







 分享了华为面试经历及失败原因,详细回顾了C++、数据结构、算法、操作系统等IT基础知识,包括sizeof与strlen区别、全局与局部变量、线程与进程、排序算法、二叉树遍历等内容。
分享了华为面试经历及失败原因,详细回顾了C++、数据结构、算法、操作系统等IT基础知识,包括sizeof与strlen区别、全局与局部变量、线程与进程、排序算法、二叉树遍历等内容。
后续补充:准备了这些来应对华为的面试,但是万万没想到挂在了业务主管面试上,可能是因为我被分到的是做AI的部门,他们比较看重AI的经历吧。我的毕设是通信和神经网络结合的,所以可能应该投通信算法岗或者数据通信部门的软件开发吧……当初随便选了一个做宣讲的部门,太草率了,唉。
这里说一下面试过程吧,一面:问了如何用队列实现栈,对内存的栈有了解吗,感觉那个人也不知道该问我什么,就问我学了什么,我说c++,于是就问了c++的多态。手撕代码比较简单,不用运行出结果。总之一面还是比较仁慈的,没有什么太偏的东西。(肯定不止这几个问题,只是我实在是想不起来了)
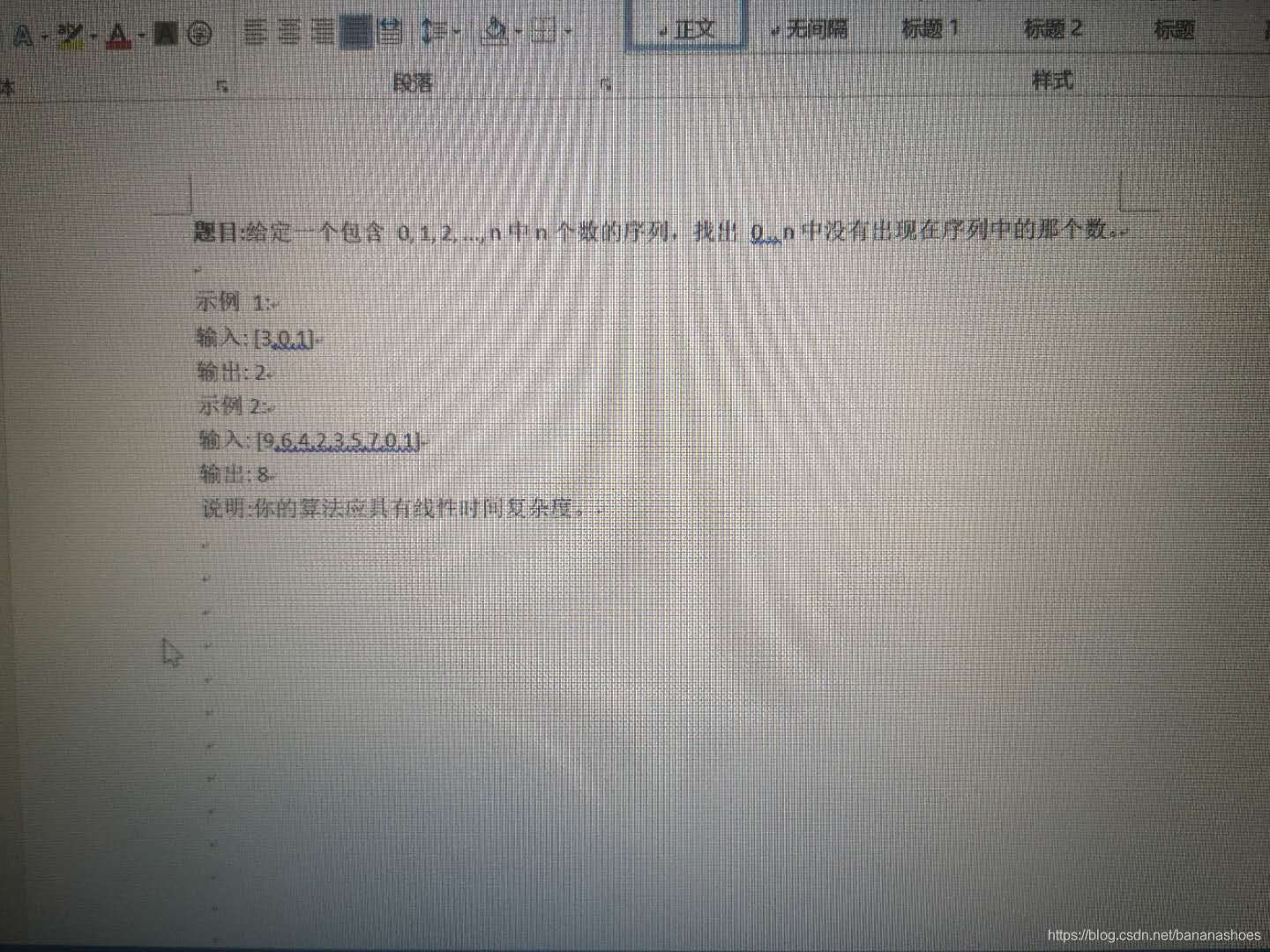
二面:项目经历问的比较细,但是我感觉和他们做的不相关。直接让写了一道编程题。一面二面两道题都写出来了,其中第二题我说我用了递归可能会溢出,他还说就是要用递归。也算是得到了一点点认可吧。
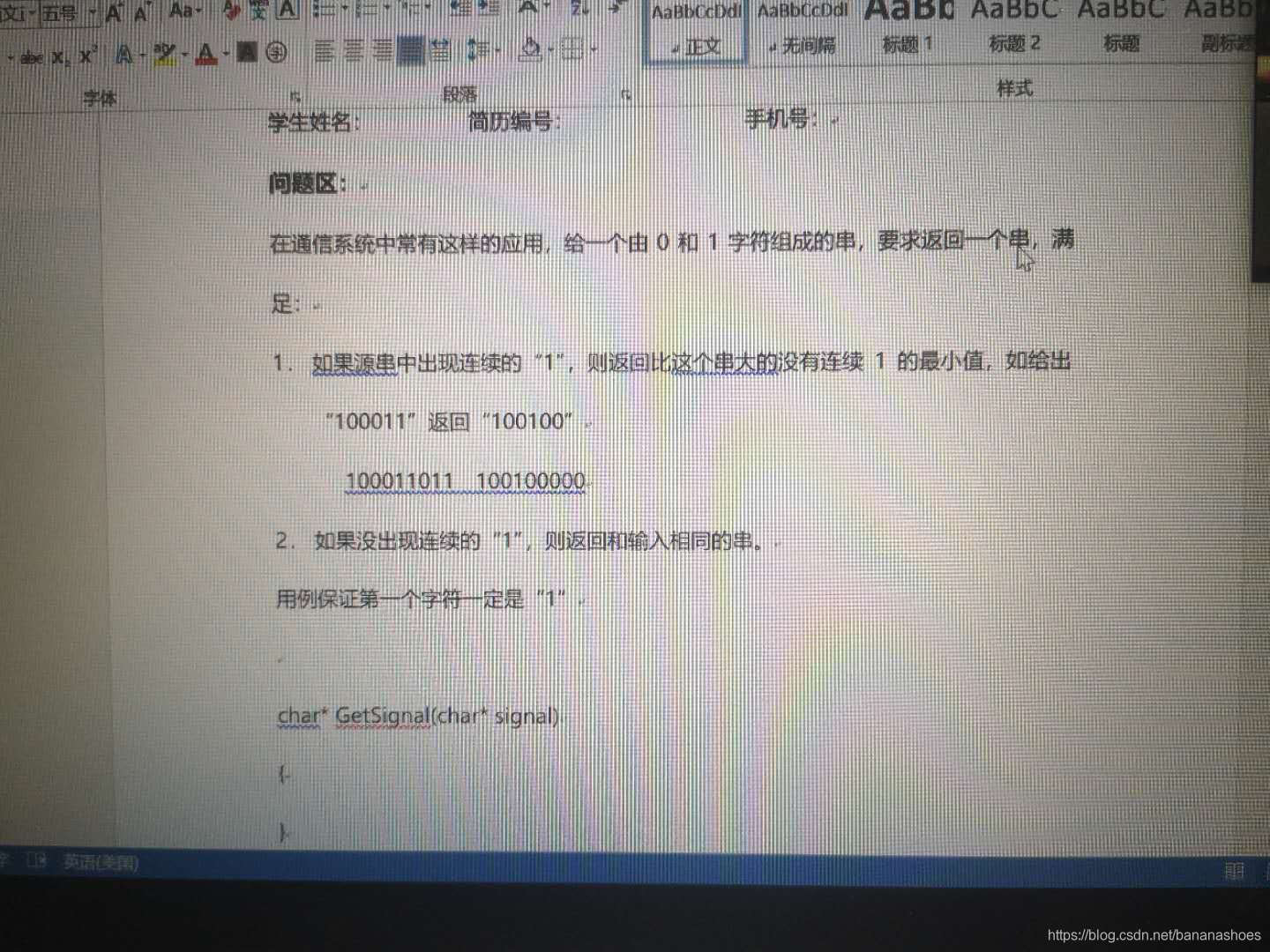
业务主管面试:问了问项目经历后,发现我做的比较水,说看我的简历里通信的东西比较多,为啥没有去无线部门(我考虑了地理位置的原因所以没有选无线)。最后直接说“我给其他部门的人推荐一下”,就结束了。几天后查了一下果然面试未通过。
下面就是我根据一些面经临时抱的佛脚:
1. c++ sizeof(),strlen()的区别:
sizeof是运算符,在头文件中typedef为unsigned int,其值在编译时即计算好了,参数可以是数组、指针、类型、对象、函数等。
数组-编译时分配的数组空间大小,即字节数
指针-存储该指针所用的空间大小(存储该指针的地址的长度,是长整型,应该为4)
类型-该类型所占的空间的大小
对象-对象的实际占用空间大小
函数-函数返回类型所占空间的大小
sizeof (data type)c++中计算数组长度可以使用: sizeof(arr)/sizeof(arr[0])
strlen是函数,要在运行时才能计算。参数必须是字符型指针。当数组名作为参数传入时,实际上数组就退化成指针了。它的功能是:返回字符串的长度。该字符串可能是自己定义的,也可能是内存中随机的,该函数实际完成的功能是从代表该字符串的第一个地址开始遍历,直到遇到结束符NULL。返回的长度大小不包括NULL。
总结:对于字符型数组(字符串),sizeof是求它实际分配的空间大小,strlen是计算结束符'\0'之前的字符个数。
2.全局变量,局部变量,static静态变量:
全局变量:具有全局作用域。全局变量只需在一个源文件中定义,就可以作用于所有的源文件。当然,其他不包含全局变量定义的源文件需要用extern 关键字再次声明这个全局变量。
局部变量:局部变量也只有局部作用域,它是自动对象(auto),它在程序运行期间不是一直存在,而是只在函数执行期间存在,函数的一次调用执行结束后,变量被撤销,其所占用的内存也被收回。
static全局变量:与全局变量的区别在于如果程序包含多个文件的话,它作用于定义它的文件里,不能作用到其它文件里,即被static关键字修饰过的变量具有文件作用域。这样即使两个不同的源文件都定义了相同名字的静态全局变量,它们也是不同的变量。
static局部变量:具有局部作用域,它只被初始化一次,自从第一次被初始化直到程序运行结束都一直存在,在静态存储区分配空间。而局部变量在栈里分配空间。
如果static和extern都没有,表示定义一个全局变量,其作用域限制在从定义开始到当前文件结尾。
static的作用是将全局变量的作用域限制在从定义开始到当前文件结尾,且其他文件不可以用extern来让这个变量可见。
extern的作用是声明一个已经在别处定义了的全局变量,它不是重新定义新的全局变量,而是起到扩展全局变量作用域的作用。
3.线程,进程
进程是资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列。进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行。
线程是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位。
一个进程可以由很多个线程组成,线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。
线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理。
- 一个CPU 内核只能跑一个线程。由于Intel公司引入的超线程技术,使得物理CPU内核和虚拟CPU内核存在一个1:2的关系拓展。
- CPU 将时间线分割成一个个的时间片,运用RR调度算法,进行时间片轮转,每个线程轮流获取CPU时间片进行操作。
参考链接:https://blog.csdn.net/u010454030/article/details/80728863###
https://www.cnblogs.com/frankcui/p/12422898.html
4.进程间消息通信机制
管道,消息队列,共享内存,信号量,socket,信号,文件锁
5.堆,栈,队列
堆是一棵完全二叉树:
1、其根结点的值小于两个子结点的值,其余任何一个结点的值都小于其子结点的值——小根堆。
2、其根结点的值大于两个子结点的值,其余任何一个结点的值都大于其子结点的值——大根堆。
栈是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。FILO
队列只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。FIFO
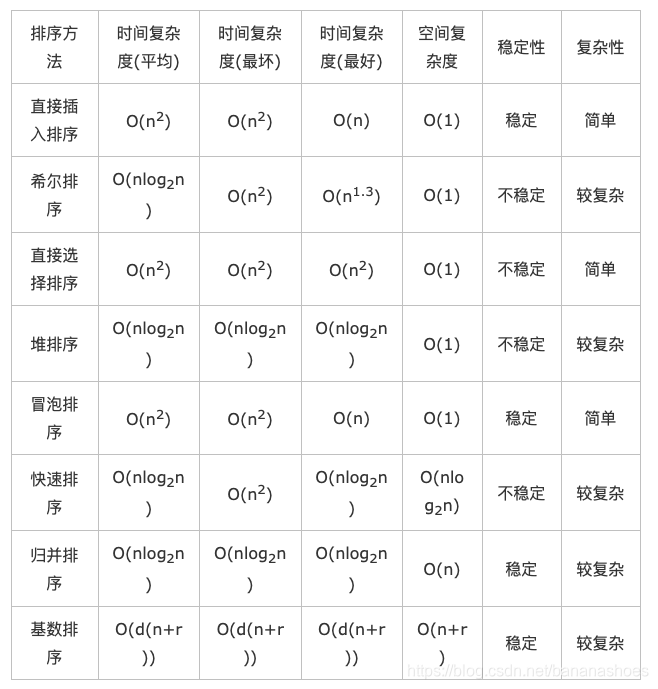
6.排序算法
插入排序:将未排序的数字a[j]与已排序的序列a[i],i=0,1,...,j-1从后往前一一比较,
如果a[j]大于a[i],则a[i+1]=a[i],
否则,a[i]=a[j],至此j个数字排好,j++,重复第一步。
时间复杂度:O(n2)
选择排序:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。 时间复杂度:O(n2)
冒泡排序:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。依次比较相邻的两个数,将小数放在前面,大数放在后面。即在第一轮比较中:首先比较第1个和第2个数,将小数放前,大数放后;然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。重复第一轮的步骤,直至全部排序完成。O(nlogn),最差的情况为倒序,复杂度为O(n2)
快速排序:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一轮扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分,直到各区间只有一个数。
堆排序:初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
7. 二叉树的前序中序后序遍历
前序:根左右,中序:左根右,后序:左右根
一般使用递归方法比较简洁,只用修改递归调用和访问根节点值的顺序:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<int> res;
vector<int> inorderTraversal(TreeNode* root) {
if(root){
inorderTraversal(root->left);
res.push_back(root->val);
inorderTraversal(root->right);
}
return res;
}
};
#另一种使用标记判断是否访问过,若没有访问过(white),则将其左右子树入栈,并标记此节点为访问过(gray)。
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
WHITE, GRAY = 0, 1
res = []
stack = [(WHITE, root)]
while stack:
color, node = stack.pop()
if node is None: continue
if color == WHITE:
stack.append((WHITE, node.right))
stack.append((GRAY, node))
stack.append((WHITE, node.left))
else:
res.append(node.val)
return res
8.二叉搜索树
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
AVL树本质上还是一棵二叉搜索树,它的特点是:
- 本身首先是一棵二叉搜索树。
- 带有平衡条件:每个结点的左右子树的高度之差的绝对值(平衡因子)最多为1。
也就是说,AVL树,本质上是带了平衡功能的二叉查找树(二叉排序树,二叉搜索树)。
9.深度优先和广度优先搜索
对于二叉树来说,深度优先搜索等价于前序遍历。

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









