







以实现LeNet网络为例,来学习使用pytorch如何搭建一个神经网络。
LeNet网络的结构如下图所示。
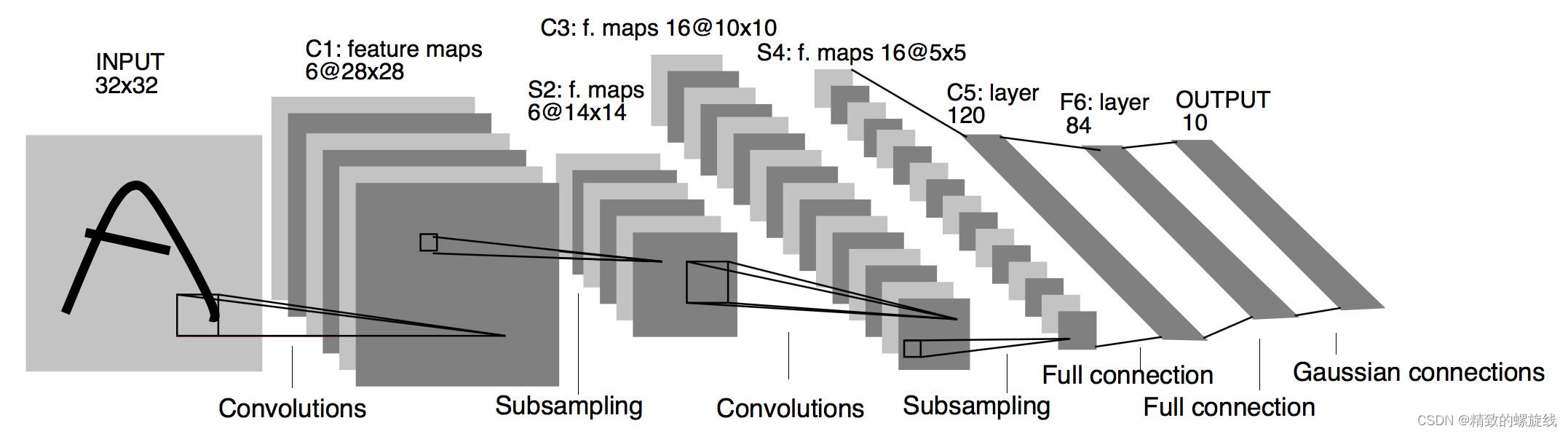

一、使用torch.nn.Module类构建网络模型
搭建自己的网络模型,我们需要新建一个类,让它继承torch.nn.Module类,并必须重写Module类中的__init__()和forward()函数。init()函数用来申明模型中各层的定义,forward()函数用来描述各层之间的连接关系,定义前向传播计算的过程。也就是说__init__()函数只是用来定义层,但并没有将它们连接起来,forward()函数的作用就是将这些定义好的层连接成网络。
使用上述方法实现LeNet网络的代码如下。
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.C1 = nn.Conv2d(1, 6, 5)
self.sig = nn.Sigmoid()
self.S2 = nn.MaxPool2d(2, 2)
self.C3 = nn.Conv2d(6, 16, 5)
self.S4 = nn.MaxPool2d(2, 2)
self.C5 = nn.Conv2d(16, 120, 5)
self.C6 = nn.Linear(120, 84)
self.C7 = nn.Linear(84, 10)
def forward(self, x):
x1 = self.C1(x)
x2 = self.sig(x1)
x3 = self.S2(x2)
x4 = self.C3(x3)
x5 = self.sig(x4)
x6 = self.S4(x5)
x7 = self.C5(x6)
x8 = self.C6(x7)
y = self.C7(x8)
return y
net = LeNet()
print(net)
结果为

在__init__()函数中,实例化了nn.Linear()、nn.Conv2d()这种pytorch封装好的类,用来定义全连接层、卷积层等网络层,并规定好它们的参数。例如,self.C1 = nn.Conv2d(1, 6, 5)表示定义一个卷积层,它的卷积核输入通道为1、输出通道为6,大小为5×5。真正向这个卷积层输入数据是在forward()函数中,x1 = self.C1(x)表示将输入x喂给卷积层,并得到输出x1。
二、引入torch.nn.functional实现层的运算
引入torch.nn.functional模块中的函数,可以简化__init__()函数中的内容。在__init__()函数中,我们可以只定义具有需要学习的参数的层,如卷积层、线性层,它们的权重都需要学习。对于不需要学习参数的层,我们不需要在__init__()函数中定义,只需要在forward()函数中引入torch.nn.functional类中相关函数的调用。
例如LeNet中,我们在__init__()中只定义了卷积层和全连接层。池化层和激活函数只需要在forward()函数中,调用torch.nn.functional中的函数进行实现即可。
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.C1 = nn.Conv2d(1, 6, 5)
self.C3 = nn.Conv2d(6, 16, 5)
self.C5 = nn.Conv2d(16, 120, 5)
self.C6 = nn.Linear(120, 84)
self.C7 = nn.Linear(84, 10)
def forward(self, x):
x1 = self.C1(x)
x2 = F.sigmoid(x1)
x3 = F.max_pool2d(x2)
x4 = self.C3(x3)
x5 = F.sigmoid(x4)
x6 = F.max_pool2d(x5)
x7 = self.C5(x6)
x8 = self.C6(x7)
y = self.C7(x8)
return y
net = LeNet()
print(net)
运行结果为

当然,torch.nn.functional中也对需要学习参数的层进行了实现,包括卷积层conv2d()和线性层linear(),但pytorch官方推荐我们只对不需要学习参数的层使用nn.functional中的函数。
对于一个层,使用nn.Xxx实现和使用nn.functional.xxx()实现的区别为:
- nn.Xxx是一个类,继承自nn.Modules,因此内部会有很多属性和方法,如train(), eval(),load_state_dict, state_dict 等。
nn.functional.xxx()仅仅是一个函数。 - 作为一个类,nn.Xxx需要先实例化并传入参数,然后以函数调用的方式向实例化对象中喂入输入数据。
conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding)
output = conv(input)
nn.functional.xxx()是在调用时同时传入输入数据和设置参数。
output = nn.functional.conv2d(input, weight, bias, padding)
- nn.Xxx不需要自己定义和管理权重,但nn.functional.xxx()需要自己定义权重,每次调用时要手动传入。
三、Sequential类
1. 基础使用
Sequential类继承自Module类。对于一个简单的序贯模型,可以不必自己再多写一个类继承Module类,而是直接使用pytorch提供的Sequential类,来将若干层或若干子模块直接包装成一个大的模块。
例如在LeNet中,我们直接将各个层按顺序排列好,然后用Sequential类包装一下,就可以方便地构建好一个神经网路了。
import torch.nn as nn
net = nn.Sequential(
nn.Conv2d(1, 6, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 120, 5),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
print(net)
print(net[2]) #通过索引可以获取到层
运行结果为

上面这种方法没有给每一个层指定名称,默认使用层的索引数0、1、2来命名。我们可以通过索引值来直接获对应的层的信息。
当然,我们也可以给层指定名称,但我们并不能通过名称获取层,想获取层依旧要使用索引数字。
import torch.nn as nn
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
('C1', nn.Conv2d(1, 6, 5)),
('Sig1', nn.Sigmoid()),
('S2', nn.MaxPool2d(2, 2)),
('C3', nn.Conv2d(6, 16, 5)),
('Sig2', nn.Sigmoid()),
('S4', nn.MaxPool2d(2, 2)),
('C5', nn.Conv2d(16, 120, 5)),
('C6', nn.Linear(120, 84)),
('C7', nn.Linear(84, 10))
]))
print(net)
print(net[2]) #通过索引可以获取到层
运行结果为

也可以使用add_module函数向Sequential()中添加层。
import torch.nn as nn
net = nn.Sequential()
net.add_module('C1', nn.Conv2d(1, 6, 5))
net.add_module('Sig1', nn.Sigmoid())
net.add_module('S2', nn.MaxPool2d(2, 2))
net.add_module('C3', nn.Conv2d(6, 16, 5))
net.add_module('Sig2', nn.Sigmoid())
net.add_module('S4', nn.MaxPool2d(2, 2))
net.add_module('C5', nn.Conv2d(16, 120, 5))
net.add_module('C6', nn.Linear(120, 84))
net.add_module('C7', nn.Linear(84, 10))
print(net)
print(net[2])
输出为

2. 使用Sequential类将层包装成子模块
Sequential类也可以应用到自定义Module类的方法中,用来将几个层包装成一个大层(块)。当然Sequential依旧有三种使用方法,我们这里只使用第一种作为举例。
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Conv2d(16, 120, 5),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x):
x1 = self.conv(x)
y = self.fc(x1)
return y
net = LeNet()
print(net)
输出为

四、ModuleList类和ModuleDict类
ModuleList类和ModuleDict类都是Modules类的子类,和Sequential类似,它也可以对若干层或子模块进行打包,列表化的构造网络。但与Sequential类不同的是,这两个类只是将这些层定义并排列成列表(List)或字典(Dict),但并没有将它们连接起来,也就是说并没有实现forward()函数。因此,这两个类并不要求相邻层的输入输出维度匹配,也不能直接向ModuleList和ModuleDict中直接喂入输入数据。
ModuleList的访问方法和普通的List类似。
net = nn.ModuleList([
nn.Linear(784, 256),
nn.ReLU()
])
net.append(nn.Linear(256, 20)) # ModuleList可以像普通的List以下进行append操作
print(net[-1]) # ModuleList的访问方法与List也相似
print(net)
# X = torch.zeros(1, 784)
# net(X) # 出错。向ModuleList中输入数据会出错,因为ModuleList的作用仅仅是存储
# 网络的各个模块,但并不连接它们,即没有实现forward()
输出为

ModuleDict的使用方法也和普通的字典类似。
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output)
print(net)
# net(torch.zeros(1, 784)) # 会报NotImplementedError
输出为

ModuleList和ModuleDict的使用是为了在定义前向传播时能更加灵活。下面是官网上的一个关于ModuleList使用的例子。
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x
此外,ModuleList和ModuleDict里,所有子模块的参数都会被自动添加到神经网络中,这一点是与普通的List和Dict不同的。举个例子。
class Module_ModuleList(nn.Module):
def __init__(self):
super(Module_ModuleList, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10)])
class Module_List(nn.Module):
def __init__(self):
super(Module_List, self).__init__()
self.linears = [nn.Linear(10, 10)]
net1 = Module_ModuleList()
net2 = Module_List()
print("net1:")
for p in net1.parameters():
print(p.size())
print("net2:")
for p in net2.parameters():
print(p)
输出为

五、向模型中输入数据
假设我们向模型中输入的数据为input,从模型中得到的前向传播结果为output,则输入数据的方法为
output = net(input)
net是对象名,我们直接将输入作为参数传入到对象名中,而并没有显示的调用forward()函数,就完成了前向传播的计算。上面的写法其实等价于
output = net.forward(input)
这是因为在torch.nn.Module类中,定义了__call__()函数,其中就包括了对forward()方法的调用。在python语法中__call__()方法使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用,并执行__call__()函数体中的内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









