







1.利用正则表达式(高亮匹配显示),输入的内容跟已有的字符串中相同的部分高亮显示;
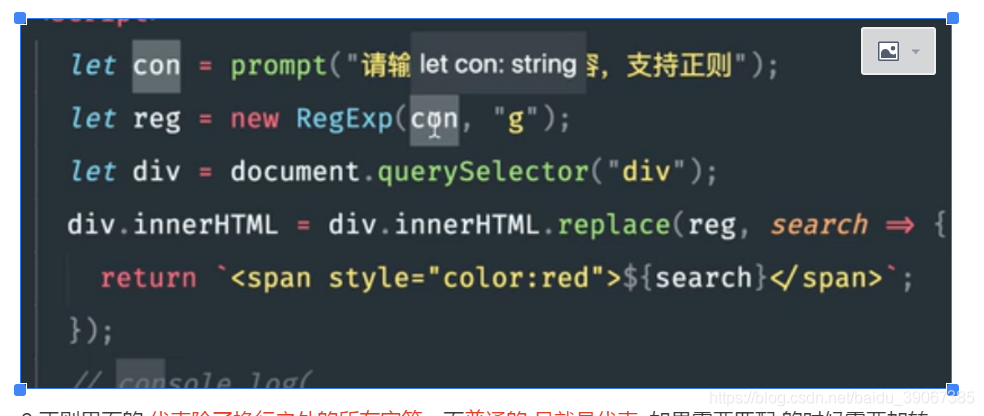
2.正则里面的.代表除了换行之外的所有字符,而普通的.号就是代表.,如果需要匹配.的时候需要加转义;
正则对象里面的特殊字符转义需要加\\,而在字面量中则值需要一个\
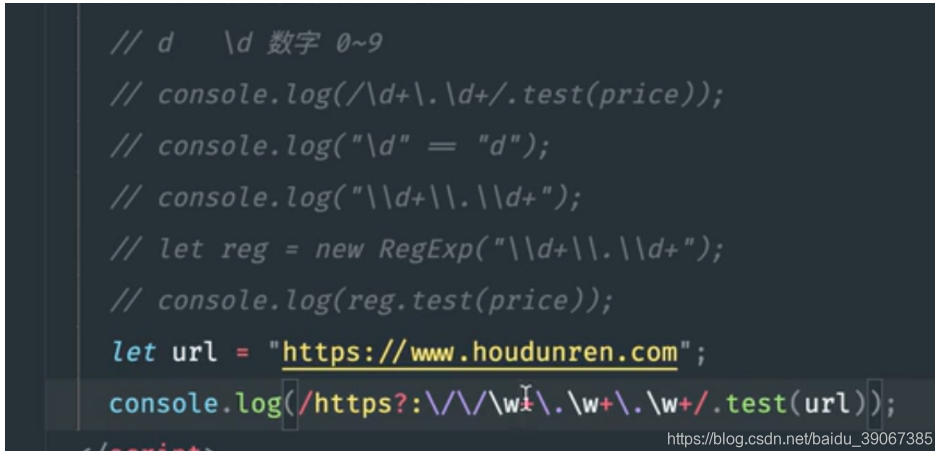
3.字符含义
/d 表示数值 /D 非数值
/s 代表空白,/n 和空格都是空白 ; /S 代表非空白
/w 代表字母,数字,下划线 /W 非字母,数字,下划线
[]中括号里面包含的字符,表示只要匹配上中括号中的任意一个规则就是满足的——原子表
原子表中的规则默认匹配一个字符,需要加上+才变成贪婪模式,比如/[\d]+/g
[0-9] 代表匹配0-9 只能升序写法不能降序[9-0],这样是会报错的
1.^ 这个符号一般表示以……开头,但如果用在原子表中则表示排除,[^0-9]表示除了0-9之外到的字符
2. ()括号放在正则中是原子组的意思,如果想要匹配括号,可以把括号放在原子表中[()]这样就可以匹配括号了
3.点号在原子表中代表的只是点号,而不是除了换行之外的所有字符
4.可以使用?<内容>给原子组取别名

匹配汉字:/\p{sc=Han}/gu
sc=Han 代表汉字,可以通过查阅官网不同语言的属性代表,匹配不同的语言字符
模式修改符:
i:表示不区分大小写
g: 表示全局匹配
m:表示多行匹配
u:表示可以识别宽字节,避免乱码
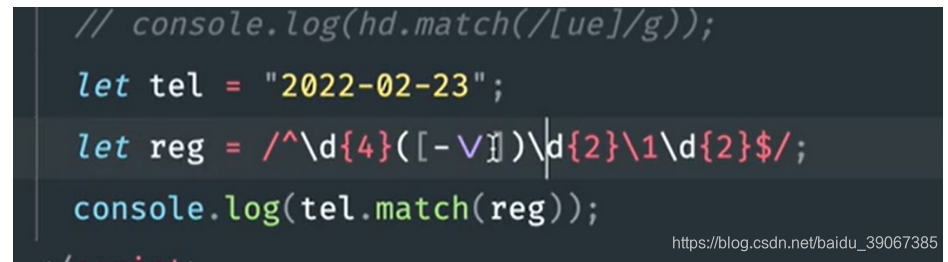
4.如果要匹配任意 yyyy-mm-dd 或者 yyyy/mm/dd,但前后的/和-要统一,比如不能是yyyy-mm/dd
使用原子表可以解决这个问题,下图中的\1代表第一个原子组([-\/])
5.?代表0个或1个字符,通常可代表某个字符可有可无
在正则中如果又原子组(),有一个就代表一个变量,但有时候我们想要忽略某个原子组的时候,可以通过加 ?: 才忽略这个原子组使得它不算近变量个数
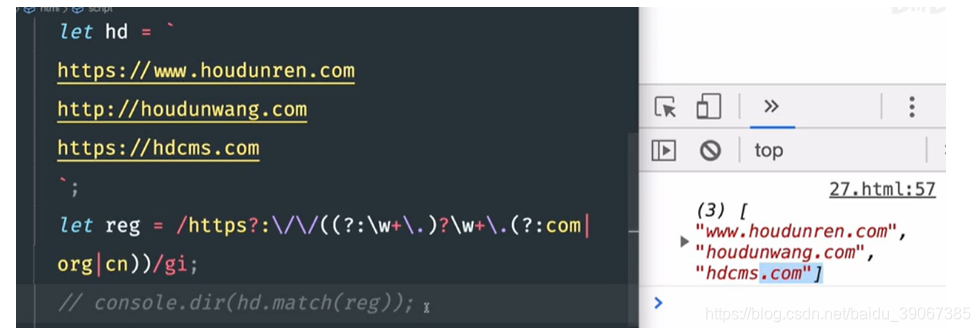
* 代表 0个或多个字符
+ 代表1个或多个字符
{1,} 代表1个到无数个字符
以上这个三种都是对规则的前一个字符生效,并且是贪婪模式,匹配越多越好
禁止贪婪
/\d+?/ 在+号后面加上? 那么就能达到禁止贪婪的效果了,这个表达式将只会匹配到一个数字。同理 只要再以上有贪婪模式的后面加上?都能禁止贪婪。比如:?? /\d*?/ {1.100}? 这个表达式将只会匹配一位
6. 批量使用正则完成密码的校验

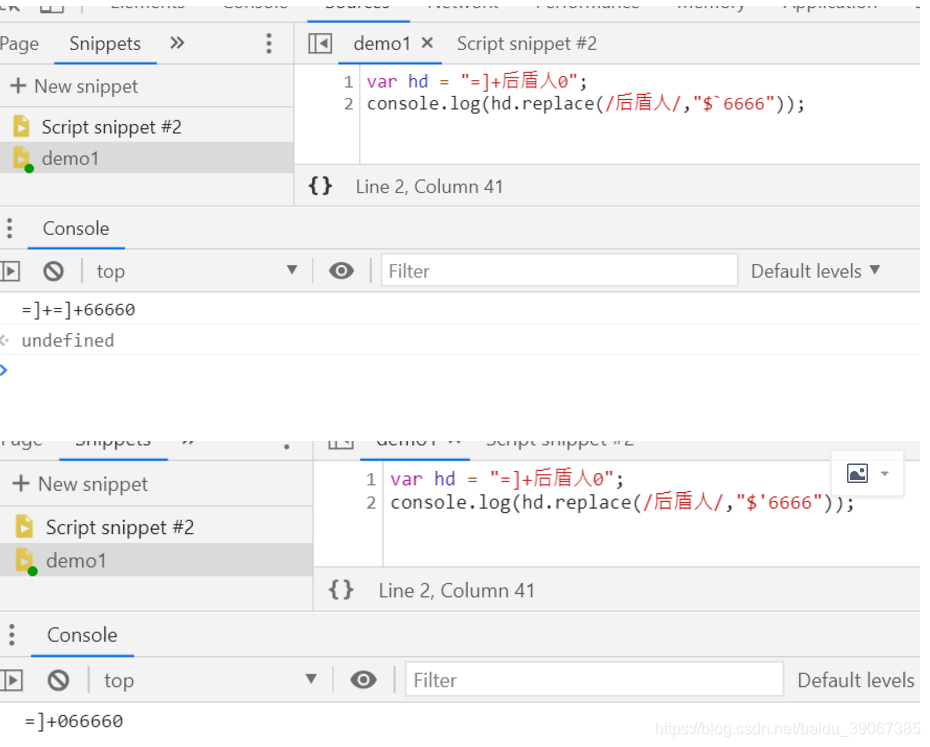
7. replace 知识点
$` 表示匹配内容到的前面(左边)
$' 表示匹配内容的后面()
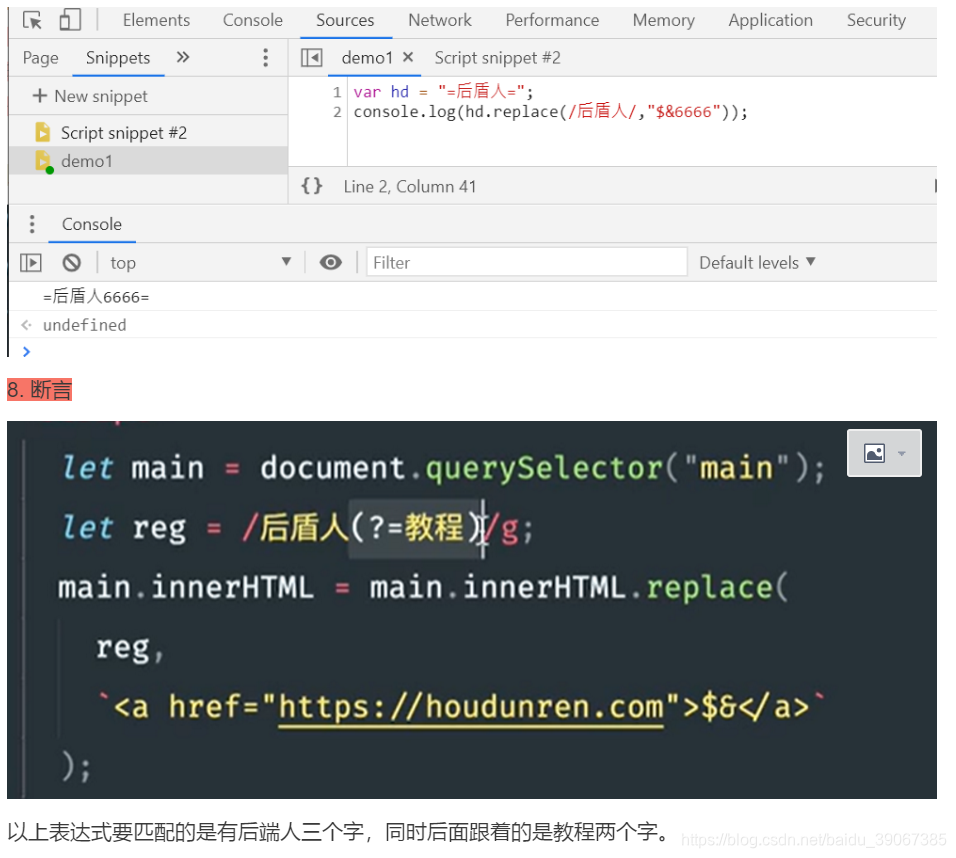
$& 表示所匹配内容

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









