








搭建Solr运行环境
1.从Solr官网下载solr包,在本例中,我下载的是solr-4.10.4.zip
2.安装部署的步骤,参照如下链接:
http://blog.csdn.net/wuzhilon88/article/details/42675573
创建Core
1.在solr home中创建新的core目录
在solr home(solr home是在tomcat/webapps/solr/WEB-INF/web.xml中指定的,由<env-entry>里的<env-entry-value>字段指定。具体如下所示)中新建一个目录,目录的名字要和你新的core名称一样。在本例中,要创建一个叫user的core,所以本例中创建的目录叫user。
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:\solrHome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
2.创建新core的schema.xml、solrconfig.xml、elevate.xml
在新建的user目录中创建conf目录。在conf目录中创建schema.xml、solrconfig.xml和elevate.xml。这三个文件可以从其他已经存在的core中复制。或者从官网下载下来的solr包中的example目录中找到,具体这三个文件在example目录中的位置,因所下载的具体solr版本而异,可以通过搜索搜索找到。在本例中,这些文件可以在solr\example\solr\collection1\conf目录中找到。schema.xml的内容可以参见本文最下面的schema.xml模板中的内容进行修改。schema.xml就是用来指定该core的字段结构的。
注:在本例中,暂不过于关注字段的类型以及各种属性,在以后的阶段再专门研究该部分内容。
在本例中,schema.xml的内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true"
required="true" multiValued="false" />
<field name="name" type="string" indexed="true"
stored="true" multiValued="true"/>
<field name="age" type="int" indexed="true" stored="true"/>
<field name="birthday" type="string" indexed="true" stored="true"/>
<field name="identityID" type="string" indexed="false"
stored="true" multiValued="true"/>
<!-- 保留字段,不能删除,否则报错 -->
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
<!-- 文档的唯一标识,可理解为主键,除非标识为required="false", 否则值不能为空-->
<uniqueKey>id</uniqueKey>
<types>
<!-- 字段类型定义 -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0"
positionIncrementGap="0"/>
</types>
</schema>
3.在Solr的管理页中添加新的core
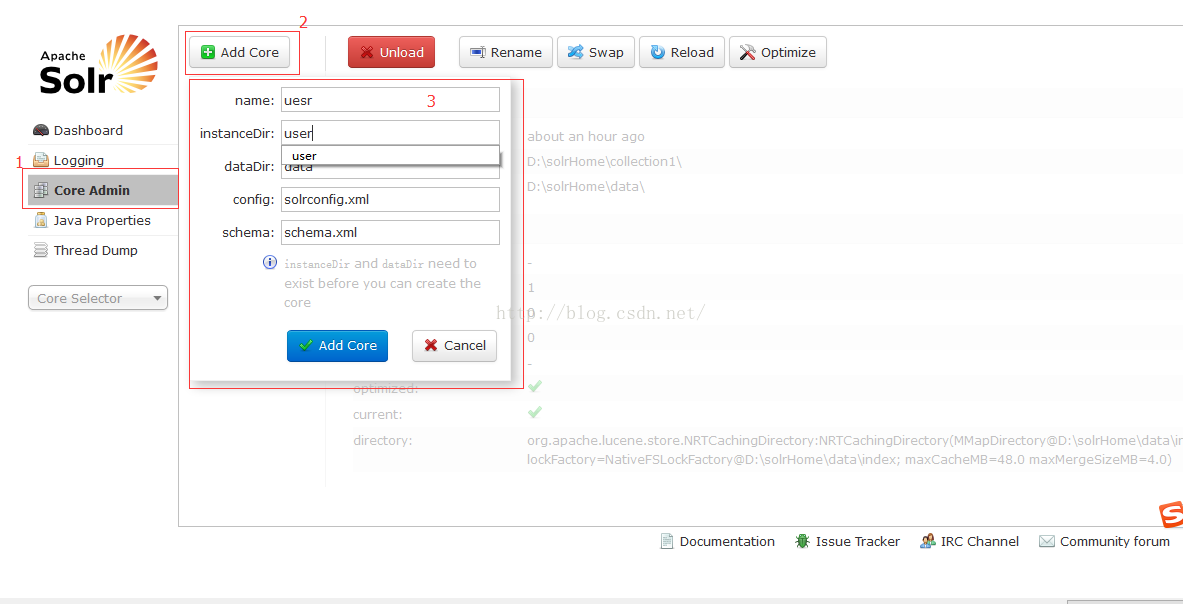
进入solr页面,如下图所示。先后点击1、2,页面会显示3中的表单,在3中如下填写,然后点"Add Core"。之后即可添加成功。如果在之前的步骤中,有什么操作失误导致添加不成功,页面会有红色错误提示显示出来,依照错误提示进行相应处理即可。添加成功后,在左侧的Core Selector下拉框中,即会出现新增的user选项。
4.尝试在新建的core中添加document
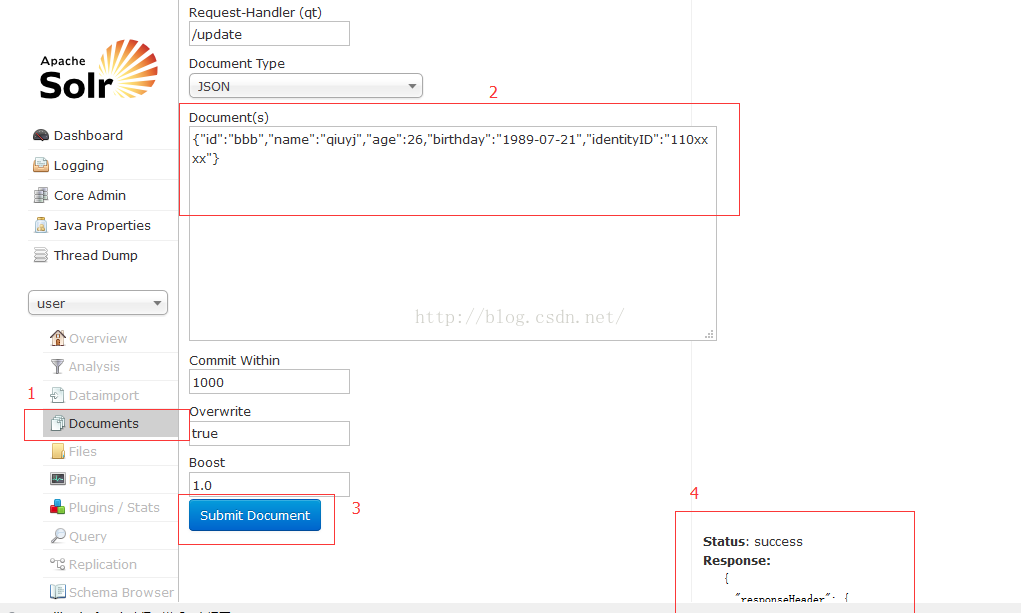
为了验证core添加的是否成功,按如下图所示步骤依次操作:点击1,在2中填写json串,json串的内容依schema.xml中设置的结构填写。然后点击3。无论成功与否,4处都会显示结果。
5.查询刚添加的数据
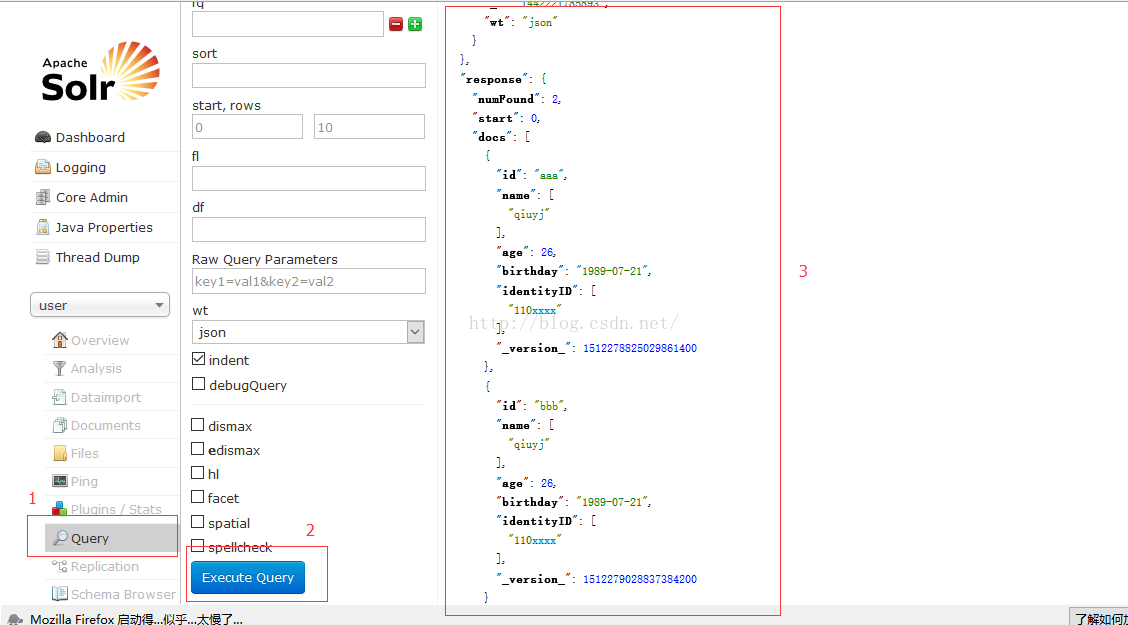
如下图所示。点击1,然后滚轮滚到最下面,点击2。查询的结果会在3中显示出来。
schema.xml模板。转自
http://my.oschina.net/HuifengWang/blog/307471
要注意的是,如果要复制该例,该例中的部分内容需去掉,如泰语、土耳其语那部分,因为没有响应的文件包,若不去掉会报错。
<?xml version="1.0" encoding="UTF-8" ?> 略... <!-- 这是Solr的schema文件,应该命名为schema.xml,并且在solr home的conf目录下 (如,默认在./solr/conf/schema.xml). 有关如何根据需要定制化该文件,请参照: http://wiki.apache.org/solr/SchemaXml 性能须知: 这里包含了很多实际应用不需要的可选项。 为改善性能,你可以: - 尽量将所有仅用于搜索,而不用于实际返回的字段设置stored="false"; - 尽量将所有仅用于返回,而不用于搜索的字段设置indexed="false"; - 去掉所有不需要的copyField 语句; - 为了达到最佳的索引大小和搜索性能,对所有的文本字段设置indexed="false", 使用copyField将他们拷贝到“整合字段”name="text"的字段中,使用整合字段进行搜索; - 使用server模式来运行JVM,同时将log级别调高, 避免输出所有请求的日志。 --> <schema name="example" version="1.5"> 略... <fields> <!-- fields各个属性说明: name: 必须属性 - 字段名 type: 必须属性 - <types>中定义的字段类型 indexed: 如果字段需要被索引(用于搜索或排序),属性值设置为true stored: 如果字段内容需要被返回,值设置为true docValues: 如果这个字段应该有文档值(doc values),设置为true。文档值在门 面搜索,分组,排序和函数查询中会非常有用。虽然不是必须的,而且会导致生成 索引变大变慢,但这样设置会使索引加载更快,更加NRT友好,更高的内存使用效率。 然而也有一些使用限制:目前仅支持StrField, UUIDField和所有 Trie*Fields, 并且依赖字段类型, 可能要求字段为单值(single-valued)的,必须的或者有默认值。 multiValued: 如果这个字段在每个文档中可能包含多个值,设置为true termVectors: [false] 设置为true后,会保存所给字段的相关向量(vector) 当使用MoreLikeThis时, 用于相似度判断的字段需要设置为stored来达到最佳性能. termPositions: 保存和向量相关的位置信息,会增加存储开销 termOffsets: 保存 offset 和向量相关的信息,会增加存储开销 required: 字段必须有值,否则会抛异常 default: 在增加文档时,可以根据需要为字段设置一个默认值,防止为空 --> <!-- 字段名由字母数字下划线组成,且不能以数字开头。两端为下划线的字段为保留字段, 如(_version_)。 --> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/> <field name="description" type="text_general" indexed="true" stored="true"/> <field name="author" type="text_general" indexed="true" stored="true"/> <field name="keywords" type="text_general" indexed="true" stored="true"/> <field name="category" type="text_general" indexed="true" stored="true"/> <field name="url" type="text_general" indexed="true" stored="true"/> <field name="last_modified" type="date" indexed="true" stored="true"/> <!-- 注意: 为了节省空间,这个字段默认不被索引, 因使用copyField被拷贝到了名为text的字段中 。用于内容返回和高亮。搜索时使用text字段 --> <field name="content" type="text_general" indexed="false" stored="true" multiValued="true"/> <!-- 整合字段(catchall field), 包含其他可搜索的字段 (通过copyField实现) --> <field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/> <!-- 保留字段,不能删除,否则报错 --> <field name="_version_" type="long" indexed="true" stored="true"/> </fields> <!-- 文档的唯一标识,可理解为主键,除非标识为required="false", 否则值不能为空--> <uniqueKey>id</uniqueKey> <!-- 拷贝需要索引的字段到整合字段中 --> <copyField source="title" dest="text"/> <copyField source="author" dest="text"/> <copyField source="description" dest="text"/> <copyField source="keywords" dest="text"/> <copyField source="content" dest="text"/> <copyField source="url" dest="text"/> <types> <!-- 字段类型定义 --> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/> <fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/> 略... <!-- Thai,泰语类型字段 --> <fieldType name="text_th" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.ThaiWordFilterFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_th.txt" /> </analyzer> </fieldType> <!-- Turkish,土耳其语类型字段 --> <fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.TurkishLowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="false" words="lang/stopwords_tr.txt" /> <filter class="solr.SnowballPorterFilterFactory" language="Turkish"/> </analyzer> </fieldType> <!-- Chinese,需要我们自己配置,整合mmseg4j就配置在这里 --> </types> <!-- 文档相似度判断依赖于文档相似度得分。 一个自定义的 Similarity 或 SimilarityFactory 可以在这里指定, 但是默认的设置已经适合大多数应用。可以参考: http://wiki.apache.org/solr/SchemaXml#Similarity --> <!-- <similarity class="com.example.solr.CustomSimilarityFactory"> <str name="paramkey">param value</str> </similarity> --> </schema>















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









