









引言
最近在读西瓜书,查阅了多方资料,恶补了数值代数、统计概率和线代,总算是勉强看懂了西瓜书中的公式推导。但是知道了公式以后还是要学会应用的,几经摸索发现python下的sklearn包把机器学习中经典的算法都封装好了,因此,打算写几篇博客记录一下sklearn包下的常用学习算法的使用,防止自己以后忘了,嘿嘿。
1.SVM
SVM,即支持向量机,其基本思路就是对于给定的数据样本,试图找到位于两类(或多类)样本“正中间”的一个划分超平面,把数据样本划分为不同的类,众所周知,在欧氏空间中的超平面g的标准方程为 w T + b = 0 w^T+b=0 wT+b=0,其中 w T w^T wT为超平面g的法向量, − b ∣ ∣ w ∣ ∣ \cfrac {-b} {||w||} ∣∣w∣∣−b为原点到超平面的距离。我们把距离超平面最近的样本点向量称之为“支持向量”,SVM的公式推导过程即为最大化支持向量距离超平面距离的最优化问题,在优化的过程中我们引入了对偶问题,KKT条件以及SMO算法等数学工具。并且根据模型容错能力的不同,需要分为hard-margin和soft-margin来分别进行推导。推导过程比较复杂,因此本文不作详细讨论。
2.sklearn下的SVM相关函数
sklearn.svm.SVC是一个进行SVM分类的包,支持多维向量的输入,并由2-分类问题推广到支持多分类问题,并且在现实世界中,很多数据并不是线性可分的,SVC甚至支持使用不同的核函数来进行非线性的分类,可以说是非常强大了。
参数说明
SVC函数中主要有以下几个超参数,在此简单做一些说明,详细的超参数含义以及使用方法请参照官方说明文档。
kernel: 代表核函数,如果是‘linear’代表构造一个线性分类器,这也是默认值,在使用linear时要保证样本数据是线性可分的。另外,在进行非线性分类时可选poly或者rbf,前者表示使用多项式核函数,后者表示使用高斯核函数进行分类
degree: 整型参数,表示指数,在kernel选择了poly时这一项可以指定多项式核函数的指数,默认值为3。
gamma: 是核函数的参数,在对非线性可分的数据进行学习时,SVM采用的方法是将数据映射到高维空间,并求在高维空间中找到一个超平面来划分数据,gamma决定了数据映射到新的高维特征空间后的分布,默认取‘auto’,即取数据特征维度的倒数。
C: 表示惩罚系数,我的理解就是正则化系数,防止过拟合的。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
decision_function_shape: 表示分类类型,ovo表示二分类,ovr表示多分类(多分类其实就是训练了多个二分类器,sklearn中有专门的sklearn.multiclass.OneVsRestClassifier来完成多分类任务,感兴趣的可以阅读相关文档和源码,此处不详述)。
3.代码演示
下面的代码分别演示了使用sklearn包下的SVC函数进行SVM线性和非线性分类的过程,第一段代码表示二分类,第二段代码表示多分类,使用sklearn自带的经典iris数据集进行实验:
二分类:
#本段代码使用sklearn包下的SVM函数进行二分类问题(线性和非线性分类)的解决
import numpy as np
import pandas as pd
from pandas import DataFrame
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC#SVC既可以进行线性分类,也可以进行非线性分类
iris=datasets.load_iris()
df=DataFrame(iris.data,columns=iris.feature_names)[['sepal length (cm)','sepal width (cm)']]#实测支持多维分类,为了方便,我们还是用二维特征数据
pd.set_option('display.width',None)
df["target"]=list(iris.target)
# print(df.columns)
df=df[df["target"]!=2]#二分类,去除数据集中的第三类数据
# print(df)
X = df.iloc[:,0:2].values#转成np.array类型以便作为参数传入分类器
Y=df.iloc[:,2].values
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
sc=StandardScaler()
sc.fit(X)
standard_train = sc.transform(X_train)
standard_test = sc.transform(X_test)
SVMClassifier=SVC(kernel="linear")#构建一个线性分类器
SVMClassifier.fit(standard_train,Y_train)
result=SVMClassifier.predict(standard_test)
print("线性分类器:")
print(list(Y_test))
print(list(result))
print(SVMClassifier.score(standard_test,Y_test))
SVMClassifier=SVC(kernel='poly',degree=3,gamma="auto")#构建一个非线性分类器,使用多项式函数作为核函数
SVMClassifier.fit(standard_train,Y_train)
result=SVMClassifier.predict(standard_test)
print("多项式核函数非线性分类器:")
print(list(Y_test))
print(list(result))
print(SVMClassifier.score(standard_test,Y_test))
SVMClassifier=SVC(kernel='rbf',gamma="auto")#构建一个非线性分类器,使用高斯核函数作为核函数
SVMClassifier.fit(standard_train,Y_train)
result=SVMClassifier.predict(standard_test)
print("高斯核函数非线性分类器:")
print(list(Y_test))
print(list(result))
print(SVMClassifier.score(standard_test,Y_test))
运行结果如图:
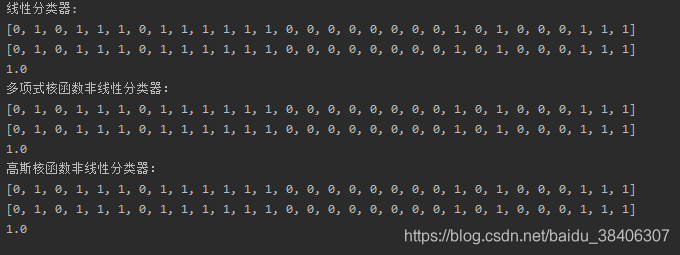 可以看到,2分类不论使用SVM的线性还是非线性分类器,在训练集上达到额百分之百的准确率(非线性只是把数据集映射到了高维空间),说明准确率还是相当高的.
可以看到,2分类不论使用SVM的线性还是非线性分类器,在训练集上达到额百分之百的准确率(非线性只是把数据集映射到了高维空间),说明准确率还是相当高的.
多分类:
from sklearn import datasets
import numpy as np
from pandas import DataFrame
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
iris=datasets.load_iris()
df=DataFrame(iris.data,columns=iris.feature_names)#[['sepal length (cm)','sepal width (cm)']]
df["target"]=list(iris.target)
X=df.iloc[:,0:4]
Y=df.iloc[:,4]
X_train,X_test,Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
sc=StandardScaler()
sc.fit(X)
standard_train=sc.transform(X_train)
standard_test=sc.transform(X_test)
SVMClassifier=SVC(kernel="linear",decision_function_shape='ovr',gamma='auto')
SVMClassifier.fit(standard_train,Y_train)
result=SVMClassifier.predict(standard_test)
print("线性分类器:")
print(list(Y_test))
print(list(result))
print(SVMClassifier.score(standard_test,Y_test))
SVMClassifier=SVC(kernel="poly",degree=3,decision_function_shape='ovr',gamma='auto')
SVMClassifier.fit(standard_train,Y_train)
result=SVMClassifier.predict(standard_test)
print("多项式核函数非线性分类器:")
print(list(Y_test))
print(list(result))
print(SVMClassifier.score(standard_test,Y_test))
SVMClassifier=SVC(kernel="rbf",decision_function_shape='ovr',gamma='auto')
SVMClassifier.fit(standard_train,Y_train)
result=SVMClassifier.predict(standard_test)
print("高斯核函数非线性分类器:")
print(list(Y_test))
print(list(result))
print(SVMClassifier.score(standard_test,Y_test))
运行结果如图:
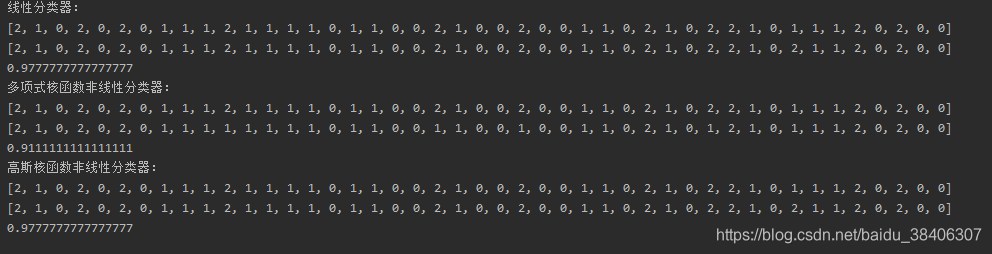 由于是多分类,所以第二度胺代码中我使用了iris数据集的全部属性,如果偶像第一段代码中那样只使用前两列数据来学习,因为丢失了维度,所以预测的正确率会大大降低,在使用了完整的数据集后,可以看到线性分类器和使用高斯核函数的非线性分类器预测准确率都几乎达到百分之九十八,可以说非常不错了。我们可以尝试着优化多项式核函数的非线性分类器,比如调整其最大次数,正则化系数等来提高其预测的正确率。
由于是多分类,所以第二度胺代码中我使用了iris数据集的全部属性,如果偶像第一段代码中那样只使用前两列数据来学习,因为丢失了维度,所以预测的正确率会大大降低,在使用了完整的数据集后,可以看到线性分类器和使用高斯核函数的非线性分类器预测准确率都几乎达到百分之九十八,可以说非常不错了。我们可以尝试着优化多项式核函数的非线性分类器,比如调整其最大次数,正则化系数等来提高其预测的正确率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









