






前期准备
- 乌云资源文件下载地址:https://github.com/m0l1ce/wooyunallbugs
- phpstudy下载(php环境要求5.3):https://www.xp.cn/wenda/389.html
环境搭建
下载好的乌云文件:

- 将bugs.rar解压到phpStudy/www目录下,然后进入文件,找到conn.php文件,修改数据库的用户名和密码。
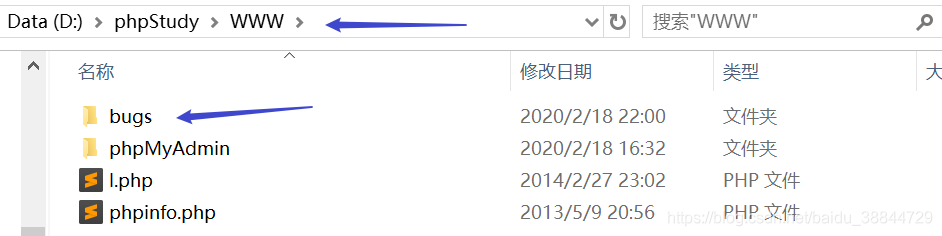

- 在bugs目录中新建文件夹upload,并将下载好的4个zip文件解压到此文件中,作用就是显示图片的。

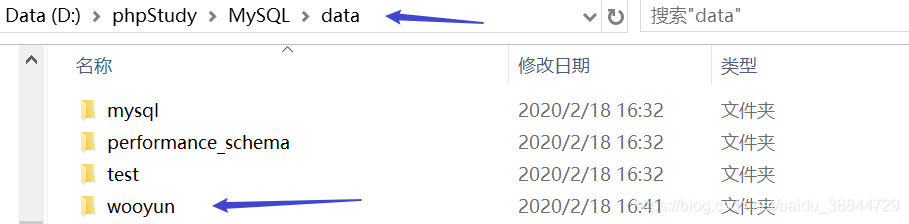
- 将wooyun.rar解压到phpStudy/MySQL/data目录下
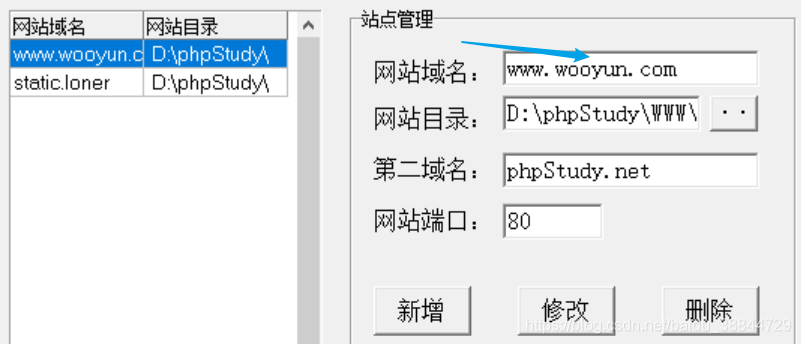
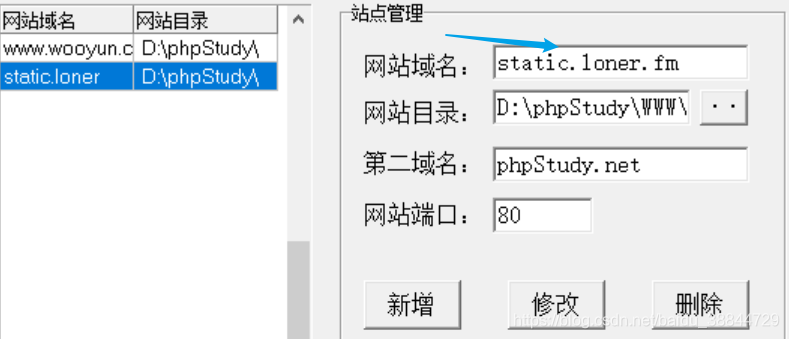
- 启动phpStudy后,一定要切换到5.3版本,点击MYSQL管理器——>站点域名管理,新增两个配置,网站目录都设为:D:\phpStudy\WWW\bugs,即bugs文件所在的目录,第一个域名设为www.wooyun.com,第二个设为static.loner.fm。
- 修改host文件,在最后一行新增
127.0.0.1 www.wooyun.com
localhost static.loner.fm
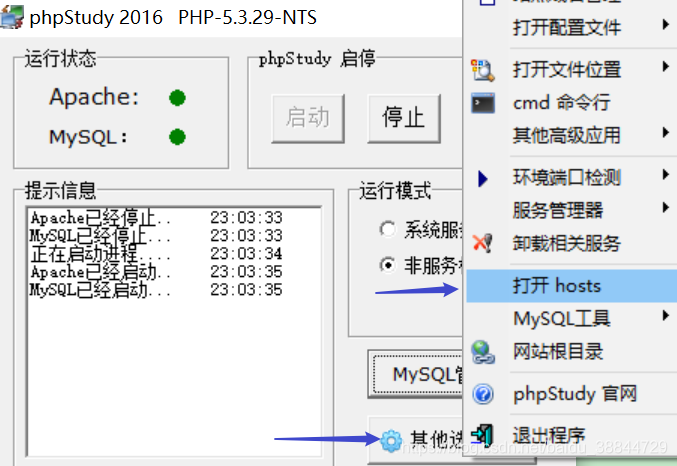
6. 关闭错误提示
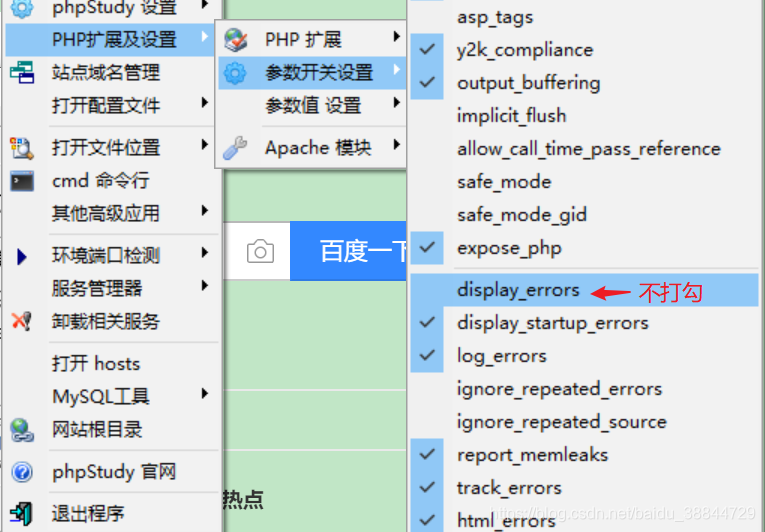
8. 最后在浏览器输入www.wooyun.com,可以成功访问
乌云知识库
通过上面在本地的搭建,可以访问到乌云漏洞库,但是没有乌云知识库。然而我找到了一个静态版乌云Drops,也是可以查询使用的。

但是在查询相关漏洞的时候,引用的文章还是原来乌云网的链接,直接打开是访问不了的

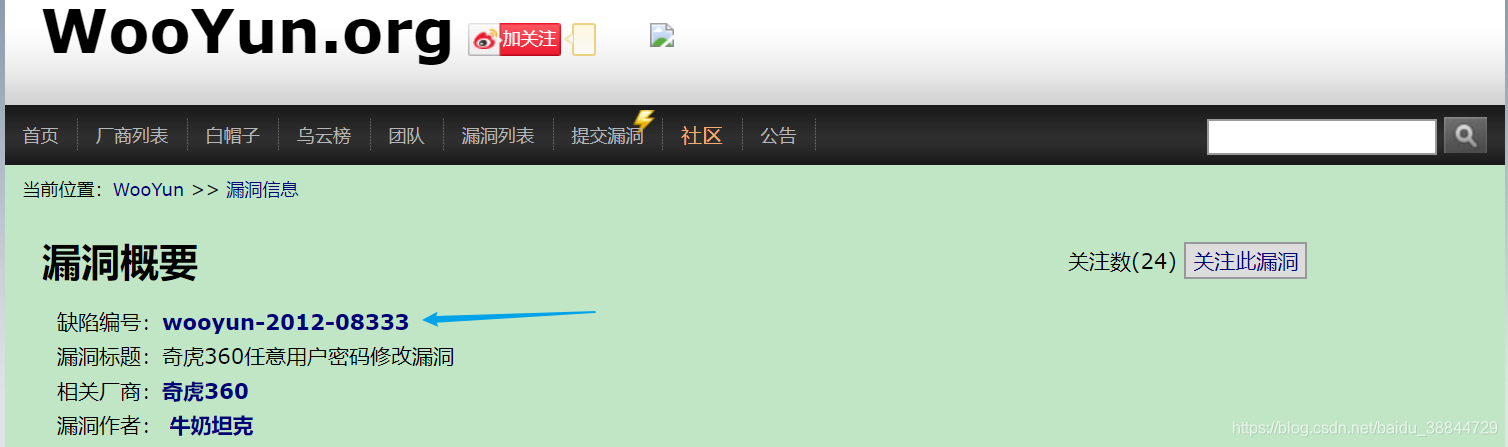
比如原来的url是http://www.wooyun.org/bugs/wooyun-2012-05316,而对应我本地的url是http://www.wooyun.com/bug_detail.php?wybug_id=wooyun-2012-05316,对应编号ID是一致的,只是前面构造不一致。通过查找资料,可以使用油猴脚本进行网页url的跳转。
具体脚本如下:
var mirrorUrlPrefix = 'http://www.wooyun.com/bug_detail.php?wybug_id='; //乌云镜像站地址,即要重定向到的地址
var bugsReg = /http:\/\/www\.wooyun\.org(\/bugs\/)(wooyun-\d+-\d+)/; //乌云漏洞页面URL匹配规则
var dropsReg = /http:\/\/drops\.wooyun\.org\/(.+)\/(\d+)/; //乌云知识库页面URL匹配规则
window.onload=function()
{
var allLinks = document.getElementsByTagName('a'); //获取a标签中的链接
for (var i = 0; i < allLinks.length; i++) {
var a = allLinks[i];
var oldUrl = a.href;
var arr, newUrl;
//漏洞页面规则:http://www.wooyun.org/bugs/wooyun-2012-011833 --> http://www.wooyun.com/bug_detail.php?wybug_id=wooyun-2012-08333
if (bugsReg.test(oldUrl)) {
arr = bugsReg.exec(oldUrl);
newUrl = mirrorUrlPrefix +arr[2];
a.href = newUrl;}
}
}
使用该油猴脚本,当你打开某查询页面时候需要再刷新一次才能生效,因为需要获取到a标签的链接,才能对其进行匹配修改,之后就可以跳转到本地的页面了
参考文章
https://www.anquanke.com/post/id/86050
http://bobao.360.cn/learning/detail/3035.html














 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









