







大家好,这里是船长,一个AI+RPA探索者。如果你对以下内容感兴趣,欢迎加我VX交流:TXZO1006
最近和一些朋友聊天,发现不管是什么自媒体平台,无论是在起步的时候,还是寻找灵感的时候,都需要找一些对标账号进行学习模仿。
因为对标账号的内容往往容易成为热门,一定是有其独到之处。比如标题很吸引人,内容风格新颖,观点独特等等。
这种方式很适合一些入门小白或者不太擅长创作的运营者,不仅可以学到一些爆文技巧,提高写作技能;而且能训练自己快速制作热门内容的水平。
毕竟多数自媒体的内容是用来给用户看的,而不是用来自嗨的。
不然写的内容再好,再有价值,只要用户不喜欢,那么数据就不可能会好。
所以,今天船长给大家分享的是如何使用影刀PRA,实现批量采集对标公众号内容。
效果演示
最近发现公众号管理后台改版了,可以直接搜索其他公众号的所有发布内容。这样一来就可以直接在网页上采集公众号信息,再也不用费劲的在微信软件上搞各种元素定位了。
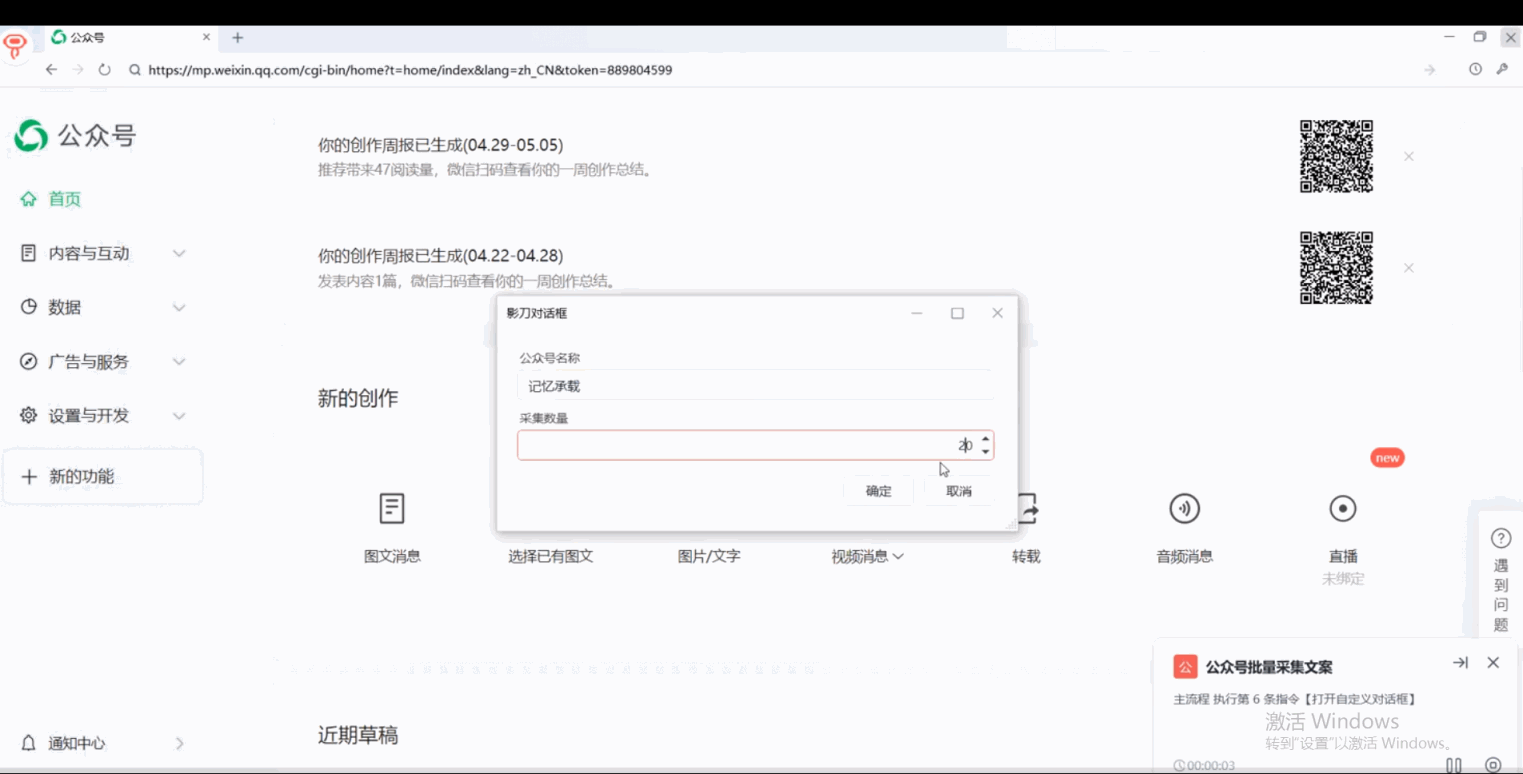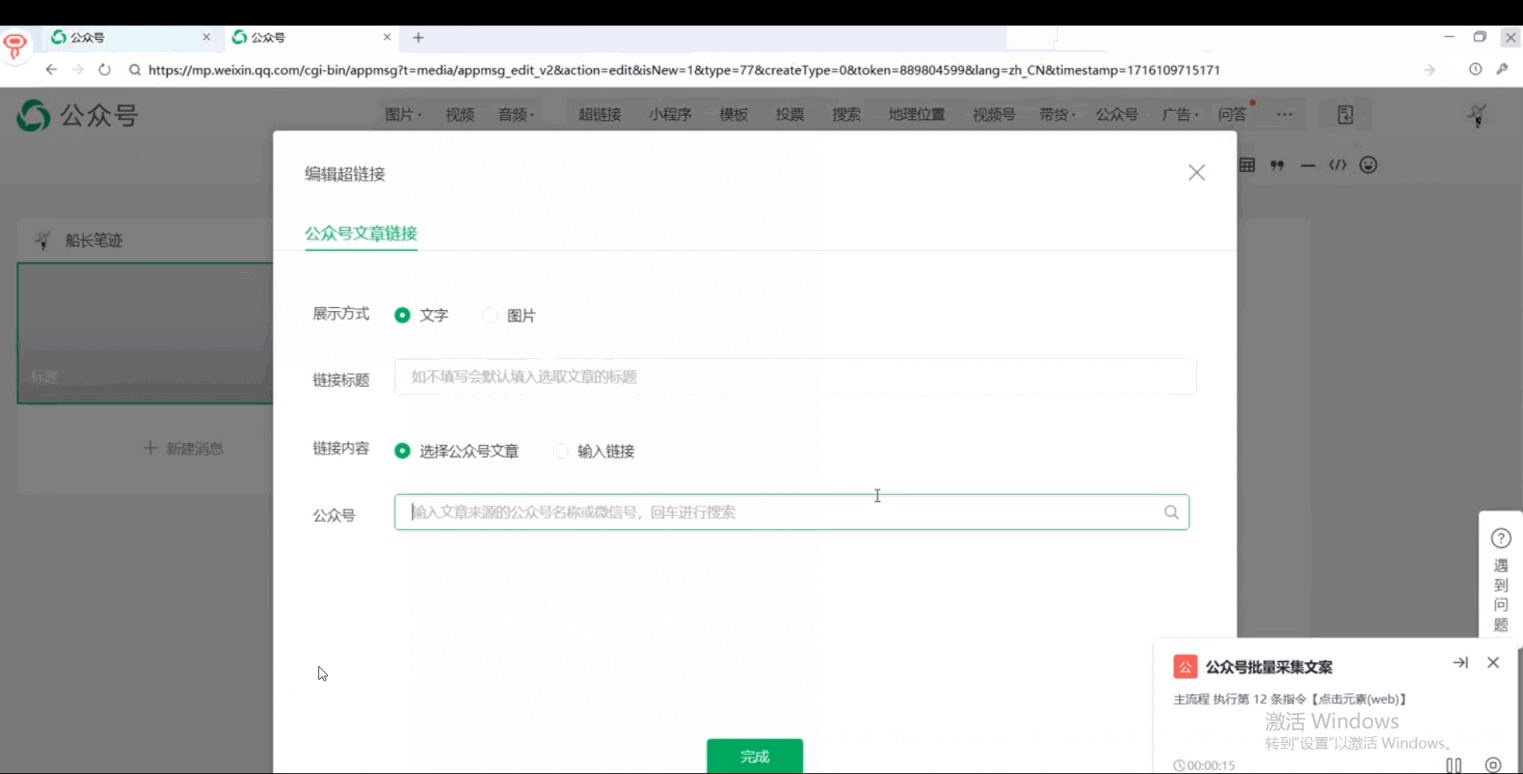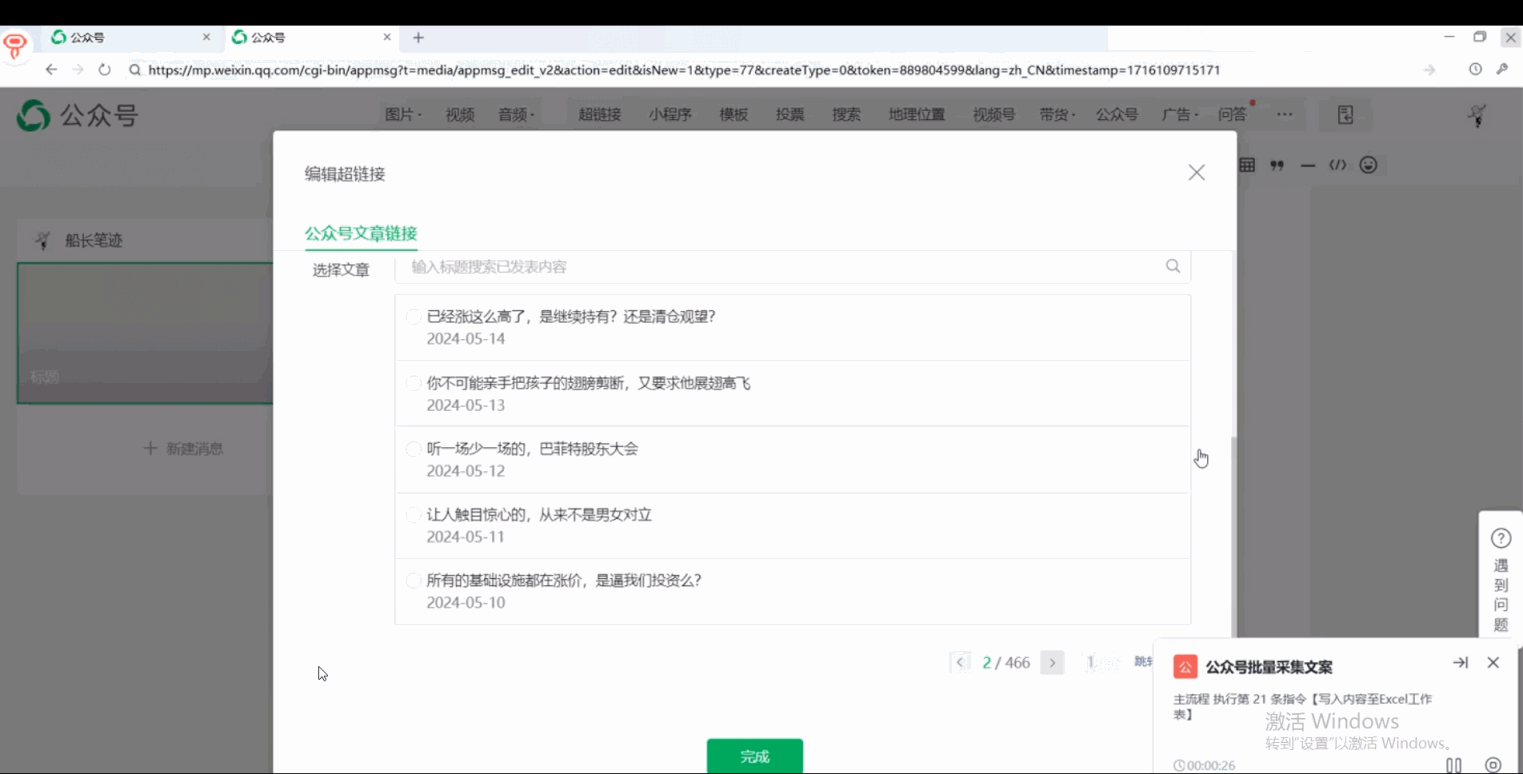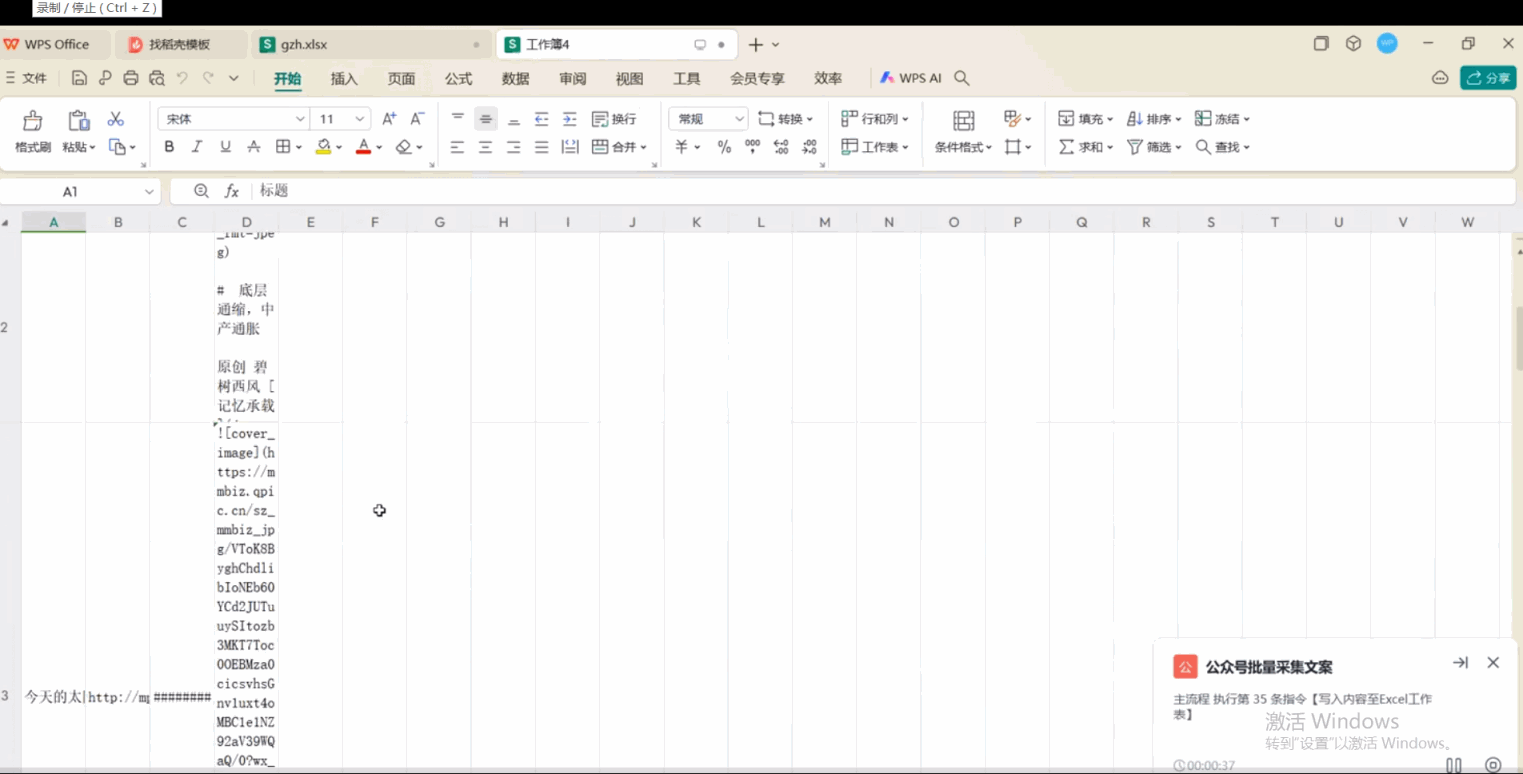
可以看到就两三步操作,就采集到了目标公众号文章的基础信息内容。
如何获得
如果你对这款RPA机器人感兴趣,也想尝试一下,可以关注船长的公众号“船长笔迹”,并回复关键字“
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3033
3033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









