






目录
前言
在前面的文章中,实现了数据库中表字段的加解密,mybatis-plus数据库字段信息加解密-CSDN博客,提高了数据的安全性,正当我们松了一口气的时候,这时候产品带来了一个新的需求,说老板需要对这些加密的字段进行模糊查询,一听到这个需求的时候是不是一脸懵逼,对一个加密的字段模糊查询,这是得多久的老血栓才能提出来的要求,不过想想还没有干巴巴的口袋,咬咬牙必须给它实现了。
设计思路
方式一:我们就将当前表信息全部加载到内存中,将加密字段进行解密后,然后在进行模糊匹配。这个针对表中的数据量少的情况下比较好,但是数据量多的话,那么就不适应了。
方式二:新建一张表,将原文信息保存到该表中,加密字段保存在原表中,模糊查询的时候,查询的是新建的表中原文的字段,不过这样就失去了加密字段的意义,不可取。
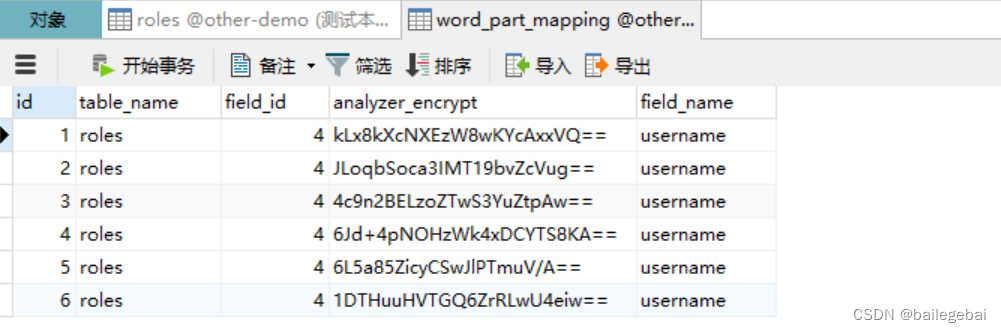
方式三:新建一张分词表,将加密字段的分词加密信息保存到表中,模糊查询的时候查询该表,获取加密字段数据所在的id集合,然后根据id集合去查询原表。
添加依赖
<!--ik分词器-->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
</exclusions>
</dependency>代码
分词工具类
import cn.hutool.core.collection.ListUtil;
import cn.hutool.core.util.StrUtil;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/**
* @Description: 分词工具类
* @Author ly
* @Date 2023/11/222:23
*/
public class AnalyzerUtil {
/**
* ik 字符串用该方法
*
* @param str str
* @param length length
* @return List<String>
*/
public static List<String> ikSegmentationList(String str, Integer length) {
List<String> list = new LinkedList<>();
try {
if (StrUtil.isEmpty(str)) {
return ListUtil.empty();
}
StringReader stringReader = new StringReader(str);
IKSegmenter ik = new IKSegmenter(stringReader, false);
Lexeme le;
while ((le = ik.next()) != null) {
String lexemeText = le.getLexemeText();
if (lexemeText.length() >= length) {
list.add(lexemeText);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
/**
* 部分分词(分割数字类型的字段,如手机号)
*
* @param str str
* @param length length
* @return List<String>
*/
public static List<String> partSegmentationList(String str, Integer length) {
List<String> list = new ArrayList<>();
if (StrUtil.isEmpty(str)) {
return ListUtil.empty();
}
int strLength = str.length();
for (int startIndex = 0; startIndex <= strLength - length; startIndex++) {
String substring = str.substring(startIndex, startIndex + length);
list.add(substring);
}
return list;
}分词实体类
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.lyy.demo3.handler.TypeHandler;
import lombok.Data;
/**
* @Description: 分词实体类
* @Author ly
* @Date 2023/10/1721:48
*/
@Data
@TableName(value = "word_part_mapping",autoResultMap = true)
public class WordPartMapping {
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 表名
*/
private String tableName;
/**
* 分词对应的数据id
*/
private Long fieldId;
/**
* 分词加密字段
*/
@TableField(typeHandler = TypeHandler.class)
private String analyzerEncrypt;
/**
* 字段名
*/
private String fieldName;
}分词扩展配置
在resource目录下添加IKAnalyzer.cfg.xml、ext_dict、ext-stopwords文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IKAnalyzer扩展配置</comment>
<!--用户的扩展字典 -->
<entry key="ext_dict">extend.dic</entry>
<!--用户扩展停止词字典 -->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>Service类
分词service
import cn.hutool.core.collection.CollUtil;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.lyy.demo3.entity.WordPartMapping;
import com.lyy.demo3.mapper.WordPartMappingMapper;
import com.lyy.demo3.service.WordPartMappingService;
import com.lyy.demo3.utils.AesUtil;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
/**
* @Description: TODO(这里用一句话描述这个类的作用)
* @Author ly
* @Date 2023/11/2 22:35
*/
@Service
public class WordPartMappingServiceImpl extends ServiceImpl<WordPartMappingMapper, WordPartMapping> implements WordPartMappingService {
@Autowired
private WordPartMappingMapper wordPartMappingMapper;
@Override
public boolean saveBatchWords(List<WordPartMapping> wordPartMappings) {
return saveBatch(wordPartMappings);
}
@Override
public List<Long> findFieldId(String searchLike) {
QueryWrapper<WordPartMapping> wrapper = new QueryWrapper<>();
ArrayList<String> list = new ArrayList<>();
wrapper.eq("table_name","roles");
if(StringUtils.isNotBlank(searchLike)){
String encrypt = AesUtil.encrypt(searchLike);
wrapper.eq("field_name","username").eq("analyzer_encrypt",encrypt);
list.add(searchLike);
}
if(1 < list.size()){
wrapper.groupBy("field_id").having("COUNT(field_id) >=" + list.size());
}
List<WordPartMapping> selectList = wordPartMappingMapper.selectList(wrapper);
List<Long> fieldIds = new ArrayList<>();
if(CollUtil.isNotEmpty(selectList)){
fieldIds = selectList.stream().map(
WordPartMapping::getFieldId
).distinct().collect(Collectors.toList());
}
return fieldIds;
}
}角色service
import cn.hutool.core.collection.CollUtil;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.lyy.demo3.entity.Roles;
import com.lyy.demo3.entity.WordPartMapping;
import com.lyy.demo3.mapper.RolesMapper;
import com.lyy.demo3.service.RolesService;
import com.lyy.demo3.service.WordPartMappingService;
import com.lyy.demo3.utils.AnalyzerUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* @Description: TODO(这里用一句话描述这个类的作用)
* @Author ly
* @Date 2023/10/1721:54
*/
@Service
public class RolesServiceImpl extends ServiceImpl<RolesMapper, Roles> implements RolesService {
@Autowired
private RolesMapper rolesMapper;
@Autowired
private WordPartMappingService wordPartMappingService;
@Override
public List<Roles> queryLike(String username) {
List<Long> fieldId = wordPartMappingService.findFieldId(username);
return rolesMapper.selectBatchIds(fieldId);
}
@Override
@Transactional(rollbackFor = Exception.class)
public int addRoles(Roles roles) {
int insert = rolesMapper.insert(roles);
// 将模糊查询的数据保存到分词表中
List<String> nameSp = AnalyzerUtil.ikSegmentationList(roles.getUsername(), 2);
ArrayList<WordPartMapping> words = new ArrayList<>();
if(CollUtil.isNotEmpty(nameSp)){
for(String name : nameSp){
WordPartMapping partMapping = new WordPartMapping();
partMapping.setTableName("roles");
partMapping.setFieldId(roles.getId());
partMapping.setFieldName("username");
partMapping.setAnalyzerEncrypt(name);
words.add(partMapping);
}
}
wordPartMappingService.saveBatchWords(words);
return insert;
}目录结构
测试
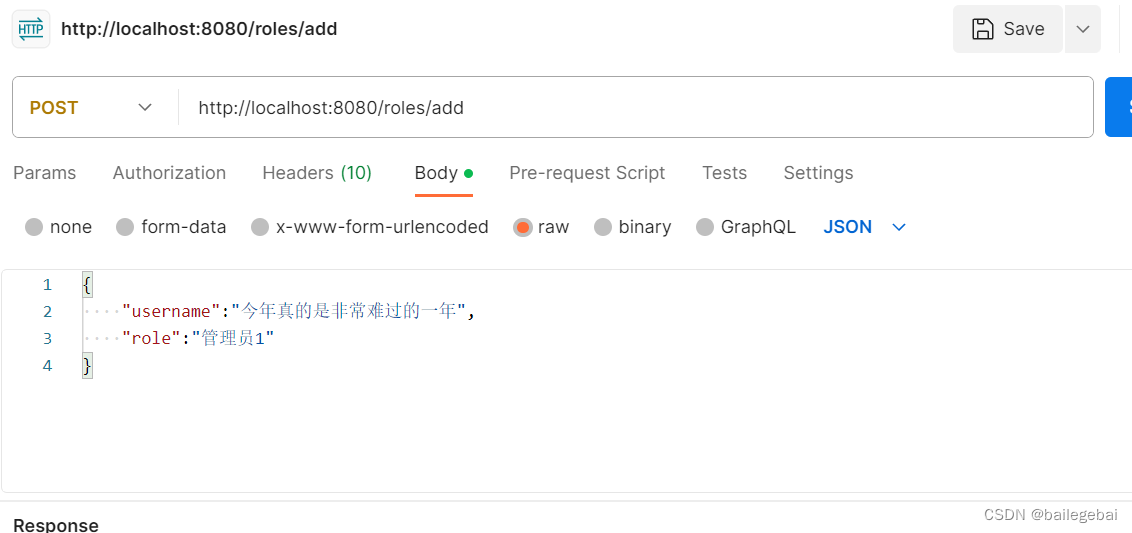
添加

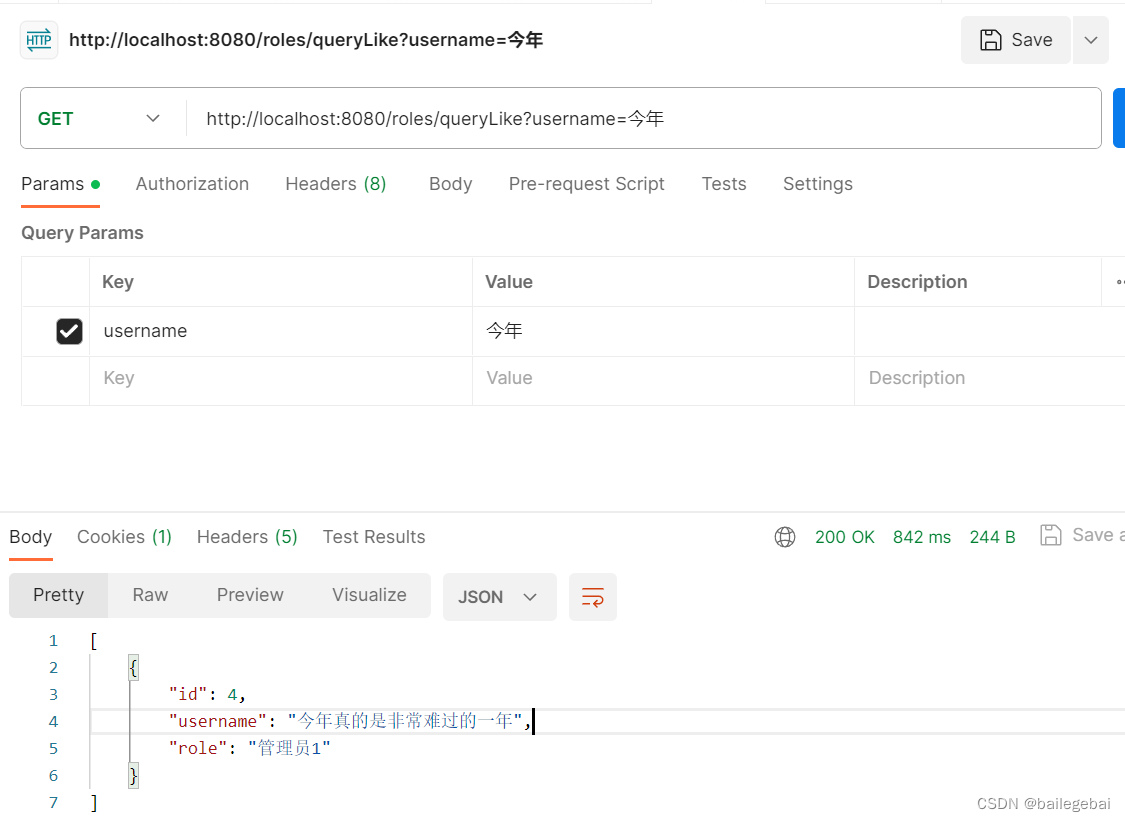
查询
结束语
现在模糊查询加密字段实现了,后面看看怎么实现数据的脱敏展示吧。














 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









