







环境
- Google浏览器
- selenium
selenium可以模仿操作浏览器的过程。这里使用selenium的原因主要是因为使用JSoup暂时没有找到百度图片原图链接。查看页面源码,可以发现图片是动态加载出来的。

需要注意的是: selenium的版本要和chrome浏览器的版本匹配。下面的这条链接可以参考一下。
selenium之 chromedriver与chrome版本映射表(更新至v2.43)
【https://blog.csdn.net/qq_40374604/article/details/84430963】
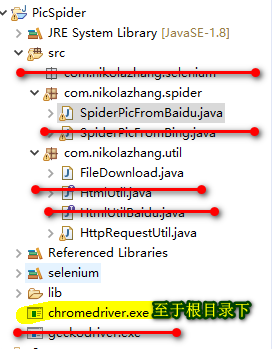
下图为项目的结构。需要引入selenium jar包, 以及Chromedriver.exe
F12观察页面元素
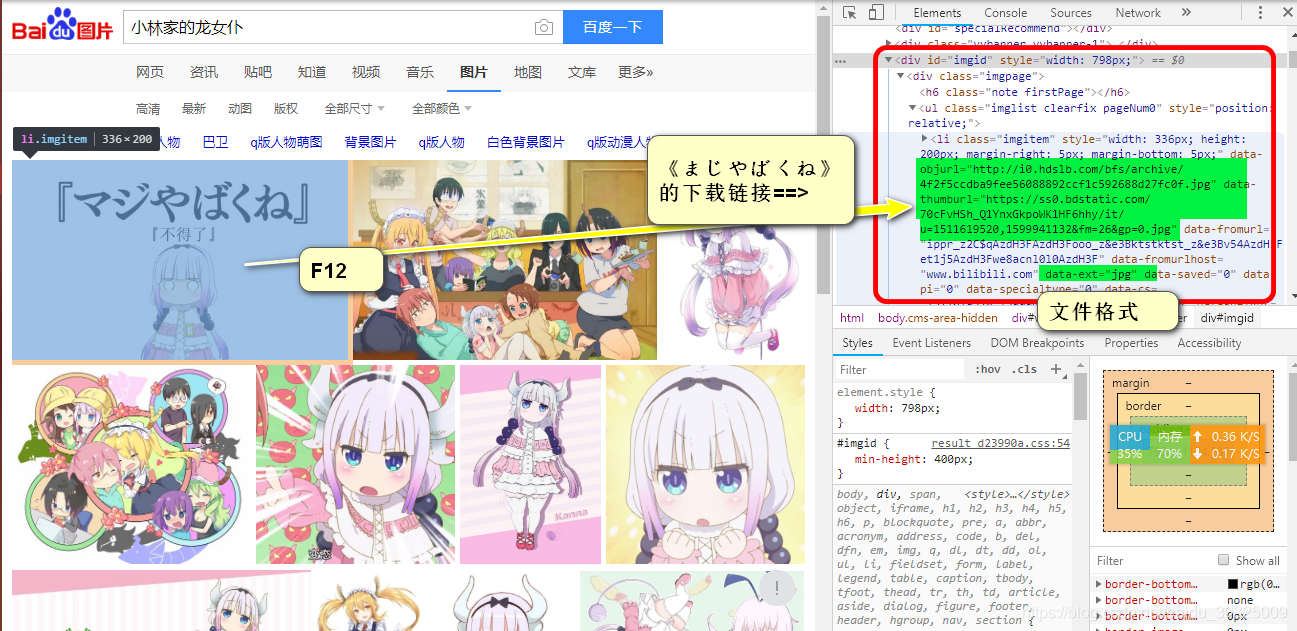
这个过程就不多说了,选定一个元素从上到下所有的url全部试一遍。
编写程序
这个没什么好说的,只要找对了页面元素并获取,都没什么问题。
这里用到了一个页面滚动的操作。
((JavascriptExecutor) connWeb).executeScript("window.scrollBy(0, document.body.scrollHeight)");
可以参考下面的链接:
Selenium之Web页面滚动条滚操作
【https://blog.csdn.net/jlminghui/article/details/50477283】
package com.nikolazhang.spider;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.List;
import java.util.Scanner;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.interactions.Actions;
import com.nikolazhang.util.FileDownload;
import com.nikolazhang.util.HttpRequestUtil;
public class SpiderPicFromBaidu {
private static int cnt = 0;
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入参数[参数之间使用一个空格分割] , 回车执行!");
String[] params = scanner.nextLine().split(" ");
String filepath = params[0];
String keywords = params[1];
int count = Integer.valueOf(params[2]);
if(count<=0) {
System.out.println("下载数量必须大于零!!!程序退出");
return;
}
String url = inputBaiduImageUrl(keywords);
WebDriver connWeb = connWeb(url);
Iterator<WebElement> imageUrl = null;
for(int i = 1; i<=count/5; i++) {
((JavascriptExecutor) connWeb).executeScript("window.scrollBy(0, document.body.scrollHeight)");
}
System.out.println("页面元素加载中...请等待...!");
try {
Thread.sleep(count*10);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
try {
imageUrl = getImageUrl(connWeb);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(imageUrl != null) {
downloadImage(imageUrl, filepath);
} else {
System.out.println("图片下载失败!!!");
}
System.out.println("下载结束----退出浏览器!!!");
connWeb.close();
}
/**
* 链接目标网站
* @param url
* @return
*/
public static WebDriver connWeb(String url) {
System.setProperty("webdriver.chrome.driver",
"chromedriver.exe");
WebDriver webDriver = new ChromeDriver();
webDriver.get(url);
System.out.println("*+*+*+*+* 已连接网站: 【"+webDriver.getTitle()+"】");
return webDriver;
}
/**
* 输入关键词
*/
public static String inputBaiduImageUrl(String text) {
String url = "https://image.baidu.com"
+ "/search/index"
+ "?tn=baiduimage"
+ "&word="+text;
return url;
}
public static Iterator<WebElement> getImageUrl(WebDriver webDriver) throws InterruptedException {
Actions actions = new Actions(webDriver);
List<WebElement> imgitem = webDriver.findElements(By.className("imgitem"));
System.out.println("获取到的相关的图片数量: "+imgitem.size());
Iterator<WebElement> imgItor = imgitem.iterator();
return imgItor;
}
public static void downloadImage(Iterator<WebElement> imgItor, String filepath) {
File file = new File(filepath);
if(!file.exists()) {
file.mkdirs();
}
while(imgItor.hasNext()) {
WebElement nextImg = imgItor.next();
String addrImg = nextImg.getAttribute("data-objurl");
String filename = ++cnt + "." + nextImg.getAttribute("data-ext");
FileDownload.saveImageToDisk(addrImg, filepath+filename);
System.out.println("下载第"+ cnt +"张图片地址为: "+addrImg);
}
}
}
- 文件下载公共类
package com.nikolazhang.util;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class FileDownload {
public static void saveImageToDisk(InputStream inputStream, String filepath) {
byte[] data = new byte[1024];
int len = 0;
FileOutputStream fileOutputStream = null;
try {
fileOutputStream = new FileOutputStream(filepath);
while ((len = inputStream.read(data)) != -1) {
fileOutputStream.write(data, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fileOutputStream != null) {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
Http请求公共类:
package com.nikolazhang.util;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.HttpURLConnection;
import java.net.InetSocketAddress;
import java.net.Proxy;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
/**
* Http请求工具类
*/
public class HttpRequestUtil {
static boolean proxySet = false;
static String proxyHost = "127.0.0.1";
static int proxyPort = 8087;
/**
* 编码
* @param source
* @return
*/
public static String urlEncode(String source,String encode) {
String result = source;
try {
result = java.net.URLEncoder.encode(source,encode);
} catch (UnsupportedEncodingException e) {
return "0";
}
return result;
}
public static String urlEncodeGBK(String source) {
String result = source;
try {
result = java.net.URLEncoder.encode(source,"GBK");
} catch (UnsupportedEncodingException e) {
return "0";
}
return result;
}
/**
* 发起http请求获取返回结果
* @param req_url 请求地址
* @return
*/
public static String httpRequest(String req_url, String fmt) {
StringBuffer buffer = new StringBuffer();
try {
URL url = new URL(req_url);
HttpURLConnection httpUrlConn = (HttpURLConnection) url.openConnection();
httpUrlConn.setDoOutput(false);
httpUrlConn.setDoInput(true);
httpUrlConn.setUseCaches(false);
httpUrlConn.setRequestMethod("GET");
httpUrlConn.connect();
// 将返回的输入流转换成字符串
InputStream inputStream = httpUrlConn.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream, fmt);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
bufferedReader.close();
inputStreamReader.close();
// 释放资源
inputStream.close();
inputStream = null;
httpUrlConn.disconnect();
} catch (Exception e) {
}
return buffer.toString();
}
/**
* 发送http请求取得返回的输入流
* @param requestUrl 请求地址
* @return InputStream
*/
public static InputStream httpRequestIO(String requestUrl) {
InputStream inputStream = null;
try {
URL url = new URL(requestUrl);
HttpURLConnection httpUrlConn = (HttpURLConnection) url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
httpUrlConn.connect();
// 获得返回的输入流
inputStream = httpUrlConn.getInputStream();
} catch (Exception e) {
}
return inputStream;
}
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map<String, List<String>> map = connection.getHeaderFields();
// 遍历所有的响应头字段
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
/**
* 向指定 URL 发送POST方法的请求
*
* @param url
* 发送请求的 URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @param isproxy
* 是否使用代理模式
* @return 所代表远程资源的响应结果
*/
public static String sendPost(String url, String param, String fmt,boolean isproxy) {
OutputStreamWriter out = null;
BufferedReader in = null;
String result = "";
try {
URL realUrl = new URL(url);
HttpURLConnection conn = null;
if(isproxy){//使用代理模式
@SuppressWarnings("static-access")
Proxy proxy = new Proxy(Proxy.Type.DIRECT.HTTP, new InetSocketAddress(proxyHost, proxyPort));
conn = (HttpURLConnection) realUrl.openConnection(proxy);
}else{
conn = (HttpURLConnection) realUrl.openConnection();
}
// 打开和URL之间的连接
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestMethod("POST"); // POST方法
// 设置通用的请求属性
// conn.setRequestProperty("accept", "*/*");
// conn.setRequestProperty("connection", "Keep-Alive");
// conn.setRequestProperty("user-agent",
// "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
conn.connect();
// 获取URLConnection对象对应的输出流
out = new OutputStreamWriter(conn.getOutputStream(), fmt);
// 发送请求参数
out.write(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
}
//使用finally块来关闭输出流、输入流
finally{
try{
if(out!=null){
out.close();
}
if(in!=null){
in.close();
}
}
catch(IOException ex){
ex.printStackTrace();
}
}
return result;
}
public static void main(String[] args) {
//demo:代理访问
String url = "http://api.adf.ly/api.php";
String para = "key=youkeyid&youuid=uid&advert_type=int&domain=adf.ly&url=http://somewebsite.com";
}
}
以上程序可以在GitHub上获取,CSDN上的代码一般不会更新:
【https://github.com/NikolaZhang/PickPic】
运行
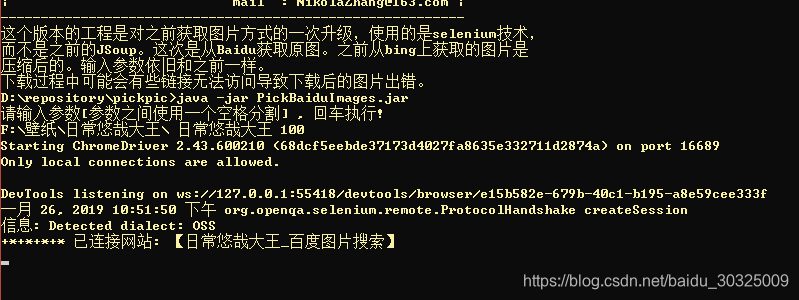
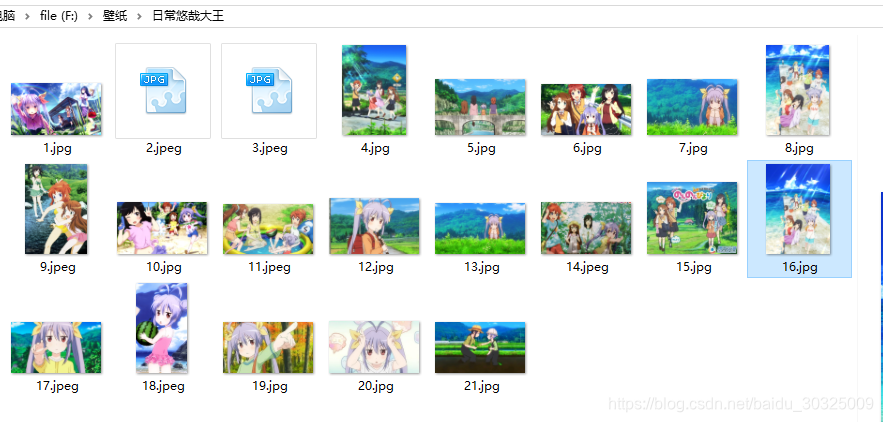
完美~~















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









