







此小练都是一些裸的字典树的小练,主要是熟练字典树的运用;
题目参考自其他博客,在此就不一一贴出了;
字典树模板:点击打开链接
/****************************************字典树****************************************/
①uva1401 : remember the word (dp+字典树)
题意:给一个长串,若干短串,问长串可以被短串构成的种数,短串可重复使用;
思路:dp+字典树,转移方程:dp[i]=sum{dp[i]+len(x)|x是i~len前缀},具体看刘汝佳大白书209页;
转载 http://www.cnblogs.com/WABoss/p/5163511.html
代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define NODE 1000006
#define mod 20071027
int nex[NODE][26];
int v[NODE];
int node;
int dp[NODE];
void init()
{
node=1;
memset(nex[0],0,sizeof(nex[0]));
memset(dp,0,sizeof(dp));
}
int add(char *str)
{
int cur=0,k;
int len=strlen(str);
for(int i=0; i<len; i++)
{
k=str[i]-'a';
if(!nex[cur][k])
{
memset(nex[node],0,sizeof(nex[node]));
v[node]=0; //清空操作;
nex[cur][k]=node++;
}
cur=nex[cur][k];
}
v[cur]++;
}
int main()
{
int n;
char S[300005];
char s[110];
int cas=0;
while(scanf("%s",S)!=EOF)
{
init();
scanf("%d",&n);
while(n--)
{
scanf("%s",s);
add(s);
}
int len=strlen(S);
dp[len]=1;
for(int i=len-1; i>=0; i--)
{
int u=0,x;
for(int j=i; j<len; j++)
{
x=S[j]-'a';
if(nex[u][x]==0)
break; //
u=nex[u][x]; //
if(v[u])
dp[i]=(dp[i]+dp[j+1])%mod;
}
}
printf("Case %d: %d\n",++cas,dp[0]);
}
return 0;
}②hdu1521:统计难题
题意:给定一个单词表的集合,然后给定询问串,问有多少个以询问串为前缀的单词;
代码:
#include<cstdio>
#include<cstring>
#define NODE 1000005
int next[NODE][26];
int v[NODE];
int node;
void init() //初始化;
{
node=1; //节点个数;
memset(next[0],0,sizeof(next[0]));
}
void add(char *str) //加入
{
int cur=0,k;
int len=strlen(str);
for(int i=0;i<len;i++)
{
k=str[i]-'a';
if(next[cur][k]==0)
{
memset(next[node],0,sizeof(node));
v[node]=0; //清空操作;
next[cur][k]=node++;
}
cur=next[cur][k];
v[cur]++;
}
}
int cal(char *str) //查询
{
int cur=0,k;
int len=strlen(str);
for(int i=0;i<len;i++)
{
k=str[i]-'a';
if(next[cur][k])
cur=next[cur][k];
else
return 0;
}
return v[cur];
}
int main()
{
char str[20];
init();
while(1)
{
gets(str);
if(str[0]=='\0')
break;
add(str);
}
while(scanf("%s",str)!=EOF)
{
printf("%d\n",cal(str));
}
return 0;
}③ hdu1671:Phone List
题意:判断所给字串中是否有的字符串是其他字符串的前缀,有则输出NO;
思路:对于所有字符串先询问再插入,开标记数组标记字符串的末尾字符编号;
两种情况:1.寻找自己的过程中遇到完整的字符串,说明有字符串是他的前缀;
2.把自己找完了,发现最后一个字符还与其他字符相连,说明自己是其他字符串的前缀;
代码:
#include<cstdio>
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
#define NODE 1000006
int nex[NODE][10];
int v[NODE],biao[NODE];
int node;
int flag;
void init()
{
node=1;
memset(nex[0],0,sizeof(nex[0]));
// memset(biao,0,sizeof(biao));
}
void add(char *str)
{
int cur=0,k;
int len=strlen(str);
for(int i=0; i<len; i++)
{
k=str[i]-'0';
if(!nex[cur][k])
{
memset(nex[node],0,sizeof(nex[node]));
v[node]=0,biao[node]=0; //清空操作;
nex[cur][k]=node++;
}
cur=nex[cur][k];
v[cur]++;
}
biao[cur]=1;
}
void cal(char *str)
{
int cur=0,k;
int len=strlen(str);
for(int i=0; i<len; i++)
{
k=str[i]-'0';
if(nex[cur][k])
{
cur=nex[cur][k];
if(biao[cur]) flag=1;
}
else
return;
}
if(v[cur]>=1) flag=1;
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
init();
int n;
scanf("%d",&n);
flag=0;
char s[20];
for(int i=1; i<=n; i++)
{
scanf("%s",s);
cal(s);
add(s);
}
if(flag)
puts("NO");
else
puts("YES");
}
return 0;
}题意:比较任意两个字符串,如果两个字符串相同则比较了(长度+1)*2次即(公共前缀*2+2)次,如果两个字符串不同则比较了(公共前缀*2+1)次;
思路:利用字典树,不过如果用儿子节点表示法的话,内存可能超限(试过了不超),所以使用左儿子右兄弟的存储方法,利用此方法构成的是一棵二叉树。我们每要插入一字符串就会与之前所有插过的串相比。所有的串至少是要比一次的,如果串相同那就多比了一次,其他的就是:计算各字符的贡献!最后答案是ans+n*(n-1)/2;
代码:
#include<bits/stdc++.h>
#define N 4100000
#define ll long long
struct node
{
char c;
int l,r;
int val; //经过节点次数
int cut; //以节点为尾节点的次数
}trie[N];
int node;
ll ans=0;
void init()
{
node=1;
memset(trie,0,sizeof(trie));
}
void insert1(char *s)
{
int rt,i;
for(rt=0;*s;s++,rt=i)
{
for(i=trie[rt].l;i;i=trie[i].r)
{
if(trie[i].c==*s)
break;
}
ans+=trie[i].val<<1;
if(i==0)
{
trie[node].r=trie[rt].l;
trie[node].l=0;
trie[node].c=*s;
trie[rt].l=node;
i=node++;
}
trie[i].val++;
}
ans+=trie[rt].cut;
trie[rt].cut++;
}
int main()
{
int n,cas=1;
char s[1100];
while(scanf("%d",&n)!=EOF)
{
if(n==0) break;
ans=0;
init();
for(int i=0;i<n;i++)
{
scanf("%s",s);
insert1(s);
// printf("%d\n",ans);
}
printf("Case %d: %lld\n",cas++,ans+n*(n-1)/2);
}
return 0;
}
/*
2
a
b
4
mat
hat
sir
fat
2
nyoj
nyist
*/
耗内存的儿子节点表示法:
#include<bits/stdc++.h>
#define ll long long
#define N 4100000
int nex[N][80];
int val[N],cut[N];
int node;
void init()
{
memset(nex[0],0,sizeof(nex[0]));
node=1;
}
ll ans=0;
void add(char *s,int T)
{
int cur=0,k;
int len=strlen(s);
for(int i=0; i<len; i++)
{
k=s[i]-'0';
if(!nex[cur][k])
{
memset(nex[node],0,sizeof(nex[node]));
val[node]=0,cut[node]=0;
nex[cur][k]=node++;
}
cur=nex[cur][k];
ans+=val[cur]<<1;
val[cur]++;
}
ans+=cut[cur];
cut[cur]++;
// printf("%d\n",ans);
}
int main()
{
int n,cas=1;
while(scanf("%d",&n)&&n)
{
init();
char s[1100];
ans=0;
for(int i=1; i<=n; i++)
{
scanf("%s",s);
add(s,i);
}
printf("Case %d: %lld\n",cas++,ans+n*(n-1)/2);
}
return 0;
}
/****************************************01字典树****************************************/
题目类型:两两异或求异或所得最大值、连续子序列异或最大值
参考:http://blog.csdn.net/chy20142109/article/details/50704324
题意:输入一个含n个元素的序列A,求所有lowbit(Ai xor Aj) ( i,j∈[1,n]) 的和;
思路:先考虑 lowbit ( ) 的性质:lowbit等于从低位儿开始第一个不等于0的位置对应的值,比如lowbit(13)=1,13=1101,第一个不等于0的就是第一位儿。那么我们就
是统计它一路到底与它的同位儿相异的个数*该位儿的值(贡献)
这一题存的01串要从低位儿开始存,样例模拟一下:10 12 4
代码:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define por(i,j,k) for(int i=j;i<=k;i++)
#define nor(i,j,k) for(int i=j;i>=k;i--)
#define clean(x,y) memset(x,y,sizeof(x))
#define ll long long
#define mod 998244353
#define N 1550000
int nex[N][2];
int val[N];
int node;
void init()
{
node=1;
clean(nex[0],0);
val[0]=0;
}
void add(int c)
{
int cur=0,k;
por(i,0,29)
{
k=c&1;
if(!nex[cur][k])
{
clean(nex[node],0);
val[node]=0;
nex[cur][k]=node++;
}
cur=nex[cur][k];
val[cur]++;
c>>=1;
}
}
ll cal(int c)
{
int cur=0,k;
ll ans=0,value=1;
por(i,0,29)
{
k=c&1;
ans+=val[nex[cur][1-k]]*value;
cur=nex[cur][k];
value<<=1;
c>>=1;
}
return ans;
}
int main()
{
int t,cas=0;
scanf("%d",&t);
while(t--)
{
int n;
ll ans=0;
init();
scanf("%d",&n);
por(i,1,n)
{
int x;
scanf("%d",&x);
add(x);
ans+=cal(x);
//cout<<ans<<endl;
if(ans>=mod) ans%=mod;
}
printf("Case #%d: ",++cas);
printf("%I64d\n",ans*2%mod);
}
return 0;
}② hdu 5536 Chip Factory
题意:输入长为n的序列,计算
maxi,j,k
(s
i
+s
j
)⊕s
k
,其中i , j , k各不相同;
思路:先把序列的所有元素存到字典树中,然后枚举i,j 删除si,sj,查询完之后再加进去;
求与x异或后的最大值找到与其二进制不同的最多的那个数来异或;
//学习到了思路,枚举删除的思路
//学习到了字典树的标记;:
1.标记经过某个节点的次数;
2.标记某个节点作为结尾的次数;
3.本题就是每个数都是按照30位二进制插入,到最后第三十层每一个数都有自己的结尾节点,在结尾节点保存的就是这个数的十进制值!
代码:
#include<iostream>
#include<cmath>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define por(i,j,k) for(int i=j;i<=k;i++)
#define nor(i,j,k) for(int i=j;i>=k;i--)
#define clean(x,y) memset(x,y,sizeof(x))
#define ll long long
#define mod 998244353
#define N 50005
int nex[N][2];
int num[N],val[N];
int a[N];
int node;
void init()
{
node=1;
clean(nex,0);
clean(num,0);
clean(val,0);
}
void add(int c)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
if(!nex[cur][k])
nex[cur][k]=node++;
cur=nex[cur][k];
num[cur]++;
}
val[cur]=c;
}
ll cal(int c)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
if(nex[cur][1-k]&&num[nex[cur][1-k]])
cur=nex[cur][1-k];
else
cur=nex[cur][k];
}
return c^val[cur];
}
void del(int c,int d)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
cur=nex[cur][k];
num[cur]+=d;
}
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
init();
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
add(a[i]);
}
ll maxx=0;
for(int i=1;i<n;i++)
{
del(a[i],-1);
for(int j=i+1;j<=n;j++)
{
del(a[j],-1);
maxx=max(maxx,cal(a[i]+a[j]));
del(a[j],1);
}
del(a[i],1);
}
printf("%I64d\n",maxx);
}
return 0;
}③ hdu 4825 Xor Sum
题意:给定一个n元素的集合,m次询问每次给定一个数,问与集合中那个数异或值最大并输出那个数字;
思路:
代码:
#include<iostream>
#include<cmath>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define por(i,j,k) for(int i=j;i<=k;i++)
#define nor(i,j,k) for(int i=j;i>=k;i--)
#define clean(x,y) memset(x,y,sizeof(x))
#define ll long long
#define mod 998244353
#define N 5000000
int nex[N][2];
int num[N];
int val[N];
int node;
void init()
{
node=1;
clean(nex,0);
clean(num,0);
clean(val,0);
}
void add(int c)
{
int cur=0,k;
nor(i,31,0)
{
k=(c>>i)&1;
if(!nex[cur][k])
nex[cur][k]=node++;
cur=nex[cur][k];
num[cur]++;
}
val[cur]=c;
}
int cal(int c)
{
int cur=0,k;
nor(i,31,0)
{
k=(c>>i)&1;
if(nex[cur][1-k]&&num[nex[cur][1-k]])
cur=nex[cur][1-k];
else
cur=nex[cur][k];
}
return val[cur]; //
}
int main()
{
int t,cas=0;
scanf("%d",&t);
while(t--)
{
init();
int n,m;
scanf("%d%d",&n,&m);
por(i,1,n)
{
int x;
scanf("%d",&x);
add(x);
}
printf("Case #%d:\n",++cas);
por(i,1,m)
{
int x;
scanf("%d",&x);
printf("%d\n",cal(x));
}
}
return 0;
}④poj 3764 The xor-longest Path
题意:给定一棵数,每条边都有边权,一条路径的异或长度就是这条路径上所有边的异或值
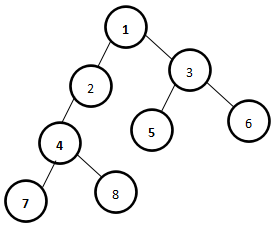
思路:异或性质 x^y = (0^x) ^ (0^y) ;以0点为源点,保存各节点到源点这条路径的异或长度值到a[]。这个问题就转化为求a数组两两异或值的最大值!
代码:
#include<iostream>
#include<cmath>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define por(i,j,k) for(int i=j;i<=k;i++)
#define nor(i,j,k) for(int i=j;i>=k;i--)
#define clean(x,y) memset(x,y,sizeof(x))
#define ll long long
#define mod 998244353
#define N 3005000
int ch[N][2];
int val[N];
int node,cnt;
int head[100010],nod[100010];
struct info
{
int to,v;
int nex;
} edge[100010];
void add_edge(int from,int to,int val)
{
edge[++cnt].to=to;
edge[cnt].v=val;
edge[cnt].nex=head[from];
head[from]=cnt;
}
void init()
{
cnt=0;
node=1;
clean(ch[0],0);
clean(edge,0);
clean(nod,0);
clean(head,0);
}
void add(int c)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
if(!ch[cur][k])
{
clean(ch[node],0);
val[node]=0;
ch[cur][k]=node++;
}
cur=ch[cur][k];
}
val[cur]=c;
}
ll cal(int c)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
if(ch[cur][1-k])
cur=ch[cur][1-k];
else
cur=ch[cur][k];
}
return val[cur]^c;
}
int main()
{
int n;
while(scanf("%d",&n)!=EOF)
{
init();
por(i,1,n-1)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add_edge(min(a,b),max(a,b),c);
}
for(int i=0; i<n; i++)
for(int j=head[i]; j; j=edge[j].nex)
nod[edge[j].to]=nod[i]^edge[j].v;
ll maxx=0;
por(i,1,n)
{
add(nod[i]);
maxx=max(maxx,cal(nod[i]));
}
printf("%I64d\n",maxx);
}
return 0;
}题意:输入有n个元素的序列,从序列中找到两个不想交的区间,求两个区间的异或值的和的最大值;
思路:分别序列的前缀异或和与后缀异或和;然后枚举序列中元素计算 【1~i 的异或和 + (i+1)~n的异或和】
代码:
#include<iostream>
#include<cmath>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define por(i,j,k) for(int i=j;i<=k;i++)
#define nor(i,j,k) for(int i=j;i>=k;i--)
#define clean(x,y) memset(x,y,sizeof(x))
#define ll long long
#define mod 998244353
#define N 15000000
int nex[N][2];
int val[N];
int a[500005],pre[500005],suf[500005];
ll dp[500005];
int node;
void init()
{
clean(nex[0],0);
node=1;
}
void add(int c)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
if(!nex[cur][k])
{
clean(nex[node],0);
val[node]=0;
nex[cur][k]=node++;
}
cur=nex[cur][k];
}
val[cur]=c;
}
ll cal(int c)
{
int cur=0,k;
nor(i,30,0)
{
k=(c>>i)&1;
if(nex[cur][1-k])
cur=nex[cur][1-k];
else
cur=nex[cur][k];
}
return val[cur]^c;
}
int main()
{
int n;
while(scanf("%d",&n)!=EOF)
{
init();
pre[0]=suf[n+1]=0;
por(i,1,n) scanf("%d",&a[i]);
por(i,1,n) pre[i]=pre[i-1]^a[i];
nor(i,n,1) suf[i]=suf[i+1]^a[i];
clean(dp,0);
add(pre[0]);
por(i,1,n)
{
dp[i]=max(dp[i-1],cal(pre[i]));
add(pre[i]);
}
ll maxx=0;
init();
add(suf[n+1]);
nor(i,n,1)
{
maxx=max(maxx,dp[i-1]+cal(suf[i]));
add(suf[i]);
}
printf("%lld\n",maxx);
}
return 0;
}
题意:输入一个含n个元素的序列,求子序列异或值最大值是多少,并且输出此子序列的开头结尾下标,如果子序列的值一样,选择结尾下标较小的,还是相同?选择较短的那条序列!
思路:利用前缀异或值数组;计算出连续子序列异或值最大是多少,因为是按序输入所以不用处理结尾下标较小,如果有两个前缀值相同,则后来的回更新前面已经存在的,这会保证选择的是较短的那条序列;
代码:
#include<iostream>
#include<cmath>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define por(i,j,k) for(int i=j;i<=k;i++)
#define nor(i,j,k) for(int i=j;i>=k;i--)
#define clean(x,y) memset(x,y,sizeof(x))
#define ll long long
#define mod 998244353
#define N 2005000
int nex[N][2];
struct info
{
int v,id;
}val[N];
int node;
int pre[100100];
void init()
{
node=1;
clean(nex[0],0);
clean(pre,0);
}
void add(int c,int idx)
{
int cur=0,k;
nor(i,20,0)
{
k=(c>>i)&1;
if(!nex[cur][k])
{
clean(nex[node],0);
val[node].id=0,val[node].v=0;
nex[cur][k]=node++;
}
cur=nex[cur][k];
}
val[cur].id=idx;
val[cur].v=c;
}
info cal(int c)
{
int cur=0,k;
nor(i,20,0)
{
k=(c>>i)&1;
if(nex[cur][1-k])
cur=nex[cur][1-k];
else
cur=nex[cur][k];
}
return val[cur];
}
int main()
{
int n;
while(scanf("%d",&n)!=EOF)
{
init();
por(i,1,n)
{
int x;
scanf("%d",&x);
pre[i]=pre[i-1]^x;
}
// por(i,1,n)
// cout<<pre[i]<<" ";
// cout<<endl;
int ans=0,ans_l=0,ans_r=0;
info an;
add(pre[0],0);
por(i,1,n)
{
add(pre[i],i);
an=cal(pre[i]),an.v^=pre[i];
if(an.v>ans) //选最大的
{
ans=an.v;
ans_l=(an.id+1);
ans_r=i;
// printf("%d : ans:%d l:%d\n",i,an.v,an.id);
}
}
printf("%d %d %d\n",ans,ans_l,ans_r);
}
return 0;
}
学习时间有点长了,近一周














 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









