







最近因为运维需求,要把所有服务的日志都汇总起来。然后开始研究ELK的功能,从开始的一无所知、晕头转向到现在的一知半解,经历了开始的各种官方文档看不懂(有一些名词在初期是真的不懂,对小白不太友好),也试验了一些网友提供的教程,感觉踩了很多坑。所以在此把自己淌出来的路分享一下,希望对后续想接触这个技术的小伙伴们可以更容易上手,尤其是小白就算什么都不懂,但也可以一天内搭起一套基础的服务,直观的了解一下什么是ELK以及ELK可以做什么。
一、部署计划
准备三台服务器,分别为:
192.168.87.134: 部署Logstash,携带日志文件
192.168.87.136: 部署Elasticsearch,elasticsearch head
192.168.87.135: 部署Kibana
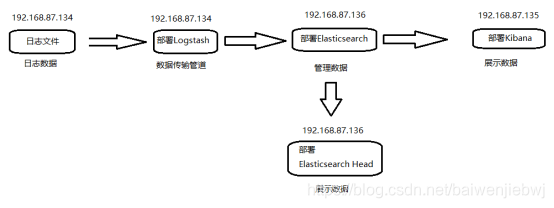
这个也可以都搭在同一台服务器上,但考虑到后期可能需要搭建多节点和集群,还是分开比较好。
==============================================
二、安装前准备(重要!别像我一开始安装elk的时候各种出问题)
1、安装新版的CentOS7,发现ifconfig不可用
①编辑ifcfg-ens33,修改ONBOOT=yes
vi /etc/sysconfig/network-scripts/ifcfg-ens3

②重启网络服务,执行:
service network restart

③查询相关软件包:
yum provides ifconfig

④安装net-tools,安装完成如下图所示:
yum install net-tools
2、linux中wget未找到命令
①在装数据库的时候发现无法使用wget命令,提示未找到命令
②那是因为没有安装wget,输入命令:
yum -y install wget
wget及其依赖将会被安装
③安装完成后就可以使用wget命令啦
3、配置JDK
Elasticsearch 是使用 Java 构建的,并且在每个发行版中都包含来自 JDK 维护者 (GPLv2+CE)的捆绑版本的 OpenJDK。捆绑的 JVM 是推荐的 JVM,位于jdkElasticsearch 主目录的目录中。要使用您自己的 Java 版本,请设置ES_JAVA_HOME环境变量。如果您必须使用与捆绑的 JVM 不同的 Java 版本,我们建议使用受支持 的 Java 的 LTS 版本。如果使用已知错误的 Java 版本,Elasticsearch 将拒绝启动。使用您自己的 JVM 时,捆绑的 JVM 目录可能会被删除。
7.0以后的elasticsearch下载后会自带jkd=>
也可以自己安装jdk(elk支持最好的jkd版本为8和11,建议使用11):
yum -y install java-11-openjdk.x86_64
这种方式安装的jdk是免配置的,但如果是自己下载然后传进来解压,需要自己去配置环境变量
vim /etc/profile
4、关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
5、关闭selinux
将/etc/selinux/config中的SELINUX=enforcing修改为SELINUX=disabled
6、修改文件描述符大小
执行
echo -e "* soft nproc 65535\n* hard nproc 65535\n* soft nofile 65535\n* hard nofile 65535\n" >> /etc/security/limits.conf
7、安装vim
输入 rpm -qa|grep vim 命令, 如果 vim 已经正确安装,会返回下面的三行代码:
[root@localhost]# rpm -qa |grep vim
vim-enhanced-7.4.160-5.el7.x86_64
vim-minimal-7.4.160-5.el7.x86_64
vim-common-7.4.160-5.el7.x86_64
如果少了其中的某一条,比如 vim-enhanced 的,就用命令来安装;
yum -y install vim-enhanced
如果上面的三条都沒有返回, 可以直接用 yum -y install vim* 命令来安装。
yum -y install vim`*
8、安装node
①下载node
wget -c https://mirrors.huaweicloud.com/nodejs/latest-v14.x/node-v14.17.5-linux-x64.tar.gz
②安装
tar -zxvf node-v12.22.5-linux-x64.tar.gz
③配置环境变量
vi /etc/profile
在文件最后面追加node.js环境变量
export NODE_HOME=/usr/local/node-v10.16.3-linux-x64
export PATH=$NODE_HOME/bin:$PATH
④重新加载配置文件并验证是否安装成功
source /etc/profile
node -v
npm -v
9、安装解压缩工具
yum install -y unzip zip
10、修改内存权限太小
使用root身份在/etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
保存退出,切换到root用户执行
sysctl -p
11、创建子用户
useradd elsearch #创建elasticsearch用户
passwd elsearch #设置密码
chown -R elsearch /usr/elk/ #操作授权
su - elsearch #切换身份(需要的时候再切换,一般用root就可以)
12、lsof命令
yum install lsof(安装lsof命令)
lsof -i :9200 查看端口命令
13、关于工具的使用
13.1、本地VMware Workstation Pro
13.2、Linux系统:CentOS-7-x86_64-DVD-2009.iso
13.3、连接Linux命令工具:Xshell7
13.4、连接Linux文件工具:Xftp7
==================================================
三、安装(正题来啦!!!!!!!!!!!!!)
1、准备系统及elk下载网址
1.1、准备系统
安装上面准备好的环境,然后开始克隆系统。
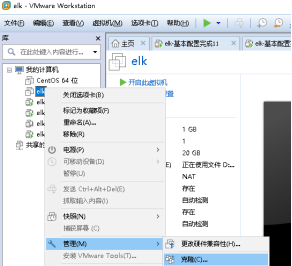
需要几个服务器,就克隆出来几个(此处是克隆了三个)

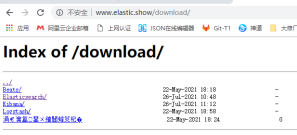
1.2、elk下载
http://www.elastic.show/download/
由于国外的官网可能会网速较慢,所有选择这个国内的网站,速度会比较快,而且有时间也可以顺便看一下里面的其他内容(不在乎网速的可以直接从官网下载)。
也可以用wget命令直接从官网下载到linux系统中
mkdir /usr/local/elk
wget "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz"
wget "https://artifacts.elastic.co/downloads/logstash/logstash-7.8.0.tar.gz"
wget "https://artifacts.elastic.co/downloads/kibana/kibana-7.8.0-linux-x86_64.tar.gz"
(wget+网址,也可以用其他可以提供下载的网址)
2、Elasticsearch
192.168.65.146服务器上执行
2.1、切换子用户
su - elasticsearch #切换身份 * elasticsearch服务必须以非root身份启动,如果不是非root启动会导致以下错误:“Caused by: java.lang.RuntimeException: can not run elasticsearch as root”
2.2、解压及配置
①目录进入到elk里
cd /usr/elk
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz #解压压缩包(在/elk目录下)
vim /elasticsearch-7.8.0/config/elasticsearch.yml #修改配置文件
在末尾添加以下内容:
#集群名称
cluster.name: el-practice
#是否可以成为master节点
node.master: true
#节点名称
node.name: node-1
#网络绑定,这里绑定0.0.0.0,支持外网访问
network.host: 0.0.0.0
network.publish_host: 192.168.87.136 #本机地址
#集群发现
discovery.seed_hosts: ["127.0.0.1:9300"]
#设置对外服务的http端口,默认为9200
http.port: 9200
#设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
#支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
#手动指定可以成为master的所有节点的name或ip,这些配置将会在第一次选举中进行计算
cluster.initial_master_nodes: ["node-1"]
2.3、启动及关闭
./elasticsearch-7.8.0/bin/elasticsearch #启动服务
启动成功后可以在外面直接登录 => Ip:端口号9200
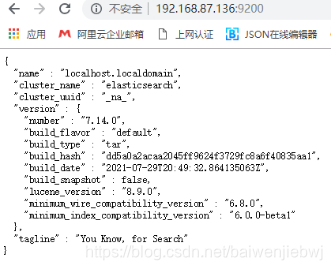
关闭服务(如果不是后台运行,直接ctrl+c即可退出)
ps -ef | grep elastic
Kill -9 id
3、Logstash
192.168.65.144服务器上执行
3.1、准备好日志文件
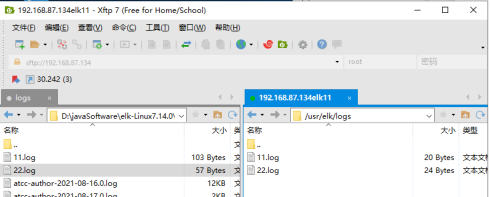
我这里是自己随便准备的几个日志文件,可以自由发挥。
注:但有个坑要注意一下,发生在编辑日志文件的时候,见下图
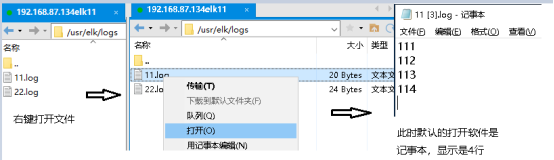
如果想让把这4行都传输过去,需要在第四行回车到第五行,否则只会传输前三行,把第四行丢掉。别问我为什么,这是试过几次后得出来的结论。
3.2、解压及配置
tar -zxvf logstash-7.8.0.tar.gz //解压logstash压缩包
cd /logstash-7.8.0/config //进入到logstash配置文件夹中
vim mynginx.conf //创建配置文件
内容为:
input {
#从文件中读取日志信息 输送到控制台
file {
#指定日志文件
path => "/usr/local/nginx/logs/11.log" #或指定其他日志文件
#这里也可以多文件获取path => "/usr/local/nginx/logs/*.log",这样可以同时获取到以.log结尾的11.log和22.log文件。
#以json格式
codec => "json"
#类型为elasticsearch
type => "elasticsearch"
start_position => "beginning"
}
}
filter {
}
#输出到指定位置
output {
#输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
elasticsearch {
#设置elasticsearch的IP地址和端口号
hosts => ["192.168.65.146:9200"]
#设置索引
index => "es-%{+YYYY.MM.dd}"
}
}
#####具体配置可以在官网查询
3.3、启动及关闭
./bin/logstash -f ./config/mynginx.conf #启动logstash, -f指定配置文件
这时启动logstash服务的终端就会出现:

这是logstash在向elasticsearch传输数据
关闭服务(如果不是后台运行,直接ctrl+c即可退出)
ps -ef | grep elastic
Kill -9 id
3.4、占用硬盘及CPU
①查询占用硬盘空间
通过命令du -h –max-depth=1 *,可以查看当前目录下各文件、文件夹的大小,这个比较实用

②查看cpu情况(输入top命令)
静态情况下:

VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR 共享内存大小,单位kb
由上得出,静态情况下,虚拟内存占用3429248kb(3.27G),物理内存527Mb,共享内存15Mb
工作情况下:跟静态情况下几乎一样
4、Kibana
192.168.65.145服务器上执行
4.1、切换子用户
su - elasticsearch #切换身份 * Kibana服务必须以非root身份启动
4.2、解压及配置
tar -zxvf kibana-7.8.0-linux-x86_64.tar.gz //解压文件夹
vim /kibana-7.8.0-linux-x86_64/config/kibana.yml
修改以下内容:
server.port: 5601 //本机服务端口
server.host: "192.168.65.145" //本机IP
elasticsearch.hosts: ["http://192.168.65.145:9200"] //elasticsearch服务的地址
保存并退出
4.3、启动及关闭
./elk/kibana-7.8.0-linux-x86_64/bin/kibana //启动kibana服务
②启动成功后可以登录 => Ip:端口号
③关闭服务(如果不是后台运行,直接ctrl+c即可退出)
ps -ef | grep elastic
Kill -9 id
4.4、界面使用
点击左上角的三个横杠,然后选择Dev Tools:(这个相当于navicat中的新建查询)
Ctl+i 快速格式化
GET _cat/nodes?v 当前集群有多少个节点(v表示带标题)
GET _cat/indices?v 查看当前集群有多少个索引

5、elasticsearch head(重要!!!!!)
192.168.65.146服务器上执行
我先来解释一下elasticsearch head为什么重要。虽然安装kibana后,可以为日志数据提供了可视化界面,但却不能直观的看出logstash传输过来的数据信息,比如数据量、分片情况、索引情况,只能通过命令一点点查询,不太友好。但head插件却可以很好的提供这个功能,而且如果对数据分析没有太多的要求,head完全可以满足需求,可以舍弃掉kibana。
5.1、下载并安装
使用内置服务器运行
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
5.2、配置elasticsearch,允许head插件远程访问
cd elasticsearch-6.5.1/config/
vi elasticearch.yml
在配置文件末尾添加如下内容,重新启动elasticsearch服务(这部分已经配置过了)
http.cors.enabled: true
http.cors.allow-origin: "*"
5.3、elasticsearch-head服务的启动和关闭
grunt server #启动head
nohup grunt server & #后台启动head
npm run start #启动插件 /elasticsearch-head目录(后台启动)
启动成功后可以在外面直接登录 => Ip:端口号9100
在elasticsearch后面的框里输入elasticsearch的ip和端口号,然后点击连接==>
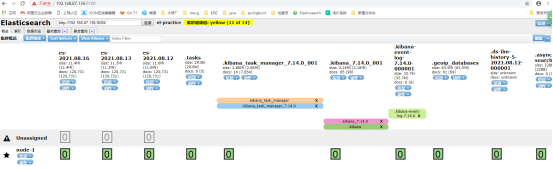
上面出来的那些表格就是logstash输入进来的日志内容,名字是在logstash配置文件中设置的index => “es-%{+YYYY.MM.dd}”。
关闭服务:
lsof -i :9100 #查看head 进程
kill -9 进程id #停止head
=========================================
备注:现在就已经完成了elk的基础部署,关于logstash的多节点和elasticsearch的集群搭建正在研究中,有结果了可以在后面逐步分享出来。
如果有问题欢迎在评论里留言,看到后我会及时回复帮助的。
如果文档中有什么问题,欢迎大佬指正!!!
















 1800
1800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











