







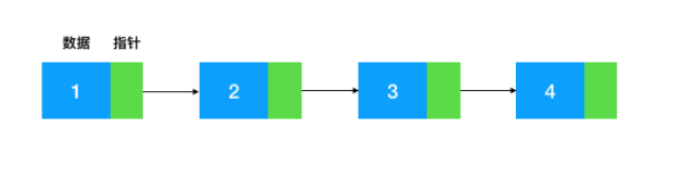
链表是物理存储单元上非连续的,非顺序的存储结构,链表是由一个个结点,通过指针来联系起来的,其中每个结点包含数据和指针:

或者我们采用另一张更加明显的图:
因为在C++语言中,当我们生成一个数组的时候,就要声明数组的长度,如此计算机便会在内存上开辟一个连续的不间断的内存空间来存储数据,因为存在着这样的一种可能,也就是数组所使用的内存空间之后的内存空间已经被使用,所以C++中一旦数组的大小明确了,就不能够再改变了。而且因为数组是存储一系列的同一类型的变量的集合,所以构成数组的每一个元素占用的内存空间的大小是一样的。

而如果我们使用链表,则可以达到如下所示的效果:

构成链表的每一个结点都分配在非连续的位置,结点与结点之间通过指针连在了一起,如此可以随意的对链表进行扩张或者在某一个节点插入一个新的节点,只需要这个节点的内存地址被包含在上一个节点当中,并且该节点包含了指向下一个结点的内存地址。
链表索然在修改上要强于数组,但是在查找上要弱于数组。因为链表中的结点在内存空间上的存储是非连续的,所以如果我们需要知道第n个节点的值,则需要访问第n-1个节点的才能够知道第n个节点的内存地址,进而的知道该内存地址所存储的数据的值。同理,我们也需要访问第n-2个节点,才能够知道第n-1个节点的内存地址;如此往复,如果我们需要知道第n个结点的值,我们还需要从第一个结点开始。间复杂度是O(n),比起数组的 O(1),差距不小。
此外,使用数组有利于程序的局部性原理。CPU在读取到数组中的第一个元素的时候,这个元素地址附近的元素会被提前加载到缓存中,这么做能够提升程序的性能。但是因为链表中的结点的内存地址是随机分布的,所以无法利用到程序局部性原理来提前加在关联的数据从而提升程序的性能。
为了在C++中表示链表,需要有一个表示链表中单个结点的数据类型。从结点的属性来看,这样的一个数据类型不但需要存储的数据结构,还要有一个指向另一个相同类型结点的指针。
这里假设每个结点将存储一个类型为double的数据项,则可以声明以下类型来存放结点:
struct ListNode{
double value;
ListNode *next;
}在以上代码中,ListNode是要存储在链表中的结点的类型,结构成员value是结点的数据部分,而另一个结构成员next则被声明为ListNode的指针,它是指向下一个结点的后续指针。
ListNode 结构有一个有趣的属性,它包含一个指向相同类型数据结构的指针,因此可以说是一个包含对自身引用的类型。像这样的类型称为自引用数据类型或自引用数据结构。
当我们声明了一个数据类型来表示结点之后,可以用这个数据类型来定义一个初始为空的链表,方法是定义一个用作链表头的指针并将其初始化为nullptr:
ListNode *head = nullptr;现在可以创建一个链表,其中包含一个结点,将这个节点存储值为12.5:
head = new ListNode; //分配新结点
head->value = 12.5; //存储值
head->next = nullptr; //表示链表的结尾因为ListNode的数据类型包含了指向于先一个结点的指针,所以在没有下一个结点的情况之下,要使其等于nullptr。
如果我们创建一个新结点,在其中存储一个值为13.5的值,将其作为链表中的第二个结点,代码如下所示:
ListNode *secondPtr = new ListNode;
secondPtr->value = 13.5;
secondPtr->next = nullptr; //第二个结点是链表的结尾
head->next = secondPtr; //第一个结点指向第二个通过 head->next = secondPtr; 语句将链表头的后继指针改为指向第二个结点;指针 secondPtr->next 设置为 nullptr,可以使第二个结点成为链表的结尾。
由此我们得到了这样的一个程序:
// This program illustrates the creation || of linked lists.
#include <iostream>
using namespace std;
struct ListNode
{
double value;
ListNode *next;
};
int main()
{
ListNode *head = nullptr;
// Create first node with 12.5
head = new ListNode; // Allocate new node
head->value = 12.5; // Store the value
head->next = nullptr; // Signify end of list
// Create second node with 13.5
ListNode *secondPtr = new ListNode;
secondPtr->value = 13.5;
secondPtr->next = nullptr; // Second node is end of list
head->next = secondPtr; // First node points to second
// Print the list
cout << "First item is " << head->value << endl;
cout << "Second item is " << head->next->value << endl;//重点
return 0;
}程序的输出结果为:
First item is 12.5
Second item is 13.5在c++的结构体中可以有构造函数,对于定义链表结点类型的结构来说,如果能给它提供一个或多个构造函数,那么将会带来很大的方便,因为这样将使得结点在创建时可初始化。
如此,对ListNode结构进行另一个定义:
struct ListNode
{
double value;
ListNode *next;
//构造函数
ListNode(double valuel, ListNode *nextl = nullptr)
{
value = value1;
next = next1;
}
}使用上述的声明,可以使用以下两种不同的方式创建一个结点:
- 通过仅指定其value部分,而后续指针则默认为nullptr
- 通过指定value部分和一个指向链表下一个结点的指针
当需要创建一个结点放在链表的末尾时,第一种方式是很有用的;但是当创建新的结点讲被插入链表中间某个有后续节点的地方时,第二种方法是很有用的。
我们可以这样写:
ListNode *secondPtr = new ListNode(13.5);
ListNode *head = new ListNode(12.5, secondPtr);第一行代码创建了第二个结点,传递了13.5的值,而因为没有传递指针值,所以这个节点是链表的末尾;第二行代码创建了第一个结点,传递了12.5的值和指针值secondPtr作为存储在这个结点中的内存地址数据。
从链表头开始,涉及整个链表,并且在每个结点上执行一些处理操作的过程被称为遍历链表。
例如,如果需要打印某个链表中每个结点的内容,则必须遍历该链表。假设某个链表的链表头指针是 numberList,要遍历该链表,则需要使用另一个指针 ptr 指向链表的开头:
ListNode *ptr = numberList;然后就可以通过使用表达式 *ptr 或者使用结构指针操作符 -> 来处理由 ptr 指向的结点。例如,如果需要打印在结点上的值,则可以编写以下代码:
cout << ptr->value;一旦在该结点的处理完成,即可将指针移动到下一个结点(如果有的话),其语句如下:
ptr = ptr->next;以上语句使用指向结点后继的指针来替换了指向该结点的指针,实现了结点之间的移动。因此,要打印整个链表,可以使用如下代码:
ListNode *ptr = numberList;
while (ptr != nullptr)
{
cout << ptr->value << " "; //处理结点(显示结点内容)
ptr = ptr->next; //移动到下一个结点
}













 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









