锁操作,对于Once这种语义有必要吗,是否可以先判断一下done的value是否为true,然后再进行加锁操作呢?
第一次优化
于是Once开始了第一次进化,这次优化改进了上面提到的问题:若Once已经初始化,那么Do内部将不会执行抢锁操作。
做这份代码改动的哥们经过benchmark测试发现,这样的改法在不同核的benchmark中耗时大约降低92%-99%。
下面这段代码是其改进:
type Once struct {
m Mutex
done int32
}
func (o *Once) Do(f func()) {
if atomic.AddInt32(&o.done, 0) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
f()
atomic.CompareAndSwapInt32(&o.done, 0, 1)
}
}在这段代码中,在slow-path加锁后,要继续判断done值是否为0,确认done为0后才要执行f()函数,这是因为在多协程环境下仅仅通过一次atomic.AddInt32判断并不能保证原子性!
比如有协程g1、g2,g2在g1刚刚执行完atomic.CompareAndSwapInt32(&o.done, 0, 1)进入了slow-path,如果不进行double check,那g2又会执行一次f()。这与所谓的双重锁检查基本类似。
在这次改动中,作者用一个int32变量done表示once的对象是否已执行完,有两个地方使用到了atomic包里的方法对o.done进行判断。分别是,用AddInt32函数根据o.done的值是否为1判断once是否已执行过,若执行过直接返回;f()函数执行完后,对o.done通过cas操作进行赋值1。
这两处地方的存在有一定的争议性,在源码CR的过程中就被问到atomic.CompareAndSwapInt32(&o.done, 0, 1)可否被o.done == 1替换?
答案是不可以。
现在的CPU一般拥有多个核心,而CPU的处理速度快于从内存读取变量的速度,为了弥补这俩速度的差异,现在CPU每个核心都有自己的L1、L2、L3级高速缓存,CPU可以直接从高速缓存中读取数据,但是这样一来内存中的一份数据就在缓存中有多份副本,在同一时间下这些副本中的可能会不一样,
为了保持缓存一致性,Intel CPU使用了MESI协议。AddInt32方法和CompareAndSwapInt32方法(均为amd64平台 runtime/internal/atomic/atomic_amd64.s)底层都是在汇编层面调用了LOCK指令,LOCK指令通过总线锁或MESI协议保证原子性(具体措施与CPU的版本有关),提供了强一致性的缓存读写保证,保证LOCK之后的指令在带LOCK前缀的指令执行之后才执行,从而保证读到最新的o.done值。
至此Once的代码基本成型。
第二次优化
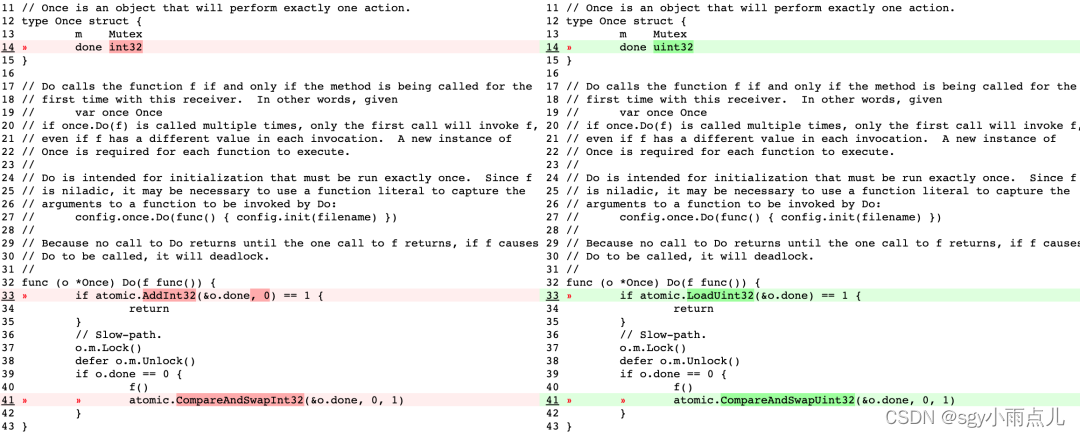
这个小优化把done的类型由int32替换为uint32,用CompareAndSwapUint32替换了CompareAndSwapInt32, 用LoadUint32替换了AddInt32方法。
原因是,AddInt32原子操作被用来递增状态变量的值。这个操作不仅会递增状态变量的值,还会返回递增前的值。然而,在sync.Once的上下文中,我们只关心状态变量是否已经被设置过,而不需要关心它的具体值。这就导致了在使用AddInt32时,我们需要额外处理返回的递增前的值,以判断是否已经执行过。
为了提高代码的可读性,作者决定将AddInt32替换为LoadUint32。LoadUint32操作只会加载状态变量的值,而不会修改它。这样,我们可以更清晰地表达我们只关心状态变量的当前值,而不需要额外的递增操作。
此外,使用LoadUint32也可能带来一些性能上的优势。在某些硬件平台上,对uint32类型的变量进行加载操作可能比递增操作更快。这是因为加载操作可以更直接地从内存中读取值,而递增操作可能需要进行额外的运算。通常,对内存中的单个字节进行读取操作比写入操作更快。例如,当我们需要读取一个字节时,硬件可以更快地完成这个操作,因为它只需要读取一个字节的数据。而当我们需要写入一个字节时,硬件可能需要执行更多的操作,例如读取整个字节,然后将其与要写入的字节进行合并,最后再一次性写入整个字节。
这次优化经过benchmark测试性能在不同核心上有45%-94%的提升。
第三次优化

这次小优化用StoreUint32替换了CompareAndSwapUint32操作,CAS操作在这里确实有点多余,因为这行代码最主要的功能是原子性的done = 1。
Store命令的底层,其中关键的指令是XCHG,有的同学可能要问了,这源码里没有LOCK指令啊,怎么保证happen before呢,Intel手册有这样的描述: The LOCK prefix is automatically assumed for XCHG instruction.,这个指令默认带LOCK前缀,能保证Happen Before语义。
TEXT runtime∕internal∕atomic·Store(SB), NOSPLIT, $0-12
MOVQ ptr+0(FP), BX
MOVL val+8(FP), AX
XCHGL AX, 0(BX)
RET第四次优化

这次的优化在StoreUint32前增加defer前缀,增加defer是保证 即使f()在执行过程中出现panic,Once仍然保证f()只执行一次,这样符合严格的Once语义。
除了预防panic,defer还能解决指令重排的问题:现在CPU为了执行效率,源码在真正执行时的顺序和代码的顺序可能并不一样,比如这段代码中a不一定打印"hello, world",也可能打印空字符串。
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}而增加了defer前缀,能保证即使出现指令重排,done变量也能在f()函数执行完后才进行store操作。
第五次优化
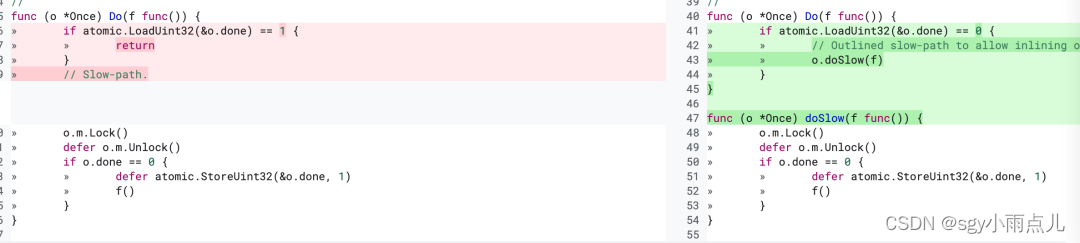
这次优化主要是用函数区分开了fast path和slow path,对fast path做了内联优化。这样进一步降低了使用Once的开销,因为fast path会被内联到使用once的函数调用中,每次调用的时候如果只走到fast path那么连函数调用的开销都省去了,这次优化在不同核的环境下又有54%-67%的提升。
总结
优秀的代码总是经过各种打磨,并非一蹴而就。通过仔细分析Git提交记录,我们可以更好地理解sync.Once的实现过程和思考方式,加深理解。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









