







目的:
本文档的目的是为了教以前没接触过azkaban的小伙伴,如何配置调度任务。例如如何创建工程,工程里的调度任务依赖如何配置,一些系统参数如何定义等。
本文档不会讲解azkaban的安装配置,以及架构原理。它完全是一片应用使用类的说明文档。
Azkaban简介:
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。简而言之就是一个工作流调度系统。
那么我们为什么需要工作流调度系统?因为一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序、hive脚本等而各任务单元之间存在时间先后及前后依赖关系为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
Azkaban使用说明:
1、菜单介绍

- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
- flow trigger schedule:
- Document:官方帮助文档,需要能连外网
2、Azkaban使用介绍
2.1、创建工程:
创建之前我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。点击右上角的create project,在弹出的窗口中填写工程名和描述即可创建工程。

由于azkaban是国外Linkedin发布实现的开源调度平台,所以暂时不支持中文,创建项目的时候不能包含中文。但是在azkaban最新版本在Description上是可以输入中文的。如下:

2.2、Command 类型多 job 工作流 flow
配置如下图结构的工作流,需要我们建立5个Job,他们分别是:
工作流
test1.job
test2.job
test3_1.job
test3_2.job
test4.job
以上job的内容分别是:
test1.job
type=command
command=echo 'job1 out ********************'
command.1=echo "job1.1 out ********************"
retries=3
retry.backoff=3000test2.job
type=command
command=echo 'job2 out ********************'
command.1=echo "job2.1 out ********************"
dependencies=test1
retries=3
retry.backoff=3000test3_1.job
type=command
command=echo 'job3_1 out ********************'
command.1=echo "job3_1.1 out ********************"
dependencies=test2
retries=3
retry.backoff=3000test3_2.job
type=command
command=echo 'job3_2 out ********************'
command.1=echo "job3_2.1 out ********************"
dependencies=test2
retries=3
retry.backoff=3000test4.job
type=command
command=echo 'job4 out ********************'
command.1=echo "job4.1 out ********************"
dependencies=test3_1,test3_2
retries=3
retry.backoff=3000
2.3、Job配置中的参数
- common参数配置
type:定义任务类型。
command:具体执行的命令。
decpendencies:用逗号分隔的job名称的列表。依赖总是会先执行,并且一个job只有当它的依赖job完全执行成功它才会运行。
除了type,command,decpendencies三个参数外,还有如下一些保留参数可以为每个job配置
| 参数 | 说明 |
| retries | 失败的job的自动重试的次数 |
| retry.backoff | 重试的间隔(毫秒) |
| working.dir | 指定命令被调用的目录。默认的working目录是executions/${execution_ID}目录 |
| env.property | 指定在命令执行前需设置的环境变量。Property定义环境变量的名称, 因此 env.VAR_NAME=VALUE就创建了一个$VAR_NAME环境变量 并且指定了它的VALUE |
| failure.emails | job失败时发送的邮箱,用逗号隔开 |
| success.emails | job成功时发送的邮箱,用逗号隔开 |
| notify.emails | job成功或失败都发送的邮箱,用逗号隔开 |
一个flow的email属性,只会取最后一个job的配置,其他的job的email配置将会被忽略。
用户也可以自用一下参数,用于接收外部或者上游job的参数,也可用于传递给shell脚本等。
- Runtime 属性
这些属性在job运行期间自动被添加.
| 参数 | 说明 |
| azkaban.job.attempt | job重试次数,从0开始增加 |
| 运行的job name | |
| azkaban.flow.flowid | 运行的job的flow name |
| azkaban.flow.execid | flow的执行id |
| azkaban.flow.projectid | 工程id |
| azkaban.flow.projectversion | project上传的版本 |
| azkaban.flow.uuid | flow uuid |
| azkaban.flow.start.timestamp | flow start的时间戳 |
| azkaban.flow.start.year | flow start的年份 |
| azkaban.flow.start.month | flow start 的月份 |
| azkaban.flow.start.day | flow start 的天 |
| azkaban.flow.start.hour | flow start的小时 |
| azkaban.flow.start.minute | start 分钟 |
| azkaban.flow.start.second | start 秒 |
| azkaban.flow.start.millseconds | start的毫秒 |
| azkaban.flow.start.timezone | start 的时区 |
如何配置job和job之间的依赖,还有azkaban在job里的系统参数和运行时参数。举个简单的例子介绍完了。
2.4、shell类型的job的参数传递举例
azkaban中的shell 作业,如何接收从webUI传递的参数?我们创建一个工程,里面只有一个job叫做myjob.job,创建代码如下:
myjob.job
type=command
job_param=${ui_param}
command=echo "###### ${job_param} ######"
#command=sh test_azkaban_job.sh "${job_param}"在azkaban上创建测试工程,上传zip包。 之后操作如下图:
1、进入project,会出现如下图UI,点击Execute Flow

2、进入执行页面,点击Flow Paramters 选项,再点击Add Row添加参数。

3、添加ui_param参数,该参数是myjob.job里面定义的参数,完了点击Execute执行程序。如果该参数有默认值,在UI上传的值会覆盖脚本里的默认值。

4、下图是任务执行后的日志,可以看出我们传入的参数已经在日志上打印出来了。

重点来了,那么我们想要在任务流之间有参数传递我们要怎么做呢?
首先看官方的介绍说明,官方是这么说的:

具体是什么含义呢! 说白话就是:
- Parameter Passing:参数传递
azkaban以job执行过程中,传递进来的临时参数,运行时参数,项目中配置文件的参数,job定义中参数等 都保存在 ${JOB_PROP_FILE}文件中,保存格式为key=value。执行job的中shell命令时,可以作为参数传递。JOB_PROP_FILE 是一个环境变量参数。
- Parameter Output:参数输出
一个任务运行结束,可以将一些参数写入到${JOB_OUTPUT_PROP_FILE}文件 中,azkaban会将这些参数传递到下游依赖的的job的参数文件${JOB_PROP_FILE}文件中,供下游job引用。如写到${JOB_OUTPUT_PROP_FILE}文件中参数需要是json格式的,否则会报json解析错。JOB_OUTPUT_PROP_FILE也是一个环境变量参数。
那这个功能怎么用呢! 我举一个例子大家就会用了。
首先创建两个Job,param_1.job和param_2.job,创建代码如下:
param_1.job
type=command
command=sh /root/xinlei.bai/test1.shparam_2.job
type=command
command=sh /root/xinlei.bai/test2.sh "${param1}"
dependencies=param_1test1.sh

test2.sh

解释上面任务和脚本的功能:
param_1.job:调用test1.sh
test1.sh:向JOB_OUTPUT_PROP_FILE写一个参数param1=xinlei.bai
param_2.job:调用test2.sh,并在command命令中加入参数。
test2.sh:输出父调度任务,要传递给自调度任务的参数,并打印存放参数的文件JOB_PROP_FILE。 获取到参数有多种方式,我举例的只是其中一种。
我们来看一下两个任务的日志:
第一个任务日志是向JOB_OUTPUT_PROP_FILE文件写要传递的参数。

第二个任务的日志是输出父任务传递过来的参数,并打印出了JOB_PROP_FILE文件里的内容,我们可以看出我们传递的参数在这个临时文件里,也就是说我们获取到里面所有的参数。 可以shell里面通过 cat ${JOB_PROP_FILE} | grep XXX 来获取。


2.5、azkaban核心功能菜单介绍
1、Execute Flow功能模块介绍:

在运行准备页面,右键某个任务,可以设置开启或关闭该任务的相关任务。从上往下依次是:父节点,祖节点(该节点之上的所有节点),子节点,孙节点(该节点之后的所有节点),所有节点。利用该功能可以设置指定任务运行。如下图:

白话解释就是,你可以禁用某些job,禁用后该job将显示为透明的,并在整个flow执行过程中被忽略,选项Parents代表禁用job及其依赖的上一个job,Childern代表禁用job及依赖其的下一个job,Ancestors代表禁用job及其依赖的全部job,Descendents代表禁用job及依赖其的全部job, All代表禁用与此job有依赖关系的全部job。
2、Notification模块:
成功失败后可以发邮件给相关工作人员, 要用邮件功能需要修改一些azkaban的全局配置。

- First Failure:只有Flow中有任一job运行失败就发送邮件通知
- Flow Finished:即使某个job运行失败,也要运行完Flow中的全部job后再进行通知
3、Failure Options(失败选择)
当某个任务运行失败的时候,可以对整个流程的运行进行设置,有以下三种运行设置。

当job运行失败后,你可以进行如下操作:
- Finish Current Running:尝试继续执行其他的正在运行的job,未运行的job将不会尝试开始运行,期间将Flow的状态设置为FAILED FINISHING,Flow运行失败后将状态改为FAILED。
- Cancel All:停止所有Flow中的其他job,宣告此Flow运行失败
- Finish All Possible:尝试继续执行其他的job(包括已经在运行的和还未运行的),期间将Flow的状态设置为FAILED FINISHING,Flow运行失败后将状态改为FAILED。
4、Concurrent(并发执行选项)
当某个流程同一时间内多次执行,可以用该选项设置并发,即当该流程正在运行的时候,下一次运行该流程时的操作。

- Skip Execution:如果Flow已经在运行,不会再调用它
- Run Concurrently:无论Flow是否在运行都会运行,但是选择不同的工作目录
- Pipeline:并发运行多个Flow
- Level 1: 前一个Flow的JobA结束后开始运行当前Flow的JobA
- Level 2: 前一个Flow的JobA及其下游的Job全部完成后,开始运行当前Flow
5、Flow Paramters(参数)
在此处配置参数,覆盖Flow的全局属性。

2.6、azakban任务调度:
如下图所示,我们可以看到一个调度的配置,该调度配置类似于crontab配置,我们在Min,hours这些文本框配置,他会出现在reset文本框,并且最下面的近10次任务调度的时间会显示到最下面,来校验我们配置的是否正确。

举例:
配置一个一年中只有1,3,5,7,9,12这些月份的每周周日凌晨的00:05分跑的任务,如下图:

点击最下面的schedule按钮会保存调度任务,会在scheduling菜单出现一条记录,如下图:

同一个project和flow只能配置一个任务,后面的配置会覆盖前面的配置。点击Set SLA去配置告警的邮件发送,具体配置选项如下图,这里我就不详细介绍了,看UI就能看懂。再说明一点定时任务可设置SLA选项(类似于售后服务)如果某个流程(或者流程中某个关键任务)运行时间过长或运行失败,则可发送邮件给相关人员,同时可设置是否杀死该任务。

2.7、Azkaban的邮件告警配置
在安装Azkaban的时候,需要配置conf/azkaban.properties文件的以下几个参数:
azkaban邮件功能配置
# mail settings
# mail.sender=邮件发送者
# mail.host=发送邮件服务器 腾讯企业邮箱的host是:smtp.exmail.qq.com 126邮箱的host是:smtp.126.com 163邮箱的host是:smtp.163.com
mail.sender=XXXXXXXX@126.com
mail.host=smtp.126.com
mail.user=XXXXXXXX@126.com
mail.password=XXXXXXX2.8、在多executorServer模式下如何指定exec运行任务
该功能仅对管理员用户生效

因为我在服务器159和160都部署了executor主机,所以根据job执行的工作目录可以看出来useExecutor参数是否有生效

在数据库中配置了两台executor主机

executorId=1的时候对应的是159,159中executor项目部署在source_buit目录下
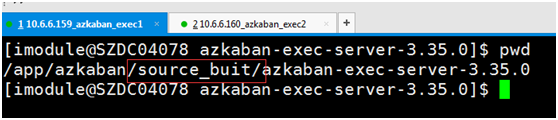
执行日志如下:



同理,配useExecutor=2的情况下,该flow将交给160这台主机处理
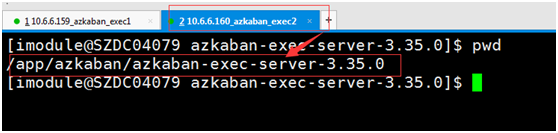















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









