










一、常见的数据结构
数组,栈,队列,链表,散列表,二叉树,堆,跳表,图,树。
1. 数组:
数组的元素在内存中存储是连续存放的,占有连续的存储单元(连续的内存空间);且容量固定(定容);只能存储一种类型的数据;添加、删除操作慢,因为要移动其他元素(提供随机访问,但插入删除操作慢)。
访问的时间复杂度:O(1);
插入/删除的时间复杂度:O(n)。
2. 栈:
后进先出,栈顶入栈,栈顶出栈。栈常应用于实现递归功能方面的场景,如斐波那契数列。
栈常由一维数组或链表表示,分别叫做顺序栈和链式栈。
不同的出栈排列个数:

常用的操作有:入栈push,出栈pop。
访问的时间复杂度:O(n)(最坏);
插入/删除的时间复杂度:O(1)。
应用:浏览器的倒退和前进;检查符号是否成对出现(如果是左括号就直接push到stack中,否则将stack的栈顶元素与该括号做比较,不相等就直接返回false);翻转字符串;维护函数调用等。
3. 队列:
先进先出,在多线程阻塞队列管理中非常适用。
队列用数组或链表实现,分别叫做顺序队列和链式队列。
访问的时间复杂度:O(n)(最坏);
插入/删除的时间复杂度:O(1)。
单队列:顺序队列(由数组实现,会出现假溢出现象)和链式队列。
循环队列:解决假溢出和越界问题。循环队列判断队满的常用方法是①设置flag标志位;②使用一个空闲位。
双端队列:元素可以从队头出队和入队,也可以从队尾出队和入队。
优先队列:由堆实现。
***循环队列中元素个数求法:(rear-front+m) % m(取余) ,其中,rear:队列尾指针,front:队列头指针,m:队列容量。
***循环队列中区分队空和队满的方法:
(1)牺牲一个存储单元(入队时少用一个队列单元):
队满条件:(q.rear+1)%maxsize == q.front
队空条件:q.front == q.rear
(2)增设表示元素个数的数据成员:
队满条件:q.size == MaxSize
队空条件:q.front == q.rear
(3)增设tag数据成员:
队满条件:tag == 1
队空条件:tag == 0
4.链表:
物理存储单元上非连续的,非顺序的存储结构;每个元素包含两个节点:数据域和指针域;不需要初始化容量,可以任意加减元素,只需要改变前后2个元素节点的指针域指向地址即可。
***如何判断链表是否有环?
(1)穷举遍历:设一个检测指针k和一个遍历指针q,count记录q走的步数,q每走一步,k就走q之前走过的节点,若发现相同的节点就说明有环。q=NULL时遍历完整个链表。时间复杂度是O(n^2),空间复杂度是O(1)。
(2)标记法:设置一个标记变量,每走一个节点,就判断一次,若visit=true则有环,反之无环。时间复杂度是O(n),空间复杂度是O(n)。
5. 散列表(哈希表):
根据键(key)而直接访问在内存存储位置的数据结构。哈希表建立了关键字和存储地址之间的一种直接映射关系。
- 构造方法:
(1)直接定址法:直接取关键字的某个线性函数为哈希地址。
(2)除留余数法:假定哈希表长度为m,取一个不大于m但最接近于/等于m的质数P,利用公式H(key)=key%P将关键字转化为哈希地址。
(3)数据分析法:设关键字是r进制数,选取数码分布较为均匀的若干位作为哈希地址。
(4)平方取中法:取关键字的平方值的中间几位作为哈希地址。
- 哈希冲突的解决方法:
(1)开放寻址法:线性探查法,平方探查法,双重散列探查法,伪随机探查法。
(2)拉链法(链地址法)
(3)再哈希法

6. 非线性数据结构——图:
图的存储使用:①邻接矩阵:二维矩阵,如A[i][j]=n(权值)或者A[i][j]=0/1,无线图的邻接矩阵是对称矩阵。邻接矩阵比较浪费空间。
②邻接表:如下图所示,在无向图中,邻接表元素的个数=边的条数*2;在有向图中,邻接表元素的个数=边的条数。

7. 非线性数据结构——堆:
堆不一定是完全二叉树,任意一个节点的值都 ≥(或≤)所有子节点的值,堆通常用数组表示。
堆的插入和删除效率高,时间复杂度是O(logn),初始化的时间复杂度是O(n)。
***若根节点的序号为1,那么树中任意节点 i,其左子节点序号为 2i,右子节点为 2i+1。
①自底向上堆化:会产生“气泡”浪费存储空间,用于插入元素,即先将元素放至数组末尾,上浮。
②自顶向下堆化:用于删除堆顶元素,将末尾元素放至堆顶,再向下堆化,下沉。
根的下标一定为0,最后一个元素的下标一定为size-1.
已知一个节点下标为index,那么,他的双亲下标为(index-1)/2,左孩子的下标为2*index+1,右孩子的下标为左孩子下标+1。
8. 非线性数据结构——树:
n个节点,n-1条边。
高度:该节点到叶子节点的最长路径所包含的边数。
深度:根节点到该节点的路径所包含的边数。
层数:节点的深度+1。

二叉树(链式存储或顺序存储):第 i 层至多有 2^(i-1) 个节点,深度为k的二叉树至多共有 2^(k+1)-1 个节点(满二叉树),至少共有 2^k 个节点。
完全二叉树:除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 完全二叉树 。
平衡二叉树:空或者左右子树的高度差绝对值不超过1,且左右子树都是一颗平衡二叉树。平衡二叉树的常用实现方法有 红黑树、AVL 树、替罪羊树、加权平衡树、伸展树 等。
红黑树:每个节点非红即黑,根节点是黑色节点,叶节点都是黑色的空节点。
二叉树的存储主要分为 链式存储 和 顺序存储 两种:
(1)链式存储:和链表类似,二叉树的链式存储依靠指针将各个节点串联起来,不需要连续的存储空间。
每个节点包括三个属性:
- 数据 data。data 不一定是单一的数据,根据不同情况,可以是多个具有不同类型的数据。
- 左节点指针 left
- 右节点指针 right。
(2) 顺序存储:利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2i 的位置,它的右子节点存储在下标为 2i+1 的位置。如:
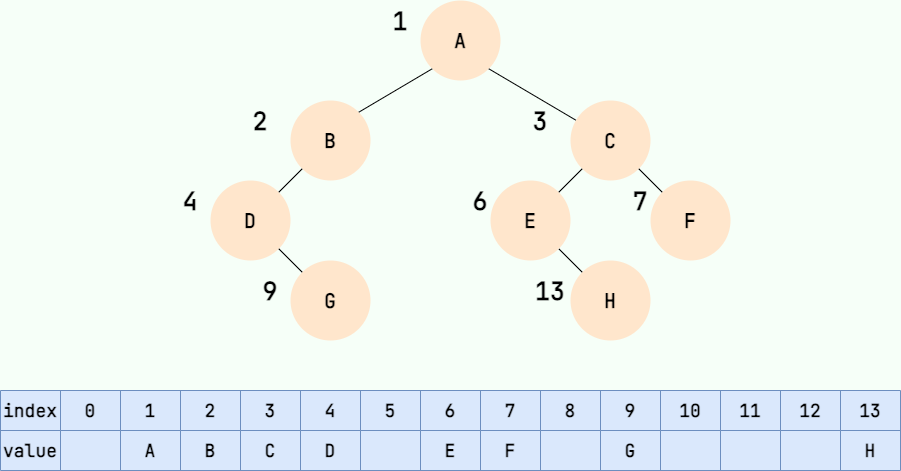
树的存储方式图片来自:树 | JavaGuide(Java面试 + 学习指南)
二叉树的遍历:
(1)先序遍历(根左右);(2)中序遍历(左根右);(3)后序遍历(左右根)。
注:由先序序列和后序序列不能重现一颗二叉树。先序、后序、层序序列的两两组合无法唯一确定一棵二叉树。
可以通过①先序+中序;②后序+中序;或者③层序+中序 序列构造一颗二叉树。
二、常用算法
递归,排序,二分查找,搜索,哈希算法,分治算法,动态规划,字符串匹配算法等。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









