






前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2023年文章合集发布了!在这里:又添十万字-CS的陋室2023年文章合集来袭
往期回顾
今天聊一篇被发布在RecSys24上的论文,旨在用大模型来对推荐系统进行优化,该篇文章的思路和目前比较普遍意义的大模型应用于推荐系统的思路紧密相关,因此我认为有必要分享一下这篇论文。
论文信息:
Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models
https://arxiv.org/abs/2306.10933
讲解:https://zhuanlan.zhihu.com/p/26617306268
仔细看论文的时间点同样比较早,是23年左右,虽说已经不算比较新的论文了,但这篇文章的思路还有不小的借鉴意义。
背景
KAR
核心思想
知识推理和生成
知识适配
知识利用
加速策略
实验
小结
背景
探索大模型和推荐系统应用的文章,多半都离不开一个课题——大模型加入后的价值在何处,本文所给的答案是,大模型能够提供对世界知识的支持:
Recently, the emergence of large language models (LLMs) has shown promise in bridging this gap by encoding extensive world knowledge and demonstrating reasoning capability.
论文指出,现在很多推荐系统的研究,大都聚焦在领域内信息的训练,主要是用户行为、用户物料的信息理解等,然后根据这些交互行为来推测偏好和各种未来行为,有一定局限性。
然而,在当时对这方面的研究还有不小的局限性,预测准确性不足、推理延迟高、组合性差距(大模型难以生成复合问题的正确答案),这些问题,很多也是目前还在面对的难题。
因此,作者提出了一种KAR的方案(Knowledge Augmented Recommendation)的思路,这里作者提到文章的3大贡献:
KAR框架。这是一种把LLMs的逻辑推理能力和世界知识加入到推荐系统重的框架。
能把世界知识转化为推荐空间的密集向量。
知识增强可以预处理并存储,以实现快速训练和推理。
KAR
核心思想
有文章评论道,KAR的思路和RAG有异曲同工之妙,RAG是借助巨大知识库进行检索并送予大模型的方式,以便大模型做出更准确的回复,而KAR则是借助大模型的世界知识,为推荐系统提供更丰富的推荐依据。
那么LLMs的知识如何抽取、如何利用则成为了非常重要的问题,文章通过下面3个阶段的应用来体现:
知识的推理和生成。设计了分解提示(factorization prompting)从LLMs中提取了用户偏好的推理知识和物料的事实知识。
知识适配。将文本知识转化为稠密表示,并使用混合专家适配器(hybrid expert adaptor)将其转化到推荐空间内,方便使用。
知识应用。将适配的知识应用到推荐模型中。
整个框架如图所示:
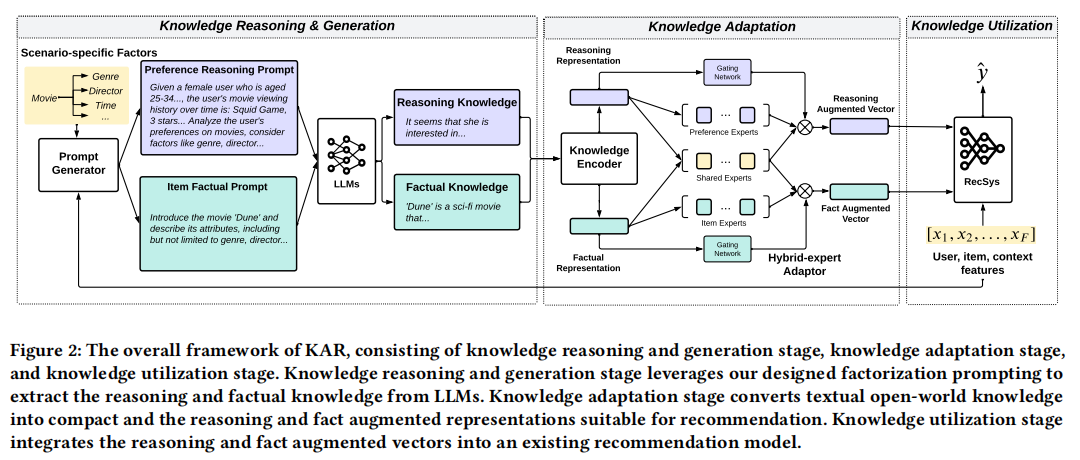
知识推理和生成
对于推荐系统,比较朴素的方式就是直接把用户和物料的信息一起扔进大模型内进行推理,这无疑是最省事的方法了,然而实践下来效果并不好,作者分析的原因有这两个:
复合问题的推理效果较差,而将其拆成多个子问题则可以让效果提升。
事实知识的可靠性。有时候大模型的生成结果可能是“正确的废话”,正确但对任务并不有效。
因此,有必要对实际的推荐问题进行拆解,更有针对性地利用大模型才能真正发挥大模型的作用。作者提出了一种factorization prompting的方案,将任务拆解成几个关键因素,这样既能确保生成的推理知识和事实知识的一致性,也能保证在推荐系统中真正有用。
这里,就有两个关键操作:
场景因素的规范化。借助大模型对特定场景的关键因素进行抽取和规范化,文章中给出的例子是电影推荐场景,会问大模型:“列出决定用户是否对电影感兴趣的重要的因素或特征”,用这个方式即可规范后续用户偏好的描述维度,以便大模型进行更加有效的分析。
用户偏好推理和物料事实描述。借助场景因素的规范化,可以进一步让大模型根据场景因素,利用现有信息对用户的偏好进行推理,也可以对物料进行特定的描述和评价。
这里作者给出了一些用户偏好推理和物料事实描述的prompt案例。

知识适配
大模型知识适配普遍存在如下难题:
大模型生成的内容大都是文本格式,而且是自然语言,而推荐系统的很多模型普遍没有对这种类型文本的处理能力。
即使是直接使用大模型输出的密集向量,其空间也和推荐系统的空间并不一致。
生成的知识可能包含噪音和不可靠信息。
因此,文章设计了两个模块,知识编码器和混合专家适配器,前者对文本知识进行有效编码,后者将编码映射到和推荐系统同一空间方便使用。
知识编码器说白了就是一个把自然语言转化为向量的模型,如Bert,取其CLS或平均池化等的方式进行转化即可。
混合专家适配器就是参考了常见的MoE的思路,构造了共享专家和专用专家,共享专家能捕捉用户偏好和物料事实的共同信息,专用专家则考虑了用户偏好和物料事实两者各自的信息,内部的推理基本就是全连接层的模式(就是多层感知机)。
知识利用
然后,就是把各种信息都攒一块,然后开始预测了,这个公式也非常简单:
函数内这里分别对应的是原始特征向量、用户行为向量、推理(我还是喜欢叫用户偏好)增强向量、事实增强向量、模型参数,在后续的实验中,分别有对大量的"f"进行比对实验,如DCN、DeppFM、AutoInt等,都是大家耳熟能详的推荐模型了。
加速策略
文章专门有一小章讲加速策略,不过内部基本是比较常规的加速方案了,很多方案的思想在我的这篇文章也有提及(心法利器[132] | 大模型系统性能优化trick)。文章中的操作,简单总结就是:提前计算并存储到数据库里,可以试推理增强向量、事实增强向量,也可以是经过MoE后的转化向量。另外对于用户的偏好,也可以考虑只使用长期兴趣,从而减少变更频率,进一步降低使用大模型的次数。
实验
一般情况其实我并不会讲实验和结果,论文这块多半都比较固定了,但这篇论文的实验还是值得讲一下,尤其是实验的思路,作者非常严谨,列举了实验中希望回答的问题并进行了详细验证。所以首先先看实验要回答的问题:
RQ1:KAR对不同任务(如点击率预测和重排序)的骨干模型有何改进?
RQ2:KAR与其他基于预训练语言模型(PLM)的基线方法相比如何?
RQ3:LLMs的知识是否优于其他知识(如知识图谱)?
RQ4:KAR在线上部署时是否获得性能提升?
RQ5:LLMs生成的推理知识和事实知识对性能提升的贡献如何?
RQ6:不同的知识适应方法对KAR性能的影响如何?
RQ7:加速策略(预处理和预存储)是否提高了推理速度?
仔细想,就会发现,这些问题非常严谨地考虑到本文核心的创新点和模型的初衷,甚至包括和知识图谱这一同质竞争者的对比,还有消融实验等,确实都有在做。有关实验的细节和结果我就不贴出来了,我说几个比较细小但是还挺重要的表现:
消融实验里看,用户画像的推理信息带来的收益会更大,相比之下物料的事实信息好像并不强。
大模型的选择上,BERT和ChatGLM都有做实验,虽说ChatGLM比BERT高,但收益似乎并不是很明显,性价比不高。
当然,这个结论可能并非根本结论,在那个时间点下(23年中后期),有关大模型能力、大模型信息的表征之类的研究还不算深入,后续更深入的研究可能会打破上面的这些发现。
小结
本文介绍了一种大模型应用的方案——KAR,旨在依靠大模型的世界知识和推理能力赋能推荐系统,使之效果提升,并做了大量的实验来分析对比与之类似的方案,以及消融等。在此,也给我们带来不少的启发:
KAR的这种模式应该是后续应用大模型到推荐系统中的一种基本思路,推理-适配-利用的模式也非常规范,后续的研究工作也可以分别聚焦这3部分。
文中“推理-适配-利用”这三部分各自的方案应该是一个比较容易想到的baseline了,在初步应用时是可以考虑的。
大模型功能的拆解和针对性会让整体效果的提升更为明显,文中大模型专门做用户偏好分析和物料事实总结让其最终的推荐结果更具可靠性和可解释性。
另外,我这里还有一些思考点:
在大模型对物料进行描述时,物料事实的描述和评价,大模型可能会存在信息差和主观性。信息差主要是,大模型在训练阶段,应该已经吸收了很多经典物料的特性,例如《罗马假日》这种作品,大模型了解的会比较多,因此描述的会比较好,但是新的作品类似《哪吒之魔童闹海》则只能依赖prompt中的提示,可能效果会比较差甚至会被《哪吒之魔童降世》影响。主观性则来源于“偏见”,大模型在训练过程难免会对一些内容产生偏见,此时的评价也容易出现偏差。
24-25年大模型自身能力的提升是非常明显,在23年中后期的时间点下的大模型收益应该比现在会低很多,可能有待进一步的实验,甚至现在推理型的大模型,可能可以给推荐系统带来推理思路的依据支持。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









