







本文在页表方面参考了这篇博客,特别鸣谢!
1. 页帧和页框
页帧(page frame)是内存的最小可分配单元,也开始称作页框,Linux下页帧的大小为4KB。
内核需要将他们用于所有的内存需求,例如有些页帧需要将物理内存映射到用户模式进程的虚拟地址空间。为了有效管理这些操作,就需要区分当前使用的页帧和空闲的可用页帧。通过数据结构struct page来实现

缺页中断:OS通过页表寻址时,发现目标内容不在物理内存中
页表有标记位,通过标记位来判断,而且这时页表填的是文件在磁盘中的地址(可以理解为LBA地址)
缺页中断处理流程:
- 申请内存
- 在磁盘中找到目标内容的地址
- 把内容加载到内存指定的位置
- 重新填充页表
- 返回用户,终止异常
在CPU中有两个寄存器CR2和CR3,CR3用于指向页表目录,CR2保存引起缺页异常或中断的地址
2. 页表
进程虚拟地址访问操作,都需要页表从虚拟地址转换为物理地址,页表提供虚拟地址到物理地址的映射关系
接下来都是以32位来举例
有没有思考过这样一个问题,页表也是数据,需要保存在内存中,它需要占用多少内存呢?
假如一个页表,一行也被称为页表项,需要保存两个地址就按照32位下两个指针也就是8字节,还有一些标志位用来判断页表映射的情况,合在一块算个整数10字节。虚拟地址空间一共有2^32个地址就要2^32*10字节,这么算下来就要40GB,一个页表就要这么多空间,是不是很夸张,而且每个进程都要一个页表,内存仅仅用来保存一个页表都远远不够,那操作系统的页表是怎么样的呢?
地址有32位,被分为三段,前两段分为两个10位,最后12位,最后12位刚好对应4*2^10,
每一位对应一个字节的话,刚好是4KB
页表采用多级页表连续映射,一级页表也被称为页表目录,负责地址空间前10位的映射关系,相当于把4GB的空间,分成每4MB为一个单元,作为搜索的单位;一级页表的页表项指向二级页表,进行更加细粒度的地址映射,负责中间10位的映射关系,把4MB空间,分成每4KB为一个单元,这样二级页表就可以搜索定位到对应的页框,指向对应页框的起始地址
最后在通过虚拟地址的后12位,也就是页框的偏移量找到对应的物理地址,刚好4KB
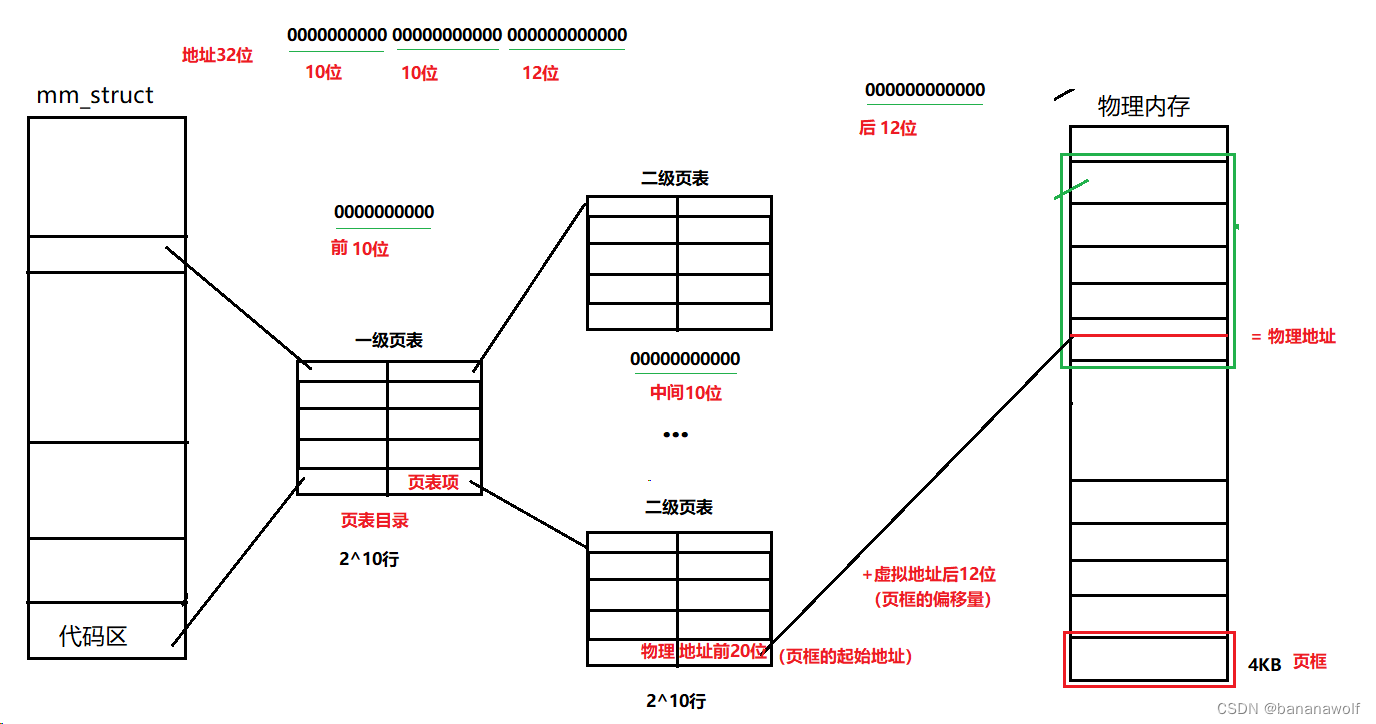
为什么虚拟地址的后12位,就是页框的偏移量呢?
除了物理内存之外, 磁盘中的程序在编译的时候, 也是按照4KB为单位划分好的,那么操作系统通过程序中的地址区域进一步生成的进程地址空间, 其实也会按照4KB为单位划分。
只能说一切都不是巧合,都是操作系统安排好的,围绕page页为标准
页表设计的优点:
- 进程虚拟地址管理与物理地址管理之间,通过页表和page完成了解耦
- 更加节省内存
- 方便管理
解耦: 进程虚拟地址与物理内存之间不存在实际具体数据的关联, 从虚拟地址找物理地址只能做到判断物理地址、数据是否存在, 而不会有数值耦合的情况
节省空间:页表目录KB级别大小,二级页表也就MB级别的,和之前的计算数据相比大大减少了,而且一级页表和二级页表分离,二级页表就可以按需创建和分配
方便管理:从页目录这张第一级页表, 去找指定的第二级页表, 这个结构其实就像是一颗多叉树. 第二级页表就可以像树的节点一样, 按需创建、删除、管理等
3. vm_area_struct
通过之前的学习,我们知道mm_struct中包含很多的字段用于规划虚拟内存空间的堆栈等待的起始地址和结束地址
mm_struct 部分代码如下:
struct mm_struct
{
/*...*/
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
u64 vmacache_seqnum; /* per-thread vmacache */
unsigned long mmap_base; /*映射基地址*/
unsigned long mmap_legacy_base; /*不是很明白这里*/
unsigned long task_size; /*该进程能够vma使用空间大小*/
unsigned long highest_vm_end; /*该进程能够使用的vma结束地址*/
pgd_t * pgd;
atomic_t mm_users;
atomic_t mm_count;
int map_count; /* vma的总个数 */
unsigned long total_vm; /* 映射的总页面数*/
/*...*/
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack; /* 堆栈起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 环境变量和参数的起始和结束地址 */
/*...*/
但是这些都是对虚拟地址空间大致做的区域划分,如果空间不是连续所有的,例如堆的空间申请就是一块一块的不连续,这时光光上面的区域划分就不够细致,所以就有了接下来的vm_area_struct结构体,用来做空间资源的细粒度划分,描述虚拟地址空间中的线性内存区域(连续空间)
vm_area_struct 代码如下:
struct vm_area_struct {
unsigned long vm_start; //虚存区起始
unsigned long vm_end; //虚存区结束
struct vm_area_struct *vm_next, *vm_prev; //前后指针
struct rb_node vm_rb; //红黑树中的位置
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm; //所属的 mm_struct
pgprot_t vm_page_prot;
unsigned long vm_flags; //标志位
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; //vma对应的实际操作
unsigned long vm_pgoff; //文件映射偏移量
struct file * vm_file; //映射的文件
void * vm_private_data; //私有数据
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
其中包含vm_start和vm_end分别表示资源的起始地址和结束地址,其结构是双链表。
完。















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









