









soul源码解读(十二)
divide插件原理分析
1.启动 admin 和 bootstrap
2.启动两个 soul-examples-http 服务,端口号分别为8188、8189
3.用 postman 调用接口 http://localhost:9195/http/order/findById?id=3
插件调用
发现程序入口在 SoulWebHandler#handle 。
handle 会调用 execute() 去执行具体的插件逻辑(这里埋个坑,后面会写篇文章来讲下 soul 的插件调用链)。
又是下面这段熟悉的代码
// SoulWebHandler.java
public Mono<Void> execute(final ServerWebExchange exchange) {
return Mono.defer(() -> {
if (this.index < plugins.size()) {
SoulPlugin plugin = plugins.get(this.index++);
Boolean skip = plugin.skip(exchange);
if (skip) {
return this.execute(exchange);
}
return plugin.execute(exchange, this);
}
return Mono.empty();
});
}
然后soul的插件是按顺序来执行的,具体如下
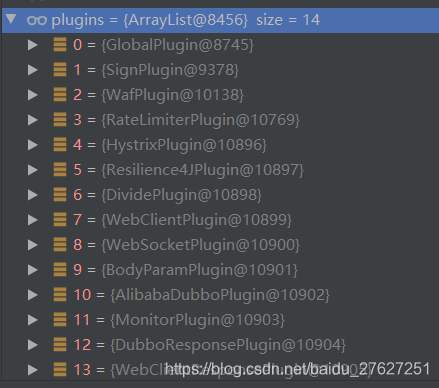
soul 会按顺序执行每个插件的逻辑,我们今天重点看 divide 插件的逻辑。
plugin.skip(exchange) 会去判断这次请求的 rpcType 是不是等于 http ,
// DividePlugin#skip
return !Objects.equals(Objects.requireNonNull(soulContext).getRpcType(), RpcTypeEnum.HTTP.getName());
等于就不跳过
然后会执行下面这行代码
// SoulWebHandler.java
return plugin.execute(exchange, this);
这里面会调用到 AbstractSoulPlugin#execute ,它会判断插件是否为空,有没有开启。
// AbstractSoulPlugin#execute
if (pluginData != null && pluginData.getEnabled())
不为空的话,会继续判断里面的选择器(selector)是否为空,然后去匹配选择器
// AbstractSoulPlugin#execute
final Collection<SelectorData> selectors = BaseDataCache.getInstance().obtainSelectorData(pluginName);
if (CollectionUtils.isEmpty(selectors)) {
return handleSelectorIsNull(pluginName, exchange, chain);
}
final SelectorData selectorData = matchSelector(exchange, selectors);
if (Objects.isNull(selectorData)) {
return handleSelectorIsNull(pluginName, exchange, chain);
}
// AbstractSoulPlugin#matchSelector
private SelectorData matchSelector(final ServerWebExchange exchange, final Collection<SelectorData> selectors) {
return selectors.stream()
.filter(selector -> selector.getEnabled() && filterSelector(selector, exchange))
.findFirst().orElse(null);
}
接着往下走,会调用 filterSelector() -> MatchStrategyUtils.match()
// MatchStrategyUtils.java
// 这里是通过扩展点加载机制,获取SPI定义的不同匹配策略
MatchStrategy matchStrategy = ExtensionLoader.getExtensionLoader(MatchStrategy.class).getJoin(matchMode);
return matchStrategy.match(conditionDataList, exchange);
我们后台配的是 and
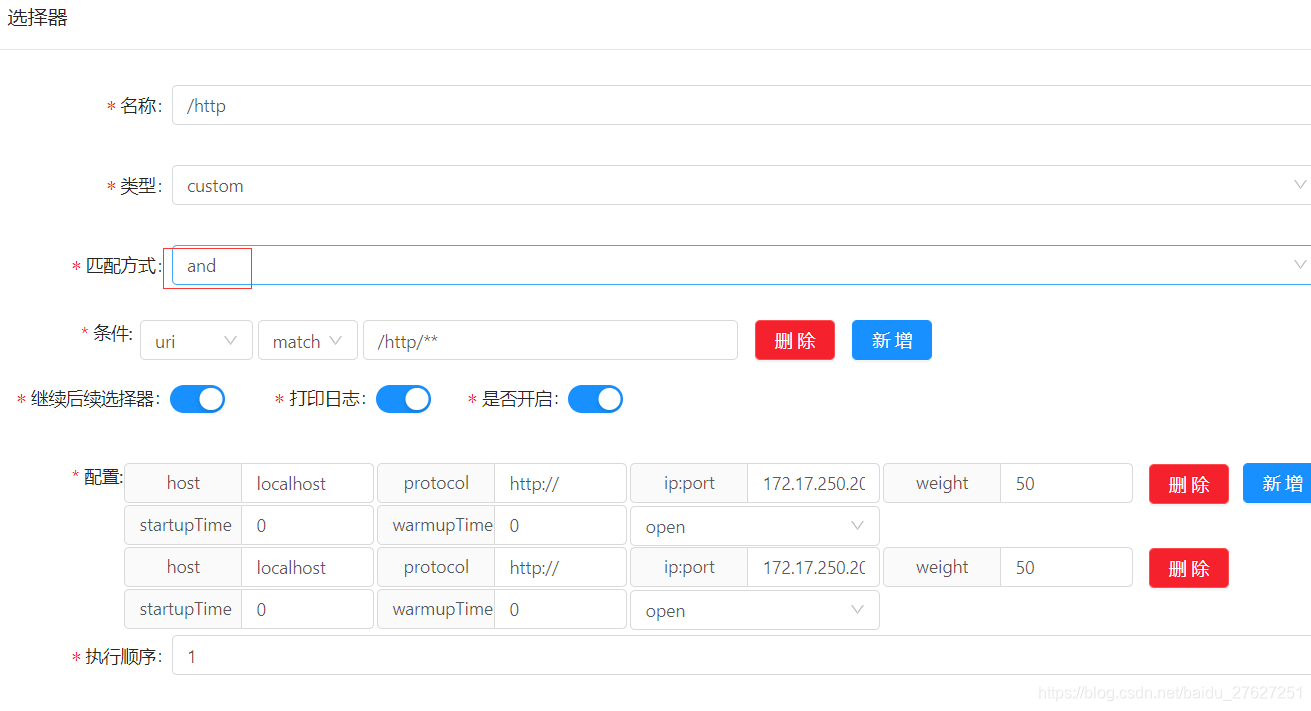
所以最后会走到 AndMatchStrategy 里来
// AndMatchStrategy.java
public Boolean match(final List<ConditionData> conditionDataList, final ServerWebExchange exchange) {
return conditionDataList
.stream()
.allMatch(condition -> OperatorJudgeFactory.judge(condition, buildRealData(condition, exchange)));
}
接着往下看 buildRealData 会去判断选择器里配置的到底是哪种 ParamTypeEnum ,然后看有没有匹配上。
String buildRealData(final ConditionData condition, final ServerWebExchange exchange) {
String realData = "";
ParamTypeEnum paramTypeEnum = ParamTypeEnum.getParamTypeEnumByName(condition.getParamType());
switch (paramTypeEnum) {
case URI:
realData = exchange.getRequest().getURI().getPath();
break;
...
default:
break;
}
return realData;
}
匹配上就返回有匹配,然后接着判断有没有匹配到规则 (Rule)
// AbstractSoulPlugin#execute
rule = matchRule(exchange, rules);
里面也会调用到 MatchStrategyUtils.match()
最后如果匹配到规则就执行下面的代码,没匹配到就执行下一个插件逻辑。
return doExecute(exchange, chain, selectorData, rule);
下面就走到了 DividePlugin 里面。
// DividePlugin.java
protected Mono<Void> doExecute(final ServerWebExchange exchange, final SoulPluginChain chain, final SelectorData selector, final RuleData rule) {
...
// 获取服务节点,这里我们启动了两个服务,所以upstreamList 里有8188和8189两个节点
final List<DivideUpstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());
...
// 通过负责均衡策略获取最终调用的节点
DivideUpstream divideUpstream = LoadBalanceUtils.selector(upstreamList, ruleHandle.getLoadBalance(), ip);
...
return chain.execute(exchange);
}
默认的负载均衡策略是 random
负载均衡(以随机算法为例)的代码如下:
// AbstractLoadBalance.java
public DivideUpstream select(final List<DivideUpstream> upstreamList, final String ip) {
if (CollectionUtils.isEmpty(upstreamList)) {
return null;
}
if (upstreamList.size() == 1) {
return upstreamList.get(0);
}
return doSelect(upstreamList, ip);
}
// RandomLoadBalance.java
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
int totalWeight = calculateTotalWeight(upstreamList);
boolean sameWeight = isAllUpStreamSameWeight(upstreamList);
if (totalWeight > 0 && !sameWeight) {
return random(totalWeight, upstreamList);
}
return random(upstreamList);
}
// 如果权重一样就随机取一个节点
return upstreamList.get(RANDOM.nextInt(upstreamList.size()));
// 权重不一样,就根据总权重来随机命中节点
int offset = RANDOM.nextInt(totalWeight);
// Determine which segment the random value falls on
for (DivideUpstream divideUpstream : upstreamList) {
offset -= getWeight(divideUpstream);
if (offset < 0) {
return divideUpstream;
}
}
return upstreamList.get(0);
确定了最终访问的节点之后,divide 插件会修改 ServerWebExchange 里的请求 url。
然后执行后面的插件,divide 插件后面跟着是 WebClientPlugin。
它会打印网关最终请求的真实地址
// WebClientPlugin.java
log.info("The request urlPath is {}, retryTimes is {}", urlPath, retryTimes);
然后 webClient 插件会通过 netty 执行请求
最后通过 WebClientResponsePlugin 把响应返回。
总结
soul 网关启动的时候,会从加载所有插件到内存里,当一个 http 请求过来,会一个插件一个插件的遍历,命中到divide 插件之后,会去匹配选择器和规则,然后根据负载均衡算法拿到最终要调用的节点信息,然后通过 webClient 插件执行请求,最后通过 webClientResponse 插件返回数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









