







Go Slice实现原理分析
认识 Slice
一种可变长度的数
操作
- make :创建Slice,可以提前分配内存,
- append:往Slice添加元素
package main
import (
"fmt"
)
func main() {
slice := make([]int, 0, 1) // 7 runtime.makeslice
slice = append(slice, 1)
slice = append(slice, 2) // 9 runtime.growslice
fmt.Println(slice, len(slice), cap(slice))
}
- 汇编代码:go tool compile -S main.go
0x004c 00076 (main.go:7) CALL runtime.makeslice(SB) // 创建
0x0051 00081 (main.go:7) MOVQ 24(SP), AX
0x0056 00086 (main.go:8) MOVQ $1, (AX)
0x005d 00093 (main.go:9) LEAQ type.int(SB), CX
0x0064 00100 (main.go:9) MOVQ CX, (SP)
0x0068 00104 (main.go:9) MOVQ AX, 8(SP)
0x006d 00109 (main.go:9) MOVQ $1, 16(SP)
0x0076 00118 (main.go:9) MOVQ $1, 24(SP)
0x007f 00127 (main.go:9) MOVQ $2, 32(SP)
0x0088 00136 (main.go:9) CALL runtime.growslice(SB) // 扩容
- Slice 实现源码路径:runtime/slice.go,关注:runtime.makeslice, runtime.growslice。
源码实现 runtime/slice.go
Slice 结构
type slice struct {
array unsafe.Pointer //数组首地址指针
len int //长度
cap int //容量
}
Slice 创建
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap)) // 判断申请大小是否超过限制, MulUintptr:主要就是用切片中元素大小和切片的容量相乘计算出所需占用的内存空间
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true) // 内存申请
// *_type 是 Go 中类型的实现
type _type struct {
size uintptr // 大小
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
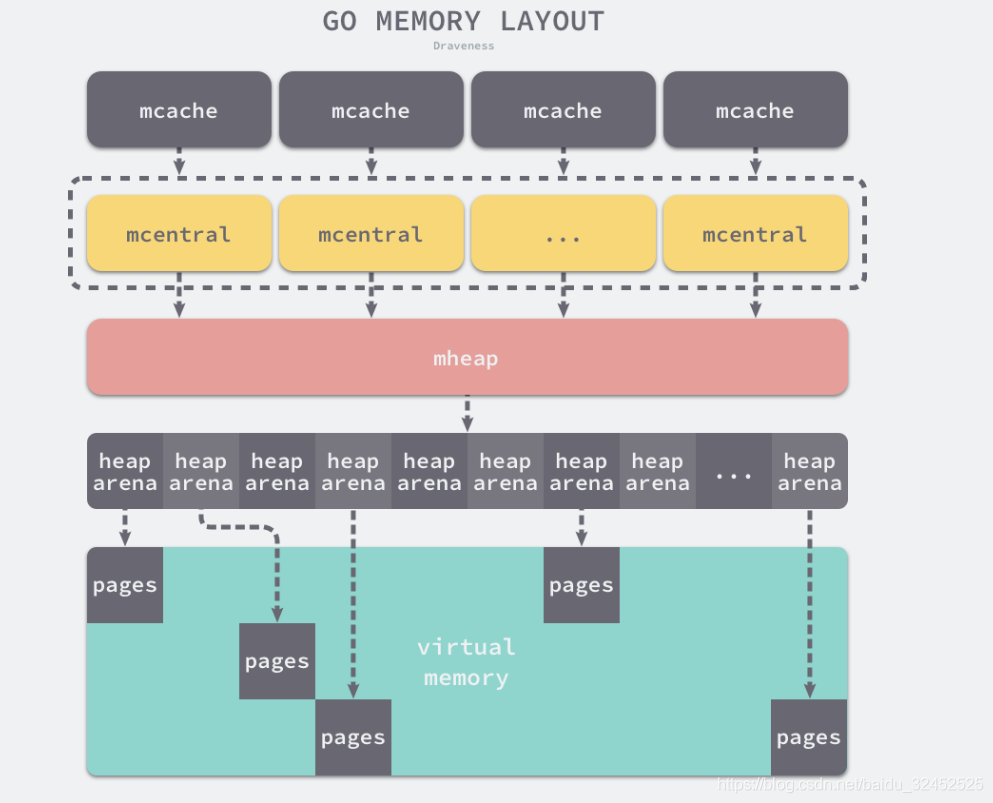
内存分配
- runtime.mspan:内存管理单元
- runtime.mcache:线程缓存
- runtime.mcentral :中心缓存
- runtime.mheap:页堆
// mallocgc 内存申请
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
mp := acquirem()
mp.mallocing = 1
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
if size <= maxSmallSize {
if noscan && size < maxTinySize {
// 微对象分配
} else {
// 小对象分配
}
} else {
// 大对象分配
}
publicationBarrier()
mp.mallocing = 0
releasem(mp)
return x
}
- 微对象 (0, 16B) — 先使用微型分配器,再依次尝试线程缓存、中心缓存和堆分配内存;
- 小对象 [16B, 32KB] — 依次尝试使用线程缓存、中心缓存和堆分配内存;
- 大对象 (32KB, +∞) — 直接在堆上分配内存;
内存结构图
出自:Go 语言切片的实现原理| Go 语言设计与实现 - 面向信仰编程
Slice 扩容
package main
import (
"fmt"
)
func main() {
slice := make([]int, 0, 2)
slice = append(slice, 1)
fmt.Printf("%p %d %d\n", unsafe.Pointer(&slice[0]), len(slice), cap(slice))
slice = append(slice, 2)
fmt.Printf("%p %d %d\n", unsafe.Pointer(&slice[0]), len(slice), cap(slice))
slice = append(slice, 3)
fmt.Printf("%p %d %d\n", unsafe.Pointer(&slice[0]), len(slice), cap(slice))
}
// 结果
0xc0000b4010 1 2 // 地址没变,长度:1,容量:2
0xc0000b4010 2 2 // 地址没变,长度:2,容量:2
0xc0000ba020 3 4 // 地址改变,长度:3,容量:4
- 为什么结果会这样?
- runtime.growslice 做了什么?为什么地址变了,容量也自动扩大了2倍?
0x025e 00606 (main.go:13) PCDATA $1, $0
0x025e 00606 (main.go:13) NOP
0x0260 00608 (main.go:13) CALL runtime.growslice(SB) // slice = append(slice, 3)
0x0265 00613 (main.go:13) MOVQ 40(SP), AX
0x026a 00618 (main.go:13) MOVQ 48(SP), CX
0x026f 00623 (main.go:13) MOVQ 56(SP), DX
0x0274 00628 (main.go:13) MOVQ $3, 16(AX)
func growslice(et *_type, old slice, cap int) slice {
...
...
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
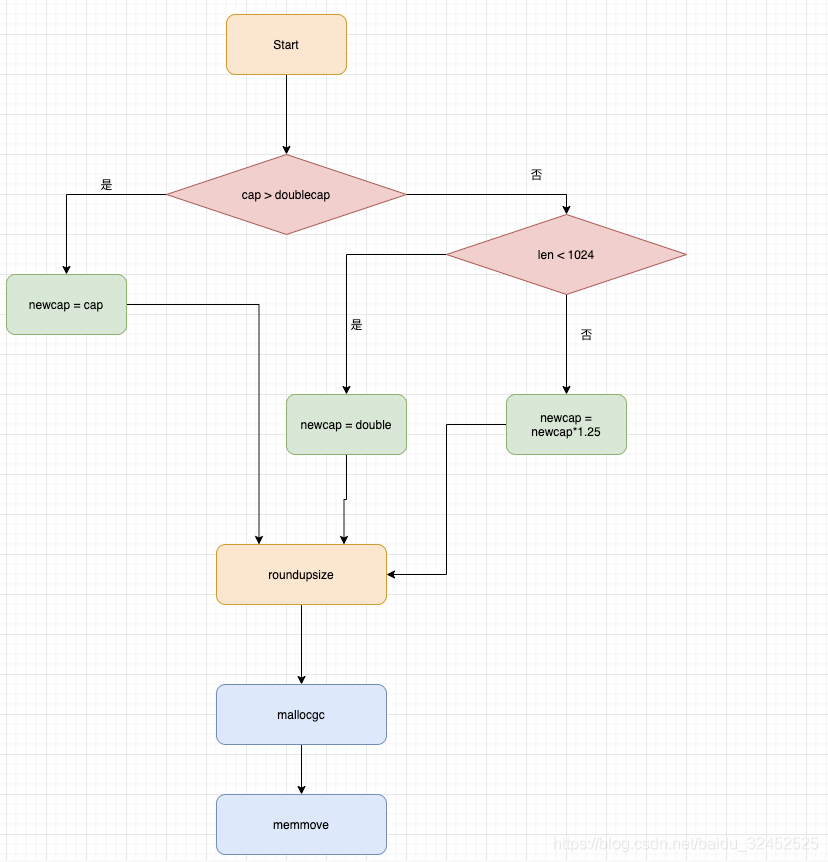
newcap := old.cap// 1
doublecap := newcap + newcap// 1+1 = 2 为什么不直接*2, 而是使用加法?
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4 // 1.25倍
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
...
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
...
memmove(p, old.array, lenmem)
}
//
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize { // 32768
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]]) // 申请的内存块个数
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]]) 申请的内存块个数
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
// alignUp rounds n up to a multiple of a. a must be a power of 2.
func alignUp(n, a uintptr) uintptr {
return (n + a - 1) &^ (a - 1)
}
const _MaxSmallSize = 32768
const smallSizeDiv = 8
const smallSizeMax = 1024
const largeSizeDiv = 128
- 当原slice的cap小于1024时,新slice的cap变为原来的2倍;原slice的cap大于1024时,新slice变为原来的1.25倍
- roundupsize是内存对齐的过程,我们知道golang中内存分配是根据对象大小来配不同的mspan,为了避免造成过多的内存碎片,slice在扩容中需要对扩容后的cap容量进行内存对齐的操作‘
下面是一个Slice 扩容简单流程
// Implementations are in memmove_*.s.
//
//go:noescape
func memmove(to, from unsafe.Pointer, n uintptr)
// memmove_amd64.s // 汇编实现的 memmove
常见操作以及带来的问题
Slice创建
make 到底带不带 cap?,怎么设置?
package main
import "fmt"
func MakeCap(){
s := make([]int, 0, 100000)
for i:=0;i<100000;i++{
s = append(s ,i)
}
}
func MakNoCap(){
s := make([]int, 0)
for i:=0;i<100000;i++{
s = append(s ,i)
}
}
压力测试代码
// Bench
package main
import (
"testing"
)
func BenchmarkMakeCap(b *testing.B) {
for i := 0; i < b.N; i++ {
MakeCap()
}
}
func BenchmarkMakNoCap(b *testing.B) {
for i := 0; i < b.N; i++ {
MakNoCap()
}
}
// 结果
goos: darwin
goarch: amd64
pkg: test
BenchmarkMakeCap-16 10668 115607 ns/op
BenchmarkMakNoCap-16 2476 485026 ns/op
PASS
ok test 4.166s
结论
- 可以看到,指定容量和未指定容量效率相差近4倍,所以在Slice 初始化的时候,我们应该指定容量大小以提高效率
思考:newSlice := slice[0:1:1],这是什么操作?
Slice截取
package main
import (
"fmt"
"reflect"
"unsafe"
)
func Slice(s []int) *reflect.SliceHeader {
sh := (*reflect.SliceHeader)(unsafe.Pointer(&s))
return sh
}
func main() {
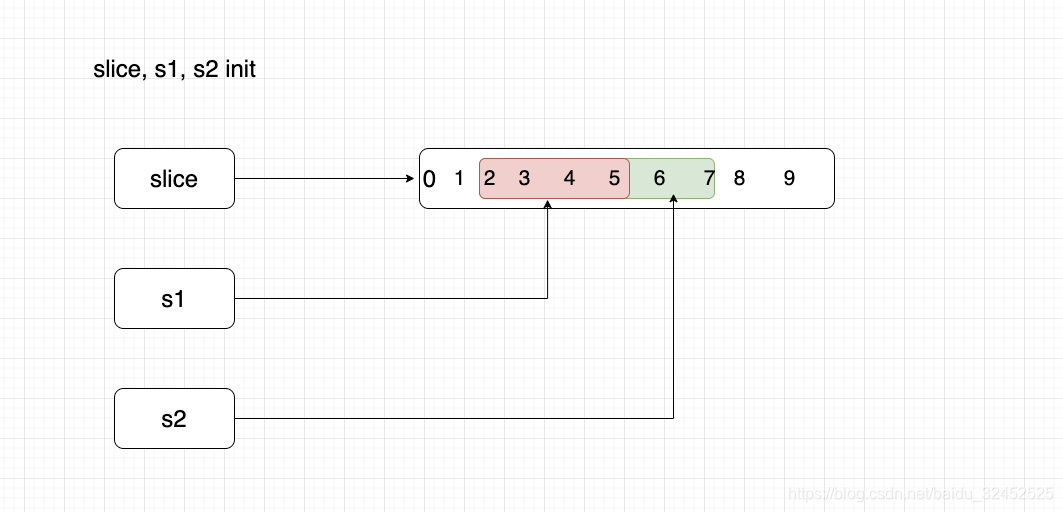
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:7]
fmt.Println("--------slice, s1, s2 init----------------")
fmt.Printf("slice data addr=%d s1 data addr=%d s2 data addr=%d \n", Slice(slice).Data, Slice(s1).Data, Slice(s2).Data)
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \n", len(s2), cap(s2), s2)
fmt.Println("--------s2 append 100----------------")
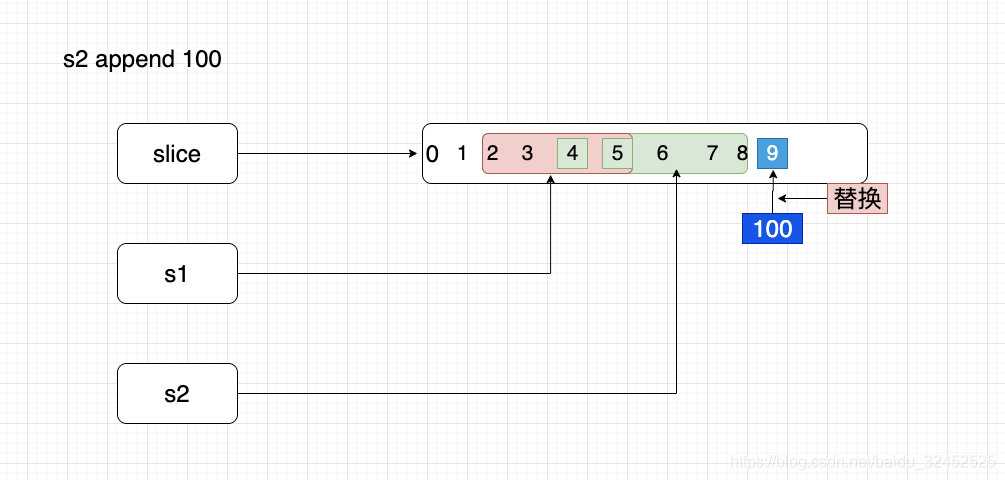
s2 = append(s2, 100)
fmt.Printf("slice data addr=%d s1 data addr=%d s2 data addr=%d \n", Slice(slice).Data, Slice(s1).Data, Slice(s2).Data)
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \n", len(s2), cap(s2), s2)
fmt.Println("--------s2 append 200----------------")
s2 = append(s2, 200)
fmt.Printf("slice data addr=%d s1 data addr=%d s2 data addr=%d \n", Slice(slice).Data, Slice(s1).Data, Slice(s2).Data)
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \n", len(s2), cap(s2), s2)
fmt.Println("--------s1 modify [2]----------------")
s1[2] = 20
fmt.Printf("slice data addr=%d s1 data addr=%d s2 data addr=%d \n", Slice(slice).Data, Slice(s1).Data, Slice(s2).Data)
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \n", len(s2), cap(s2), s2)
}
结果
//
--------slice, s1, s2 init----------------
slice data addr=824633819296 s1 data addr=824633819312 s2 data addr=824633819328
len=10 cap=10 slice=[0 1 2 3 4 5 6 7 8 9]
len=3 cap=8 s1=[2 3 4]
len=5 cap=6 s2=[4 5 6 7 8]
--------s2 append 100----------------
slice data addr=824633819296 s1 data addr=824633819312 s2 data addr=824633819328
len=10 cap=10 slice=[0 1 2 3 4 5 6 7 8 100]
len=3 cap=8 s1=[2 3 4]
len=6 cap=6 s2=[4 5 6 7 8 100]
--------s2 append 200----------------
slice data addr=824633819296 s1 data addr=824633819312 s2 data addr=824634196160 // 因为扩容,s1 底层数据地址变化,
len=10 cap=10 slice=[0 1 2 3 4 5 6 7 8 100]
len=3 cap=8 s1=[2 3 4]
len=7 cap=12 s2=[4 5 6 7 8 100 200]
--------s1 modify [2]----------------
slice data addr=824633819296 s1 data addr=824633819312 s2 data addr=824634196160
len=10 cap=10 slice=[0 1 2 3 20 5 6 7 8 100]
len=3 cap=8 s1=[2 3 20]
len=7 cap=12 s2=[4 5 6 7 8 100 200]
- --------slice, s1, s2 init----------------
slice, s1, s2, 这三个Slice 都共用一个底层的数据
- --------s2 append 100----------------
s2 往后面append 100,此时slice 中的 9 被替换为 100。
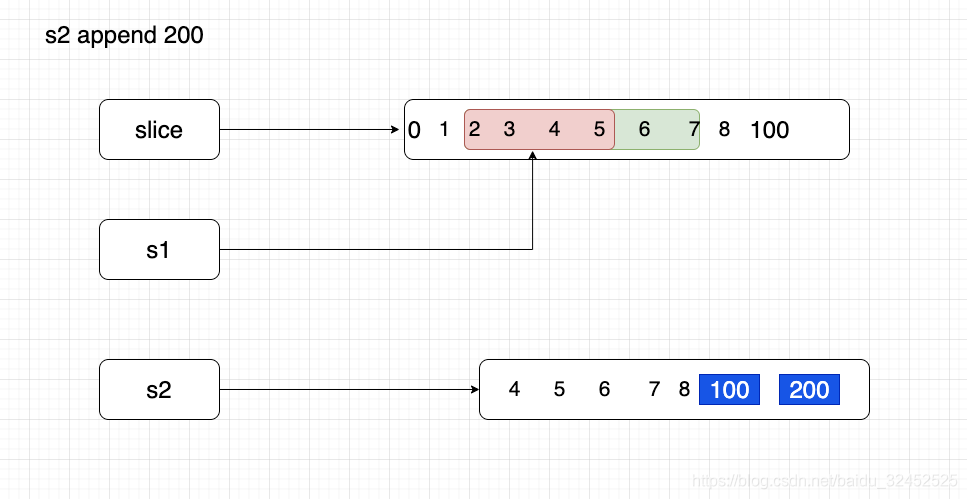
- --------s2 append 200----------------
s2 继续添加 200,发生扩容,此时生成了新的底层数组,s2 不再与 slice, s1, 共用一个底层数据
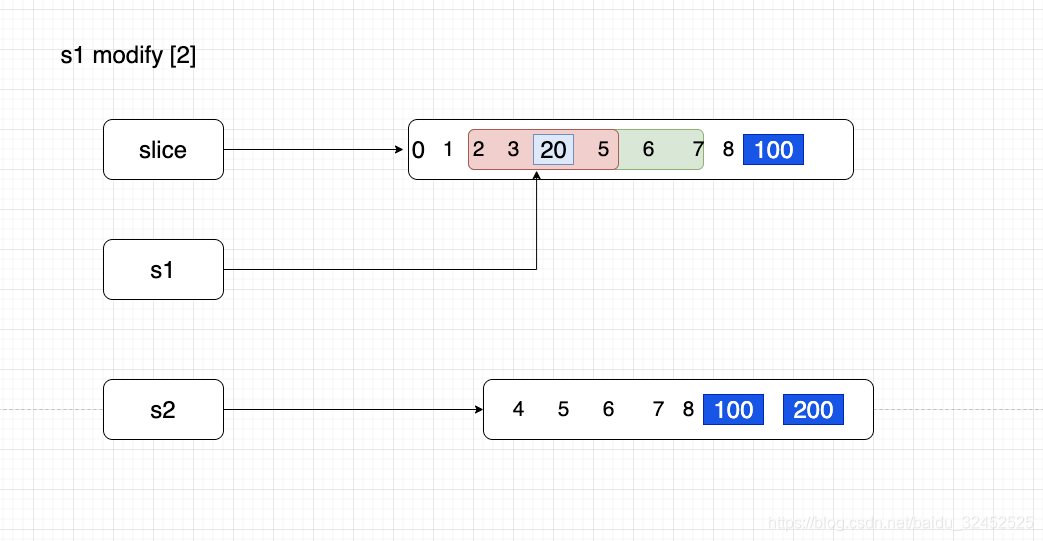
- --------s1 modify 2----------------
s1 修改2, slice 2 也会跟着变化,因为 slice, s1, 还是共用一个底层数据
如何避免这个问题?使用 Slice深拷贝
package main
import "fmt"
func main() {
// Creating slices
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice2 []int
slice3 := make([]int, 5)
// Before copying
fmt.Println("------------before copy-------------")
fmt.Printf("len=%-4d cap=%-4d slice1=%v\n", len(slice1), cap(slice1), slice1)
fmt.Printf("len=%-4d cap=%-4d slice2=%v\n", len(slice2), cap(slice2), slice2)
fmt.Printf("len=%-4d cap=%-4d slice3=%v\n", len(slice3), cap(slice3), slice3)
// Copying the slices
copy1 := copy(slice3, slice1)
copy2 := copy(slice2, slice1)
fmt.Println("------------after copy-------------")
fmt.Printf("len=%-4d cap=%-4d slice1=%v\n", len(slice1), cap(slice1), slice1)
fmt.Printf("len=%-4d cap=%-4d slice2=%v\n", len(slice2), cap(slice2), slice2)
fmt.Printf("len=%-4d cap=%-4d slice3=%v\n", len(slice3), cap(slice3), slice3)
fmt.Println("slice1 --> slice3 total number of elements copied:", copy1)
fmt.Println("slice1 --> slice2 total number of elements copied:", copy2)
slice3 = append(slice3, 200)
fmt.Println("------------slice3 append 200-------------")
fmt.Printf("len=%-4d cap=%-4d slice1=%v\n", len(slice1), cap(slice1), slice1)
fmt.Printf("len=%-4d cap=%-4d slice2=%v\n", len(slice2), cap(slice2), slice2)
fmt.Printf("len=%-4d cap=%-4d slice3=%v\n", len(slice3), cap(slice3), slice3)
}
结果
//
------------before copy-------------
len=10 cap=10 slice1=[0 1 2 3 4 5 6 7 8 9]
len=0 cap=0 slice2=[]
len=5 cap=5 slice3=[0 0 0 0 0]
------------after copy-------------
len=10 cap=10 slice1=[0 1 2 3 4 5 6 7 8 9]
len=0 cap=0 slice2=[]
len=5 cap=5 slice3=[0 1 2 3 4]
slice1 --> slice3 total number of elements copied: 5
slice1 --> slice2 total number of elements copied: 0
------------slice3 append 200-------------
len=10 cap=10 slice1=[0 1 2 3 4 5 6 7 8 9]
len=0 cap=0 slice2=[]
len=6 cap=10 slice3=[0 1 2 3 4 200]
- 思考:为什么 copy2 := copy(slice2, slice1) 没有被slice1 copy到 slice2?
值传递还是引用传递
package main
import "fmt"
func main() {
fmt.Println("slice init")
slice := make([]int, 0, 10)
fmt.Println(slice, len(slice), cap(slice))
fmt.Println("slice append 1")
slice = append(slice, 1)
fmt.Println(slice, len(slice), cap(slice))
fmt.Println("fn modify [0]")
fn(slice)
fmt.Println(slice, len(slice), cap(slice))
fmt.Println("fn2 append 100 ele")
fn2(slice)
fmt.Println(slice, len(slice), cap(slice))
}
func fn(in []int) {
in[0] = 100
}
func fn2(in []int) {
for i:=0;i<11;i++{
in = append(in, i)
}
fmt.Println("fn2")
fmt.Println(in, len(in), cap(in))
fmt.Println("fn2")
}
结果
slice init
[] 0 10
slice append 1
[1] 1 10
fn modify [0]
[100] 1 10
fn2 append 100 ele
fn2
[100 0 1 2 3 4 5 6 7 8 9 10] 12 20 // fn2 里面的值改变了
fn2
[100] 1 10
- fn 直接修改了 底层数组的值,所以会影响原先的slice
- fn2 也修改了 底层数组的值,但是因为发生的扩容,这个时候已经是一个新的底层数组了,所以,原先的slice并没有受到影响 // 小心这里会产生bug
- 结论:值传递,Go当中只有值传递















 4165
4165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











