






几个概念:
1.translation unit:由#include 所包含的并
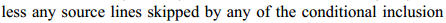
(我想这里原文的意思应该是除去像#ifdef #endif 这样不满足条件的一部分代码,不包含在内吧,实际上应该是编译器编译阶段所处理的代码就是,translation unit,但按照原文的意思应该不包括预编译代码)
2.1 phase of translation

这里所说所有的源文件都需要被映射位basic source character set(2.2的概念,见下文),通过这里我们知道所有的源代码都将被转化为标准字符,例如一些转义字符。\uXXXX unicode编码都将被转义。

第二点说每个换行字符和backslash 即 ‘\’字符都会被删除以将源码转化为逻辑上的形式。这里说如果文件末尾不是换行符的话将会产生 未定义的行为,故而文件末尾必须加上回车或者是换行转义字符
还有值得注意的是
“””
If a character sequence that matches the syntax of a universal-character-name is produced by token concatenation (16.3.3), the
behavior is undefined. A #include preprocessing directive causes the named header or source file to be processed from phase 1 through phase 4, recursively.
“””
这里是说如果一个字符序列和一个通用字符的语法匹配的话这种行为是未定义的,重点又说#include 所包含的文件会递归的处理,其转义字符会在包含到此文件之前就已经被转换了。
2.2 Character sets
basic source character set:包含96个字符,他们是
the space character
the control characters representing horizontal tab,
vertical tab,
form feed,
and new-line
和
a b c d e f g h i j k l m n o p q r s t u v w x y z
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
0 1 2 3 4 5 6 7 8 9
_ { } [ ] # ( ) < > % : ; . ? * + - / ˆ & | ˜ ! = , \ ” ’
这些,组成了源文件的字符集,也就是说,c++源文件只能包含这里96个字符以内的字符,那么就是说中文字符在这里将会被转义成基本字符串,中文字符的识别需要设置其编码方式,才能被解码,不然以默认编码方式可能会出现乱码。所以对于c++来说他是不是别中文的,只能通过编译器和操作系统相关的函数来进行编码和解码。
如 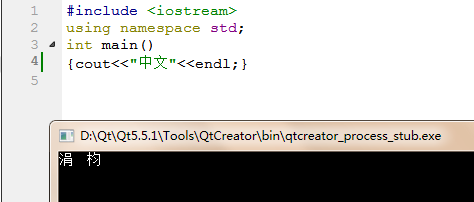
故而编程时注意设置相关的编码方式。
对于universal-character-name

这一概念为c++提供了一种方式使用十六进制数的组合表示其他的字符,
如字符‘的’,‘の‘之类。但是据这种机制来说只有4个16进制数或者8个16进制数来表示,即,16位和32位表示方法分别用\u 和\U开头。符合这一机制的标准是 ISO/IEC 10646,即发展为现在的unicode编码方式,现在来看几个实例。
这里先引用stackoverflow上一个人的提问,他表示编译出错,不完整的
universal-character-name 是因为 ofstream myfile (“C:\Users\My Name\Desktop\test\input.txt”);这一句中C:\U这个指代32位的unicode字符,16进制数中没有s字符故而编译器认为字符是\U 就是什么都没,故而报错所以记得在每个路径\前面在加一个\是正确的做法。
2.3 Trigraph sequences这个是古老的用法,现在已经没人用了,
2.4 Preprocessing tokens:
header-name + identifier + pp-number + character-literal + string-literal + preprocessing-op-or-punc +
each non-white-space character that cannot be one of the above
预处理记号包括:关键字、标识符、常量、字符串字面值、include预处理指令中的文件名标识和符号
2.6 Tokens
一共有5种token 即标识符,关键词,literal(包括字符串和数字,boolean数值)
操作符 和其他的separators。
There are five kinds of tokens: identifiers, keywords, literals,18) operators, and other separators.
如对于##宏来说,他的左右两个都必须是token,并且他的产生物也必须是token所以有 +##= 是正确的,而“abc”##”def”错误,因为”abc”“def”并不是token,”abcdef”才是token,故而会报错。
本章还有一个值得注意的地方是字符串前加L表示其由宽字符组成。所有的string literal将获得静态的存储周期















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









