







因果模型三:因果模型在解决哪些实际问题
通过前两篇因果模型文章,我们对因果模型的发展历程和这个研究领域的常用工具都有了一个初步认识,也通过LiNGAM这样一个具体的算法模型对如何把探究因果问题抽象化为数学问题并求解的过程有了一个较为深入的了解。调研至此,在继续深入下去之前,我认为有必要先回答这样两个问题:第一,因果模型研究这个领域的一个宏观架构是怎样的?明晰这个问题,就像给我们自己一张地图一样,能让自己清楚这个领域中都有哪些方向,我们现在处在哪个位置,接下来该往哪个方向走,以及往这个方向走下去会到达哪里。第二个问题就是因果模型目前都应用在哪些领域,都落地解决了哪些实际问题?本篇文章就简单回答一下这两个问题。
一、因果模型研究架构图
2010年的A Survey of Learning Causality with Data Problems and Methods这篇文章对因果研究领域做了一个比较系统的调研,这里我们借用这篇文章总结的架构来阐明目前因果研究都有哪些方向。
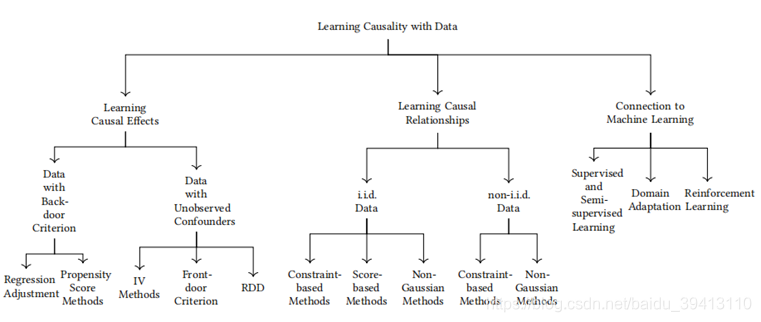
如上图所示,目前因果研究领域主要有两个方向,分别是casual inference和casual discovery。其中Casual Inference主要解决的是定量效果的问题,具体的问题可做如下表述:给定多维样本数据[(x1,d1,y1), …, (xN,dN,yN)],casual inference的目的是量化这样一个问题:当我们把处理变量D的值从d1改变到d2时,输出变量Y将会产生怎样以及多大的变化,即求解E[Y|d2] - E[Y|d1]。而casual discovery主旨是要发现因果关系,具体而言就是:给定N个样本数据X = [x1,x2,…xN],casual discovery研究的是任意两个变量之间是否存在因果关系,即当我们改变第i个变量Xi时,Xj是否会相应发生改变(i不等于j)。显然目前我们关注的是发现因果关系的问题,即casual discovery。在casual discovery中,根据前提假设数据是否服从独立同分布,又分为了两大算法理论体系,而我们上篇讲述的LiNGAM算法就是非独立同分布数据下非高斯算法的一个代表。
二、因果模型的应用实例
1、医学领域
像探究因果这种课题,我们能想到最直接的应用领域就是医学领域,原因也很直观,比如我们需要知道一种疾病的发病机理,从而能达到提前防止的目的,再比如我们需要知道新研制的药物是否真实有效等等,都需要我们建立一种可靠的因果关系,才能弄清这些问题。对照试验是研究因果性的一个传统的,也是最有效的方法,但很多病例研究如果做成对照试验都是违背人伦道德的,此时,基于观测数据的因果研究就成了解决这一问题的有效方案。这里我们详细看下2020年这篇文章,Saxe等人(2020)就通过causal discovery的方法对美国警官的创伤性应激障碍的发病机理做了一个探究。
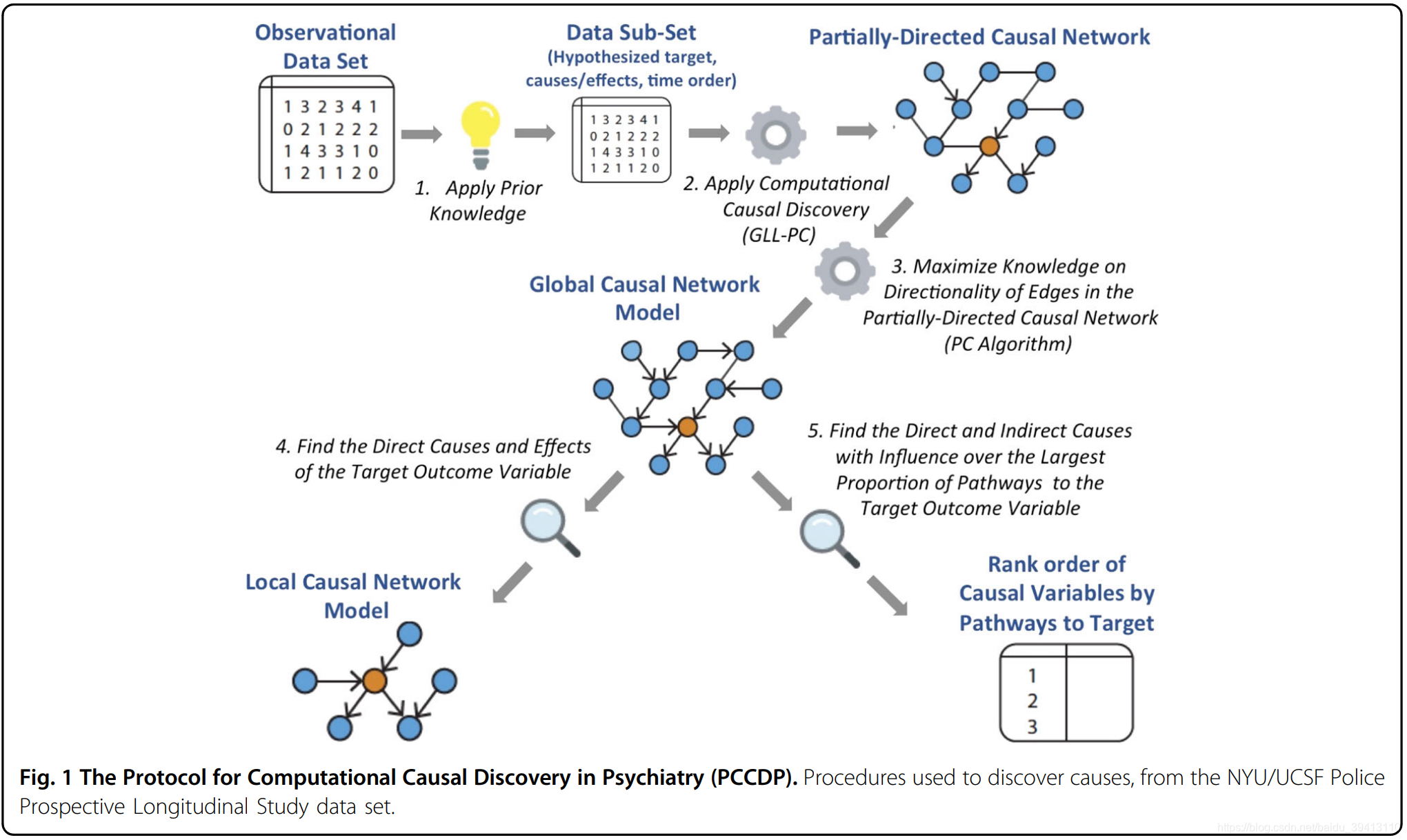
本篇文章所使用的数据来自于207名警官,他们在警察工作的头12个月中,都至少遭受了一次与职务有关的生命威胁事件;这其中157名警官采集了基因数据。如图中所示,整个研究过程分为了如下五个步骤:
一、对观测数据加入先验信息:先验信息包含两方面内容,一是限定变量,即去掉理论上来讲和目标不相干变量;同时在多个同类变量选取最具代表性的一个(比如四个衡量抑郁倾向的指标选一个)。二是指定变量因果顺序,即把所有变量按事件发展过程分成不同的时间阶段,本篇文章对所有变量分了7个阶段,具体如下:
1 体质:进入警察学院时收集的人口和家族史变量,在警察学院培训期间评估的遗传变量。
2 童年:在进入警察学院时收集的涉及童年的变量。
3 入职警局:入职警局时所做的与警察职业相关的症状和功能性特征。
4 警院培训:培训期间记录的心理生理和神经内分泌特征。
5 应激:在警察服务的头12个月中碰到危机性事件。
6 创伤:自我报告对与职责有关的危机性事件的反应,以12个月的后续行动衡量。
7 应激性障碍:包括抑郁和PTS。
二、对数据执行causal discovery算法:通过GLL-PC算法,得到所有变量的全局因果关系图,但部分边的方向尚不明确。
三、进一步确定边的方向:通过PC算法对全局因果关系图中尚不能确定方向的边(比如处于同一时间片段中的变量)进行定向。
四、找到直接导致PTS的子因果图。
五、量化每个变量对PTS的影响:这里采用的方法为,当去掉特定变量节点之后,计算出到达目标节点的路径减少了多少条,来量化特定变量对结果的影响大小。
通过以上五个步骤,最终146个节点和345条边被发现,其中326条边被定向。
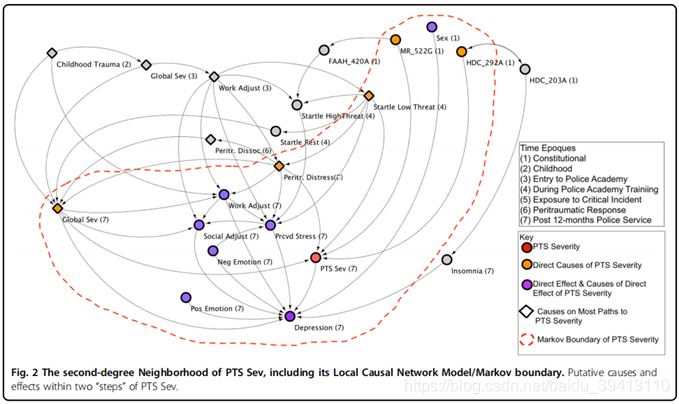
图中呈现出所有和PTS(红色节点)相关的二级节点因果图,橙色节点表示直接原因节点,紫色节点代表了直接或二级直接原因节点。菱形节点表示对PTS影响最大的节点群。其中红色虚线为马尔可夫边界线。马尔可夫边界线框定除了能准确预测出结果节点所需的最少节点,包括所有直接原因节点。
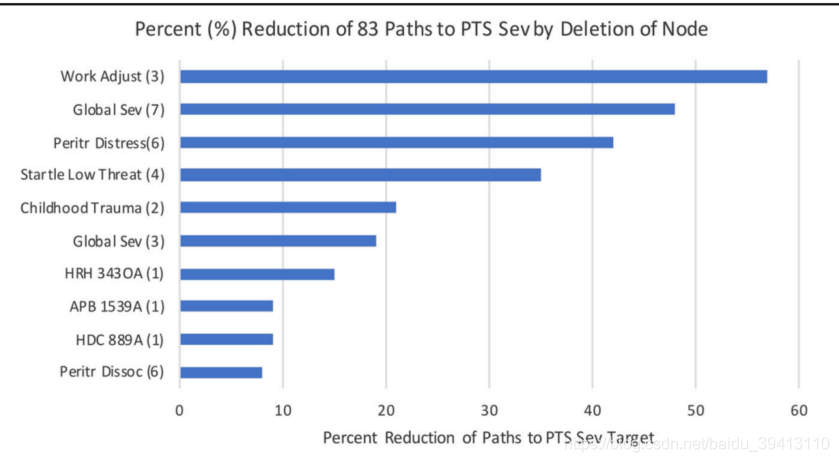
在所有四步之内到达PTS节点的路径中,总共有83条独立的路径。当对每一个节点进行重要性评估(上文中第五步中的方法)后,给出重要性前十的节点如图中所示,其中7个节点在距目标节点二度以内。最终病理学上的结论并不是我们重点关注的对象,只是这样一个因果模型的研究过程非常值得我们借鉴,并迁移到其它领域。
2、商业领域
Towards Robust and Versatile Causal Discovery for Business Applications(2016)这篇文章给出了一个因果图算法在汽车保险领域的应用实例,具体而言,这里应用因果模型的主要目的是识别产生保险费用的原因,以降低保险公司的保费支出。比如识别出车辆是否安装安全气囊是造成医疗保险费用的直接原因,则可以适当提高那些不安装保险气囊客户的保费,或者通过优惠促使客户安装气囊,从而降低医疗保费支出。
这里使用的具体数据包括客户及其车辆的各种性质数据,比如客户年龄、车辆品牌型号、车龄、是否安装防抱死系统等等;同时还包括赔付给客户的保险费用,比如医疗费用、责任费用和财产费用。
这篇文章使用的具体算法为ETIO算法,整篇文章的思路也是通过汽车保险这个具体实例来证明ETIO算法的可靠性。虽然不像上个实例一样,着眼于解决具体问题,但其验证算法的整个过程也是具有启发性的,具体来看一下:
第一阶段:直接执行ETIO算法
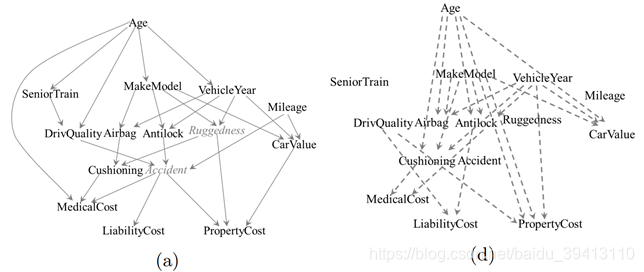
在一开始,该篇文章就给出了一个基于常识、实验、理论得到的因果关系图,并以此作为真实参照,上图(a)。当不加任何干预且不给出任何先验信息,直接执行ETIO算法后,得到的因果图如图(b)所示,其中虚线代表间接因果关系。可以看到这样得出的因果图和真实因果关系相去甚远,汽车公里数、接受的高级训练这两个因素都没能和其它变量建立起因果关系,同时年龄和财产保费支出也出现了直接关连。
第二阶段:加入先验信息
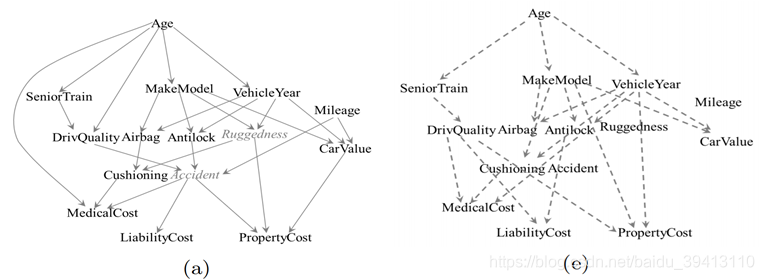
这里加入的先验信息具体包括如下几点:
1、限定年龄是根节点,即不能出现指向它的边。
2、限定医疗、责任、财产保费支出都是叶子节点,因为这是我们要研究的目标,限定这些节点不能再有向外出的边。
3、限定接受的高级训练和保费支出是有因果关系的,不论直接或间接。
上图中展示了加入先验信息之后算法得出的因果图,可以看到先验信息不仅让算法找到了更多变量间的因果关系,也让整个因果过程更加合理。比如,在加入先验信息之前,算法得出年龄是造成财产损失的一个原因,但加入先验信息后,便能看到年龄是通过影响车牌车型、高级训练、车龄因素间接影响财产损失的。
第三阶段:加入实验数据和介入数据
实验数据:假设之前有这样一个实验,研究了防抱死系统如何影响事故率,该实验对不同的防抱死系统都选取等量的样本进行研究,所以相对于真实样本来讲,这些都是有偏数据,这样的数据被称为样例对照数据。
介入数据:假设公司为了减少医疗损失而举办了一个活动,让大家积极安装减震装置,因为并不是所有顾客都会响应这个活动,所以这仅仅是一个软介入。在这个活动之后所收集的数据可以作为介入数据加入到算法中。
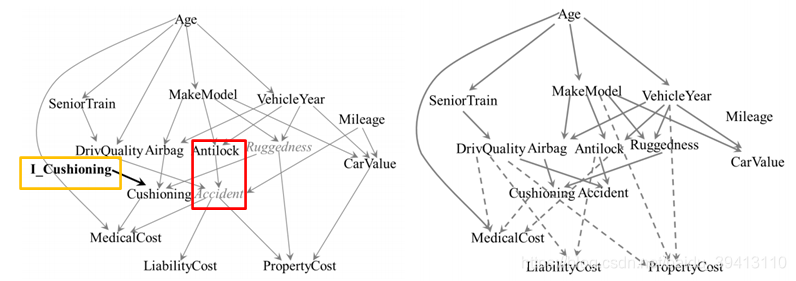
从上图中可以看到,在加入了实验数据和介入数据之后,算法得出的因果关系图的合理性得到了进一步的提升。比如年龄和车牌车型、高级训练、车龄之间得到了确定的直接因果关系,同时年龄和医疗损失之间的直接因果关系也被发现。
以上案例说明了仅仅依靠算法本身,很难得到一个精准的因果关系模型,先验信息、介入数据、实验数据和算法的结合才能让得到的因果关系更加贴合实际。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









