







目录
1.from import 与import 详解
2.python基础数据类型
3.字符串格式化,迭代器,生成器
迭代器生成器-3实例说明
其中yield else: yield temp 在生成器最后返回迭代器时,没循环一次就产生一个迭代器可迭代对象
,最后用产生的迭代器,运行了好多次yield就有好多个可迭代对象,就可以执行好多次next,调用每个迭代对象,并且执行next函数会不仅仅返回yield 后面的值,还会执行yield 前面的语句。
迭代器使用性质补充说明
利用for循环的加载同一迭代器一次,再次循环加载同一迭代器,就会只读出迭代器多个数据中的一个数据。
4.python函数和变量的概念
星号参数补充说明
- 参数 :*=列表 **=字典,test(x,*args)可以这样使用 test(1,2,3,4)x=1,arg=(2,3,4)
- test(1,*(1,2)) arg[0]=1 arg[1]=2 test(1,(1,2)) arg[0]=(1,2)
- test(1,**kwars) test(1,x=1,y=2) kwars={“x”:1,“y”:2}
- 前面加GOLBAL可以调用全局变量,此时对于全局变量的改变是永久的
第三部分补充说明
- 返回值数=0:返回None ;
- 返回值数=1:返回object ;返回值数>1:返回tuple 返回值数=返回参数数量
第七部分补充说明
- 第一个代码框中的输出结果:第3层打印 Alex3 第2层打印 Alex2 最外层打印 Alex
- 第一个代码框中的输出结果:lhf wupeiqi
第九部分补充说明
- lambda x:x+1 等于参数是x返回参数是x+1的函数
- lambda调用方式:fun=lambda x:x+1 fun(10),不过这种调用方式没有实际意义,当一个函数的参数是函数时才有用,参考第十章的内容。
- 第二个代码框运行的结果:31121 k3 100
- 如果在源代码中发现一个函数ctrl点进去发现或者打开quick definenation属于bulilt 去百度一下这个函数的使用方法,应该比较容易找到
参数的两种类型

5.文件处理
6.关键字的使用
with-1
with-2
[@的使用方式(跟修饰器有关)](https://www.cnblogs.com/wuxie1989/p/5710757.html
continue 在循环这中使用,意思是跳过后面的语句,直接开始下一次循环。
7.三元表达式,列表解释,生成器表达式
三元表达式
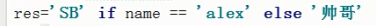
列表解析
第一张图的结果与第二张相同。第三章图等于返回一个迭代器,效果和第一张相同


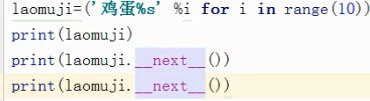
迭代器中send函数的使用

send相当于给迭代器中yield 赋值 send none 就是不赋值,yield 1中的1就变成了none ,至于是哪个yield 后面的值就跟执行的next的次数有关了,此地方有疑问待解决
8.闭包和高阶和装饰器
关于修饰器参数例子


warpper 的参数可以不用设置,直接test(xxx,xxx)就传进去了,因为使用了@timer,test()就变成了timmer(test())
9模块和常用内置模块
补充说明
1.一个py文件是引入过后,会执行里面的所有语句,所以一般里面只有定义
2.sys.path 是当前执行目录如果里面没有这需要使用from import解决,例如sys.path只有路径c//文件1 ,而需要执行的文件的路径是c//文件1//文件2 ,则需要使用from import 文件1.文件2或者使用from文件1 import文件2。
3.调用-name-这个属性时,在哪里调用则显示哪个文件的名字,例如在打印-name-这个操作在1.py中,如果在2.py调用则显示1.py-----打印-name-是2.py的name。
4.sys.path 中的变量可能只在paycharm中有用,换了运行环境可会变化。
re模块补充说明与简要
1------ .^ $ * + ? { } []符号
ret=re.findall(‘a…in’,‘helloalvin’) print(ret)#[‘alvin’]代表任何字符一个点代表一个
ret=re.findall(’^a…n’,‘alvinhelloawwwn’) print(ret)#[‘alvin’]已a开头
ret=re.findall(‘abc*’,‘abcccc’)#贪婪匹配[0,正无穷] print(ret)#[‘abcccc’]
ret=re.findall(‘abc+’,‘abccc’)#[1,正无穷] print(ret)#[‘abccc’]
ret=re.findall(‘abc?’,‘abccc’)#[0,1] print(ret)#[‘abc’]
ret=re.findall(‘a[bc]d’,‘acd’) print(ret)#[‘acd’]
ret=re.findall(‘abc{1,4}’,‘abccc’)print(ret)#[‘abccc’]等于[1,4] 1到4个c都可以可以自己定义
2------- \后面跟的元字符当做普通字符处理,或者使用r把字符中元字符当做普通字符处理

(此点有疑问)
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
双重\python解释器会去掉一个\边城一个\ (\后面跟的元字符当做普通字符处理,\\就相当于一个\普通字符)再交给c语言匹配引擎执行 例如,a\\b 进入引擎后变成a\b 再利用正则式规则对a\b进行处理就得到最终结果
例子:
ret=re.findall(‘c\l’,‘abc\le’) print(ret)#[]
ret=re.findall(‘c\l’,‘abc\le’) print(ret)#[]
ret=re.findall(‘c\\l’,‘abc\le’) print(ret)#[‘c\l’]
ret=re.findall(r’c\l’,‘abc\le’) print(ret)#[‘c\l’]
3— serch ,split ,compile,fiter,match
match 从开头开始匹配不行则退出
serch 提取结果进行分组,利用group提取,分组例子;?p用group(name)提取
serch 例子:
ret=re.search(’(?P\d{2})/(?P\w{3})’,‘23/com’)
print(ret.group())#23/com
print(ret.group(‘id’))#23
split 分割字符串,
例子:
ret=re.split(’[ab]’,‘abcd’) #先按’a’分割得到’‘和’bcd’,在对’‘和’bcd’分别按’b’分割
print(ret)#[’’, ‘’, ‘cd’]
complie方法:生成一个固定正则式的字符串处理器供多个字符串使用:
例子:
obj=re.compile(’\d{3}’)
ret=obj.search(‘abc123eeee’)
print(ret.group())#12
sup:替换
例子:
ret=re.sub(’\d’,‘abc’,‘alvin5yuan6’,1)
print(ret)#alvinabcyuan6
ret=re.subn(’\d’,‘abc’,‘alvin5yuan6’)
print(ret)#(‘alvinabcyuanabc’, 2)
fiter:迭代器 例子:
ret=re.finditer(’\d’,‘ds3sy4784a’)
print(ret) #<callable_iterator object at 0x10195f940>
print(next(ret).group())
print(next(ret).group())
shevel模块,pickle模块,logging模块
shevel模块用于对象反序列化
piclke模块用于序列化
logging模块相当于生成一个后缀名为log的文档文件,本质可以理解成为利用文件系统写入和读取,但是写入和读取的操作都已经封装好
例子:
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET)
import logging
logging.basicConfig(level=logging.DEBUG,
format=’%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s’,
datefmt=’%a, %d %b %Y %H:%M:%S’,
filename=’/tmp/test.log’,
filemode=‘w’)
logging.debug(‘debug message’)
logging.info(‘info message’)
logging.warning(‘warning message’)
logging.error(‘error message’)
logging.critical(‘critical message’)
以上代买中format 规定了记录到log这个文档文件的信息的格式。例如%(message)s就代表logging.info(‘info message’) 中的info message字符串从输出结果中可以看到 ,以下为输出结果
Mon, 05 May 2014 16:29:53 test_logging.py[line:9] DEBUG debug message
Mon, 05 May 2014 16:29:53 test_logging.py[line:10] INFO info message
Mon, 05 May 2014 16:29:53 test_logging.py[line:11] WARNING warning message
Mon, 05 May 2014 16:29:53 test_logging.py[line:12] ERROR error message
Mon, 05 May 2014 16:29:53 test_logging.py[line:13] CRITICAL critical message
logging的handler和filter
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)。
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
限制只有满足过滤规则的日志才会输出。
比如我们定义了filter = logging.Filter(‘a.b.c’),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带 a.b.c前缀的Logger才能输出其日志。
logger.addFilter(filter)这是只对logger这个对象进行筛选如果想对所有的对象进行筛选,则:filter = logging.Filter(‘mylogger’) fh.addFilter(filter) ch.addFilter(filter) 这样,所有添加fh或者ch的logger对象都会进行筛选。
logging的树型结构
logger = logging.getLogger()显示的创建了root Logger,而logger1 = logging.getLogger(‘mylogger’)创建了root Logger的孩子(root.)mylogger,logger2同样。而孩子,孙子,重孙……既会将消息分发给他的handler进行处理也会传递给所有的祖先Logger处
孩子,孙子,重孙……可逐层继承来自祖先的日志级别、Handler、Filter设置,也可以通过Logger.setLevel(lel)、Logger.addHandler(hdlr)、Logger.removeHandler(hdlr) Logger.addFilter(filt)、Logger.removeFilter(filt)。设置自己特别的日志级别、Handler、Filter。若不设置则使用继承来的值
congfigue模块和hashib模块
congfigue模块相当于生成一个后缀名为congfg的文档文件,本质可以理解成为利用文件系统写入和读取,但是写入和读取的操作都已经封装好,default是公用属性,hashilb用于加密,md5加密把不同的字符串弄成等长,不能逆转只能,验证只能通过明文加密后和密文比较,可以自己设立参数来设置对相同明文加密成不同密文。
10.class类
11.异常处理
12.Python格式化字符串f-string 与列表推到式

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









