






python
记录并解决自己在使用和学习python的过程中遇到的各种问题
尝试找到问题所在并解决
学无止境,以此记录自己才过的坑
1、pd.cut分类后的DataFrame列进行groupby()分组出现问题
分组后就算不存在数据的分类也会出现在groupby后的结果中
在使用pd.cut对列进行分类后,得到的列为‘里程类别’,该列类别为pandas._libs.interval.Interval,
取出部分数据得到a如下:

尝试四种分组计算方式
方式1:根据pd.cut分类后的列单独分组groupby后截取一列进行计算
b = a.groupby(['里程类别']).mileage.apply(lambda x: x[x > 100].shape[0]).reset_index().rename(columns ={'mileage': '数量'})
print(b)

(其中数量 2 为 numpy.int64)
方式2:根据pd.cut分类后的列单独分组groupby后截取全部列进行计算
b = a.groupby(['里程类别']).apply(lambda x: x[x.mileage > 100].shape[0]).reset_index().rename(columns ={0: '数量'})
print(b)
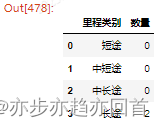
(其中数量 2 为 numpy.int64)
方式3:根据pd.cut分类后的列单独分组groupby后截取全部列进行计算
b = a.groupby(['里程类别', 'goods_name']).mileage.apply(lambda x: x[x > 100].shape[0]).reset_index().rename(columns ={'mileage': '数量'})
print(b)
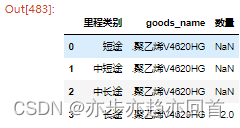
(其中数量 2.0 为numpy.float64)
方式4:根据pd.cut分类后的列单独分组groupby后截取全部列进行计算
b = a.groupby(['里程类别', 'goods_name']).apply(lambda x: x[x.mileage > 100].shape[0]).reset_index().rename(columns ={0: '数量'})
print(b)

(其中数量 2 为 numpy.int64)
存在疑问一:
可以发现,当只使用pandas._libs.interval.Interval类型的列里程类别进行分组groupby计算的时候,无论调用单独字段还是全部进行apply的时候都会出现其他的类别行,尽管没有对应的数据结果,
当使用多个字段进行groupby时,调用单个字段还是会出现这种情况,而调用全部再apply则不会出现这样的情况!!!
(本人在计算的时候发现这样就会导致groupby计算的多个列的行数与其他部分不匹配)
存在疑问二:
为什么方式三出来的结果是float型而不是int型
猜测:
方式3和4的区别是一个调用单独字段后计算,一个调用全部字段后计算
因此3中的x为Seris类型,取shape















 3990
3990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









