









Hash 存储引擎
在现代软件系统中,存储和检索数据是一个非常重要的任务。随着数据量的不断增长,如何高效地存储和检索数据变得越来越重要。Hash 存储引擎是一种常见的存储引擎,它可以快速地存储和检索数据。
在本文中,我们将介绍 Hash 存储引擎的工作原理,并分析一个 Go 语言实现一个简单的 Hash 存储引擎:tiny-bitcask。tiny-bitcask 是参考论文:https://riak.com/assets/bitcask-intro.pdf 开发出的一个 简单版本的demo。
通过分析 tiny-bitcask,有助于我们理解一个存储一系统是如何构造的,包括内存结构,磁盘文件结构,如何从内存结构找到对应的磁盘文件内容。
Bitcask 介绍
Bitcask 是一种底层格式为日志模样的 kv 存储,就是只追加,保证文件是一直顺序写入的,写入性能非常好
Bitcask模型的整体结构
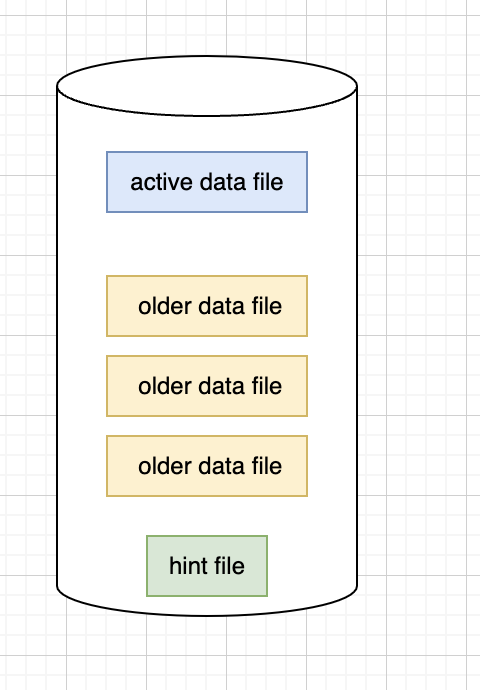
- Bitcask 只有一个可写的文件。 可写的文件叫做 active data file,只读的叫做 older data file。
- 写数据只写 active data file,而且是顺序写入,读数据从 active data file 和 older data
file 中读 hint file: - 在合并 data file 产生的文件,用于快速重新建立内存索引,可以理解成是在磁盘中的索引文件
Bitcask 它的文件格式

crc:校验码,tstamp:时间戳,ksz:key 大小,value_sz 值大小
Bitcask 它内存的索引结构
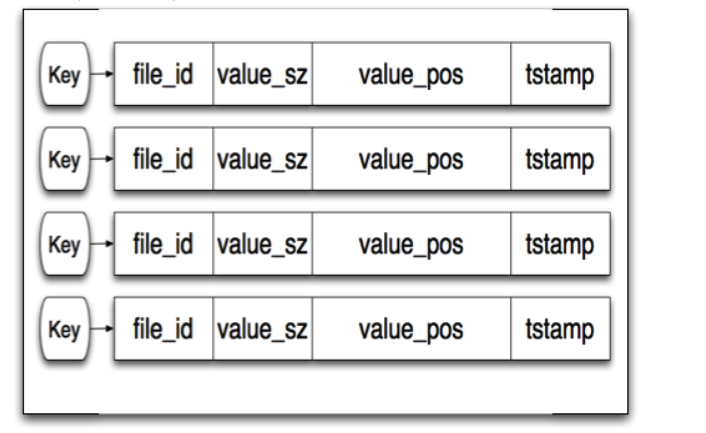
file_id: 所在的物理文件,value_sz: 值大小,value_pos: value 在文件中的位置,tstamp:时间戳
数据操作
- 写入数据:Bitcask 先写文件,持久化落盘之后更新内存 hash 表。
- 读取数据:从内存索引查询key,从这里知道了value所在的file_id,位置,大小,然后只要调用系统的读取接口就行了
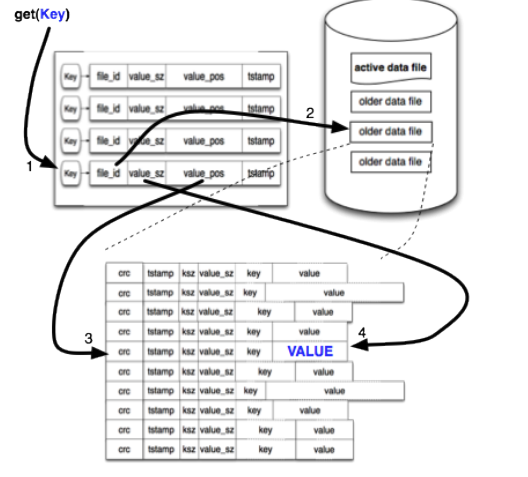
- 删除数据 :不直接删除记录,而是新增一条相同key的记录,把value设置一个删除的标记 原有记录依然存在于数据文件中,只是更新索引哈希表
- 修改数据 :Bitcask不支持随机写入,修改数据时不会找到目标记录进行修改 还是新增一条相同key的记录,把value设置为新值
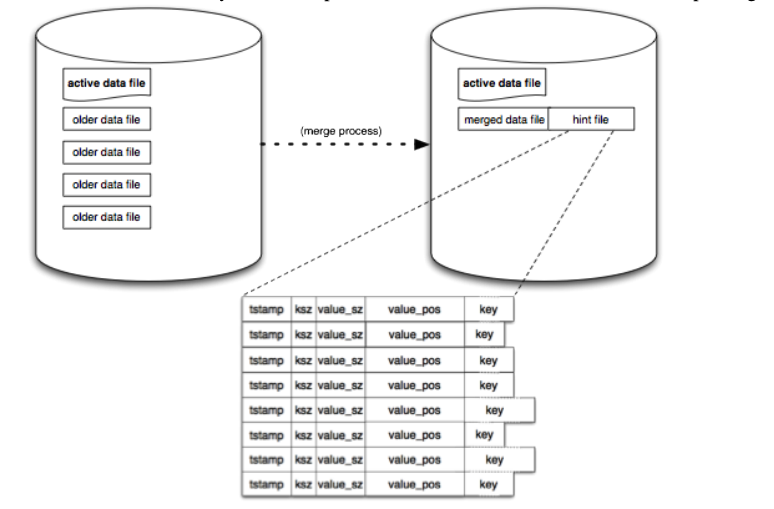
- 旧数据处理:Bitcask会定期进行Marge操作,扫描所有旧数据文件中的数据,生成新的数据文件 扫描时,把已经被置为删除状态的记录直接过滤掉,修改过的数据,只保留时间最近的一条
- Marge 操作:会遍历所有不可变的旧数据文件,将所有有效的数据重新写到新的数据文件中,并且将旧的数据文件删除掉。
tiny-bitcask 实现
在上面介绍了 bitcask 的基本概念后,我们知道了 bitcask 大概有哪些部分
- Entry:代表DB中一条数据的信息。
- DataFiles:磁盘中的文件
- Storage:与文件系统打交道的对象,包括了写入,读取数据。将数据写入到 DataFiles 中
- Index,索引,记录一条数据的具体信息,主要是数据在磁盘中的位置。
- DB,DB的实体。包含了DB的各种操作,包括读取,写入数据。
数据结构
DB 结构
type DB struct {
rw sync.RWMutex // 读写锁
kd *index.KeyDir // 内存index
storage *storage.DataFiles // 文件
opt *Options // 参数
}
Entry 结构
Entry 的结构 就是对应着 Bitcask 的文件格式,其中 Flag 是用来标识是否是删除的记录
type Entry struct {
Key []byte
Value []byte
Meta *Meta
}
type Meta struct {
Crc uint32
position uint64
TimeStamp uint64
KeySize uint32
ValueSize uint32
Flag uint8
}
一条数据是以怎么样的形式存进磁盘的。磁盘是不知道你存进来的数据是什么的,他只知道是一些二进制,至于那些二进制是什么,由放进来的应用程序来定义。所以,我们要对数据写入到磁盘的时候继续编码,也就是编码成二进制,其中我们的 Meta 这个结构体就是记录了我们的数据的一些圆信息,我们要利用这些信息进行编码。
func (e *Entry) Encode() []byte {
size := e.Size() // int64(MetaSize + e.Meta.KeySize + e.Meta.ValueSize)
buf := make([]byte, size)
binary.LittleEndian.PutUint64(buf[4:12], e.Meta.position) // 这里并没有实际作用
binary.LittleEndian.PutUint64(buf[12:20], e.Meta.TimeStamp) // 时间戳
binary.LittleEndian.PutUint32(buf[20:24], e.Meta.KeySize) // key 大小
binary.LittleEndian.PutUint32(buf[24:28], e.Meta.ValueSize) // value 大小
buf[28] = e.Meta.Flag
if e.Meta.Flag != DeleteFlag {
copy(buf[MetaSize:MetaSize+len(e.Key)], e.Key)
copy(buf[MetaSize+len(e.Key):MetaSize+len(e.Key)+len(e.Value)], e.Value)
}
c32 := crc32.ChecksumIEEE(buf[4:])
binary.LittleEndian.PutUint32(buf[0:4], c32) // 写入CRC
return buf
}
DataFiles 磁盘文件
type DataFiles struct {
dir string // 数据目录
oIds []int // old data files 的文件列表
segmentSize int64
active *ActiveFile // active data file 文件
olds map[int]*OldFile // old data files 的文件列表
}
写入过程
Set: db 暴露出来的接口,写入一个key value 值
func (db *DB) Set(key []byte, value []byte) error {
db.rw.Lock()
defer db.rw.Unlock()
entry := entity.NewEntryWithData(key, value) // Entry
h, err := db.storage.WriterEntity(entry) // 写入到文件
if err != nil {
return err
}
db.kd.AddIndexByData(h, entry) // 更新内存 index
return nil
}
WriterEntity: 写入 Entity 到文件
func (af *ActiveFile) WriterEntity(e entity.Entity) (h *entity.Hint, err error) {
buf := e.Encode() // 编码
n, err := af.fd.WriteAt(buf, af.off) // 写入到 文件 offset
if n < len(buf) {
return nil, WriteMissDataErr
}
if err != nil {
return nil, err
}
h = &entity.Hint{Fid: af.fid, Off: af.off}
af.off += e.Size() // 更新文件下一个offset
return h, nil
}
AddIndexByData: 更新内存 index
// DataPosition means a certain position of an entity.Entry which stores in disk.
type DataPosition struct {
Fid int // 文件 fd
Off int64 // 所在文件的偏移量
Timestamp uint64
KeySize int
ValueSize int
}
func (kd *KeyDir) AddIndexByRawInfo(fid int, off int64, key, value []byte) {
index := newDataPosition(fid, off, key, value)
kd.Add(string(key), index) // 记录到内存
}
func newDataPosition(fid int, off int64, key, value []byte) *DataPosition {
dp := &DataPosition{}
dp.Fid = fid
dp.Off = off
dp.KeySize = len(key)
dp.ValueSize = len(value)
return dp
}
读取流程
Get:db 暴露出来的接口,读取一个key的值
// Get gets value by using key
func (db *DB) Get(key []byte) (value []byte, err error) {
db.rw.RLock()
defer db.rw.RUnlock()
i := db.kd.Find(string(key))
if i == nil {
return nil, KeyNotFoundErr
}
entry, err := db.storage.ReadEntry(i)
if err != nil {
return nil, err
}
return entry.Value, nil
}
ReadEntry:从文件中读取一个 Entry
func (dfs *DataFiles) ReadEntry(index *index.DataPosition) (e *entity.Entry, err error) {
dataSize := entity.MetaSize + index.KeySize + index.ValueSize
if index.Fid == dfs.active.fid {
return dfs.active.ReadEntity(index.Off, dataSize) // 从acive 文件中读取
}
of, exist := dfs.olds[index.Fid]// 从 old data file 中读取
if !exist {
return nil, MissOldFileErr
}
return of.ReadEntity(index.Off, dataSize)
}
func readEntry(fd *os.File, off int64, length int) (e *entity.Entry, err error) {
buf := make([]byte, length)
n, err := fd.ReadAt(buf, off) // 根据 key 在内存中读取问津啊对应的 offset 记录
if n < length {
return nil, ReadMissDataErr
}
if err != nil {
return nil, err
}
e = entity.NewEntry()
e.DecodeMeta(buf[:entity.MetaSize])
e.DecodePayload(buf[entity.MetaSize:]) // 解码,从磁盘数据还原成写入时的数据
return e, nil
}
Marge 操作
Marge 操作的流程就是
- 获取到old data file
- 看下当前内存 index中有没有数据,这条数据可能被删除了,如果在内存index 没有找到,就是被删除了,不需要处理
- 比较一些当前读到的这个数据是不是最新的数据,如果是,则需要写入到 active data file 中
- 遍历完成一个之后,就删除老的文件,继续遍历下一个
// Merge clean the useless data
func (db *DB) Merge() error {
db.rw.Lock()
defer db.rw.Unlock()
fids := db.storage.GetOldFiles()
if len(fids) < 2 {
return NoNeedToMergeErr
}
sort.Ints(fids)
for _, fid := range fids[:len(fids)-1] {
var off int64 = 0
reader := db.storage.GetOldFile(fid) // 获取到old data file
for {
entry, err := reader.ReadEntityWithOutLength(off) // 读取一条数据
if err == nil {
key := string(entry.Key)
off += entry.Size()
oldIndex := db.kd.Find(key) // 看下当前内存 index中有没有数据,这条数据可能被删除了
if oldIndex == nil {
continue
}
// oldIndex 是这个 key 最新的文件
if oldIndex.IsEqualPos(fid, off) { // 比较一些当前读到的这个数据是不是最新的数据,如果是,则需要写入到 active data file 中
h, err := db.storage.WriterEntity(entry)
if err != nil {
return err
}
db.kd.AddIndexByData(h, entry) // 更新内存index
}
} else {
if err == io.EOF {
break
}
return err
}
}
err := db.storage.RemoveFile(fid) // 删除老的文件
if err != nil {
return err
}
}
return nil
}
总结
- 大部分接触的KV存储引擎是可能都是Redis。Redis的所有数据都是装在内存的,也可以根据配置持久化在磁盘里面,但是读都是从内存里面读的,这意味着redis的读写速度都非常快。
- 但是这有一个限制,那就是单机Redis存储的数据不能大于内存本身。而Bitcask的最大限制是内存必须装得下所有的key,因为Bitcask的value是存在磁盘上的。所以相比Redis,Bitcask的存在意义不是和redis比速度,而是当你的数据用Redis存不下的时候,可以考虑稍微损失读取效率,试试Bitcask。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











