









 本文深入探讨了ptmalloc、tcmalloc和jemalloc三种内存分配策略,分析了各自的特点、原理及性能对比,尤其强调了在多线程环境下tcmalloc和jemalloc的显著优势。
本文深入探讨了ptmalloc、tcmalloc和jemalloc三种内存分配策略,分析了各自的特点、原理及性能对比,尤其强调了在多线程环境下tcmalloc和jemalloc的显著优势。
目录
内存优化总结:ptmalloc、tcmalloc和jemalloc
前言
bandaoyu 本文随时更新,链接:http://t.csdn.cn/ChbHPhttps://blog.csdn.net/bandaoyu/article/details/108630996
一. 安装
tcmalloc在gperftools之中,故想要使用tcmalloc,就得先安装gperftools。在linux下,其安装步骤如下:
tar xzvf gperftools-2.1.tar.gz (或者用git clone https://github.com/gperftools/gperftools.git下载)
cd gperftools-2.1
./autogen.sh
./configure --enable-frame-pointers
make
make install
这里需要注意一点,在linux下,如果直接./configure,那么make时会报出编译错误:error Cannot calculate stack trace: will need to write for your environment。解决方法如上所示,在configure时加入选项--enable-frame-pointers。
如果想定制化安装,请自行参阅gperftools的安装文档,即源码包中的INSTALL文件。
二. 使用
使用方法
对于tcmalloc的使用,还是用程序来说明吧。
tcmalloc_sample.cpp:
#include <iostream>
#include <google/tcmalloc.h>
int main()
{
char *cp = (char *)tc_malloc(23 * sizeof(char));
tc_free(cp);
cp = NULL;
return 0;
}注:以下的步骤都是以第一部分所述的安装方式为前提而进行的。
1. 编译:g++ -o tcmalloc_sample -g tcmalloc_sample.cpp -ltcmalloc
2. 运行: ./tcmalloc_sample
如果遇到以下错误:
error while loading shared libraries: libtcmalloc.so.4: cannot open shared object file: No such file or directory
那么就需要为系统指定libtcmalloc的加载路径:
1. echo /usr/local/lib > /etc/ld.so.conf.d/libtcmalloc.conf
2. ldconfig
现在运行./tcmallco_sample命令,就不会出现上面提到的错误了。
对比测试
tmtest.cpp
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <time.h>
#include <sys/time.h>
#include <thread>
#define MAX_COUNT 1000*1000
using namespace std;
void fun(int i)
{
//char *ptr = (char *)malloc(i);
//free(ptr);
char *ptr = new char[1];
delete[] ptr;
}
void fun_thread(void )
{
int i = 0;
int j = 1;
while(i++ < MAX_COUNT)
{
j ++;
fun(j);
if ( j > 1024 )
j = 1;
}
}
#define MSECOND 1000000
int main()
{
struct timeval tpstart, tpend;
float timeuse;
gettimeofday(&tpstart, NULL);
thread t(fun_thread);
t.join();
int i = 0;
int j = 1;
while(i++ < MAX_COUNT)
{
j ++;
fun(i);
if ( j > 1024 )
j = 1;
//usleep(1);
}
gettimeofday(&tpend, NULL);
timeuse = MSECOND * (tpend.tv_sec - tpstart.tv_sec) + tpend.tv_usec - tpstart.tv_usec;
timeuse /= MSECOND;
printf("Used Time:%f\n", timeuse);
return 0;
}#正常
[root@localhost test]# g++ tmtest.cpp -o 1 -lpthread
[root@localhost test]# ./tmtest
Used Time:5.336594
#替换malloc
[root@localhost test]# g++ tmtest.cpp -o 1 -lpthread -ltcmalloc
[root@localhost test]# ./tmtest
Used Time:0.208050
三、如何替换libc中的malloc
如何替换libc中的malloc -https://zhuanlan.zhihu.com/p/387038698
libc中使用的malloc是在ptmalloc库,但如果我们希望使用tcmalloc库中的malloc和free来分配和释放内存时,我们应该如何做呢?接下来我们分析一下集中方法:
1、使用环境变量LD_PRELOAD
环境变量LD_PRELOAD指定了动态库链接的仅次于rpath(生成在可执行文件中:https://blog.csdn.net/bandaoyu/article/details/113181179)的最高优先级顺序,当我们将LD_PRELOAD设置为tcmalloc.so时:
$ LD_PRELOAD="/usr/lib/libtcmalloc.so"那么tcmalloc.so中的符号将拥有最高优先级,那么他将比libc中的malloc和free先被链接,从而达到替换libc中malloc和free的效果。
2、编译动态库或可执行程序时带上tcmalloc库的选项
我们在编译时,我们直接指定tcmalloc这个库,例如:
$ gcc -o main main.cc -L. -ltcmalloc -Wl,-rpath,.这样编译出来的可执行程序main使用的malloc和free将来自tcmalloc。
3、通过链接过程控制
链接器ld有一个编译选项-wrap,当需要查找某个符号xxx时,它会优先查找__wrap_xxx,如果解析不到__wrap_xxx时才会去查找xxx。例如,我们在foo.c中定义了如下函数:
// foo.c
#include <stdio.h>
void *__wrap_malloc(size_t sz) {
printf("__wrap_malloc: size = %d\n", sz);
return NULL;
}
void main() {
malloc(10);
}
那么在编译时,所有对malloc符号的解析会优先查找__wrap_malloc符号。也就是说,所有对malloc的调用会被调用到__wrap_malloc这个函数上。
$ gcc foo.c -o foo -Wl,-wrap,malloc
$ ./foo
__wrap_malloc: size = 104、替换内建的malloc/free
在编译程序的时候,gcc添加下面的选项,
-fno-builtin-malloc -fno-builtin-calloc -fno-builtin-realloc -fno-builtin-free
参考资料:
To use TCMalloc, just link TCMalloc into your application via the "-ltcmalloc" linker flag.
You can use TCMalloc in applications you didn't compile yourself, by using LD_PRELOAD:
$ LD_PRELOAD="/usr/lib/libtcmalloc.so"
LD_PRELOAD is tricky, and we don't necessarily recommend this mode of usage.
TCMalloc includes a heap checker and heap profiler as well.
If you'd rather link in a version of TCMalloc that does not include the heap profiler四、原理
(tcmalloc原理 - https://www.jianshu.com/p/7c55fbdef679)
(原理简单概括:内存池要解决的问题之一就是频繁的申请与释放,一般是在预分配里先找,有合适的用合适的,没有合适的再向系统申请,然后记录这块内存,最开始的版本大部分是统一管理,后面分了线程本地,线程本地解决了同步用锁,效率更高了)
tcmalloc为什么快:
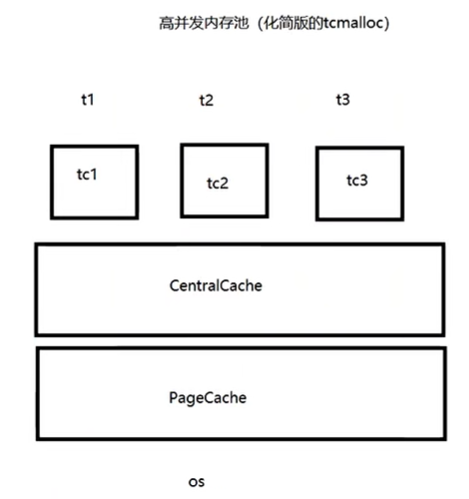
使用了thread cache(线程cache,通常在几 KB 到几十 KB 之间,跟版本有关,参考源码),小块的内存分配都可以从cache中分配,这样再多线程分配内存的情况下,可以减少锁竞争。
tcmalloc将内存请求分为两类,大对象请求和小对象请求,大对象为>=32K的对象。
tcmalloc会为每个线程分配本地缓存,小对象请求可以直接从本地缓存获取,如果没有空闲内存,则从central heap中一次性获取一连串小对象。大对象是直接使用页级分配器(page-level allocator)从Central page Heap中进行分配,即一个大对象总是按页对齐的。
tcmalloc对于小内存,按8的整数次倍分配,对于大内存,按4K的整数次倍分配。
当某个线程缓存中所有对象的总大小超过2MB的时候,会进行垃圾收集。垃圾收集阈值会自动根据线程数量的增加而减少,这样就不会因为程序有大量线程而过度浪费内存。

tcmalloc为每个线程分配一个thread-local cache,小对象的分配直接从thread-local cache中分配。当thread-local cache不足时, 则从CentralHeap申请内存对象,然后移动到thread-local cache中管理,同时定期的用垃圾回收器把内存从thread-local cache回收到Central free list中。
链接:https://www.jianshu.com/p/7c55fbdef679
10、总结
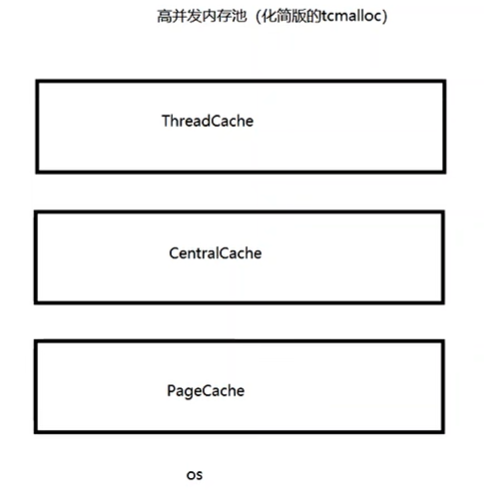
tcmalloc的内存分配分为四层:
ThreadCache(用于小对象分配):线程本地缓存,每个线程独立维护一个该对象,多线程在并发申请内存时不会产生锁竞争。
CentralCache(Central free list,用于小对象分配):全局cache,所有线程共享。当thread cache空闲链表为空时,会批量从CentralCache中申请内存;当thread cache总内存超过阈值,会进行内存垃圾回收,将空闲内存返还给CentralCache。
Page Heap(小/大对象):全局页堆,所有线程共享。对于小对象,当centralcache为空时(既内容不足),会从page heap中申请一个span;当一个span完全空闲时,会将该span返还给page heap。对于大对象,直接从page heap中分配,用完直接返还给page heap。
系统内存:当page cache内存用光后,会通过sbrk、mmap等系统调用向OS申请内存。
(tcmalloc内存分配与使用分析_weixin_30341745的博客-CSDN博客)


背景:
今天对服务器进行压测,模拟的请求量到4万次/分的时候,进程的CPU占用就已经达到400%了(也就是把四个核都占到100%)。其实模拟的请求数据都是单一的,不会因为BUG的原因导致CPU过高。怀疑是代码里的STL用得过多,加之ttserver和memcached大量的读操作——大量的小内存分配可能带来全局的锁竞争,从而可能使得CPU过高。
之前听说过google的tcmalloc是一个很好的线程内的内存分配器,能够提高内存分配的性能。正好今天试试能不能改善我的代码的性能。
安装的过程如下:
#1、到google下载代码:
cd /home/ahfu/temp
wget https://gperftools.googlecode.com/files/gperftools-2.1.tar.gz#解压
tar -zxvf google-perftools-1.4.tar.gz
#看看说明
cd google-perftools-1.4
./configure -h
#选择简单的安装
mkdir -p /home/ahfu/temp/tcmalloc
./configure --disable-cpu-profiler --disable-heap-profiler --disable-heap-checker --disable-debugalloc --enable-minimal --disable-shared
make && make install
#在makefile里面加入一行就行
LIB = "/home/ahfu/temp/tcmalloc/lib/libtcmalloc_minimal.a"
# g++ ..... ${LIB}
再进行压测!
大吃一惊!
请求量模拟到28万次/分后,CPU占用还不到20%!!!
五、问题或质疑
为什么测试的TCMalloc不靠谱,性能反而差了?
为什么测试的TCMalloc不靠谱,性能反而差了:https://bbs.csdn.net/topics/390368040?page=2
问题:发现确实在release下性能用了tcmalloc后提升很多时间缩短了100%以上,但是debug反而比不用tcmalloc的差。
int _tmain(int argc, _TCHAR* argv[])
{
DWORD pre = GetTickCount();
int i;
for ( i=0; i<100000; i++)
{
char * p1= new char[100];
char * p2= new char[200];
char * p3= new char[300];
char * p4= new char[500];
delete [] p1;
delete [] p2;
delete [] p3;
delete [] p4;
// char * p1=(char*)malloc(100);
// char * p2= (char*)malloc(200);
// char * p3= (char*)malloc(300);
// char * p4= (char*)malloc(500);
//
// free(p1);
// free(p2);
// free(p3);
// free(p4) ;
}
std::cout <<i<<"times cost (ms)"<< GetTickCount()-pre;
getchar();
return 0;
}
测试结果:
不加TC, 78ms
加 了TC,反而更长,156ms
环境:winxp sp3 vc2008答1:
这种测试代码是不靠谱的 因为这种申请后马上释放,再申请,可能会复用前一次的内存(释放给系统后,不会马上归还到虚拟/物理内存) 公平的测试方法是随机分配(随机大小)、随机释放。 还有tcmalloc在多线程才显优势
答2:那是因为MSVC已经默认用上了内存池,tcmalloc的内存池效率不如ms的。
tcmalloc是尬尴的存在?
[C++] tcmalloc的尴尬_王绍全的博客-https://blog.csdn.net/wwwsq/article/details/7076481
“专用的‘对象池’可以比通用的‘内存池’性能高两个数量级。
通过宏定义(DECL_MEM_POOL, IMPL_MEM_POOL)可以很快速的为class增加pool能力,还可以在单线程的环境下去掉锁。
真正要性能的程序不会整天去分配内存。性能要求没那么高的程序glibc就够了。
所以,tcmalloc是一个很尴尬的东西。
ps:tcmalloc据说可以用来优化mysql(让mysql加载tcmalloc来代替glibc的相应函数)。不过mysql的性能瓶颈在于磁盘、索引、缓存,替换malloc能有多少作用很值得怀疑。”
六、其他相似的库Jemalloc
ptmalloc是glibc默认的malloc库。
Jemalloc和tcmalloc 区别:
《ptmalloc,tcmalloc和jemalloc内存分配策略研究》http://www.360doc.cn/mip/435803027.html
总结
Jemalloc设计上比前两个复杂地多,其内部使用了红黑树管理分页和内存块。并且对内存分配粒度分类地更细。这导致一方面比ptmalloc的锁争用要少,另一方面很多索引和查找都能回归到指数级别,方便了很多复杂功能的实现。而且在大内存分配上,内存碎片也会比tcmalloc少。但是也正是因为他的结构比较复杂,记录了很多meta,所以在分配很多小内存的时候记录meta数据的空间会略微多于tcmalloc。但是又不像ptmalloc那样每一个内存块都有一个header,而采用全局的bitmap记录状态,所以大量小内存的时候,会比ptmalloc消耗的额外内存小。
大总结
看这些个分配器的分配机制,可见这些内存管理机制都是针对小内存分配和管理。对大块内存还是直接用了系统调用。所以在程序中应该尽量避免大内存的malloc/new、free/delete操作。另外这个分配器的最小粒度都是以8字节为单位的,所以频繁分配小内存,像int啊bool啊什么的,仍然会浪费空间。经过测试无论是对bool、int、short进行new的时候,实际消耗的内存在ptmalloc和tcmalloc下64位系统地址间距都是32个字节。大量new测试的时候,ptmalloc平均每次new消耗32字节,tcmalloc消耗8字节(我想说ptmalloc弱爆啦,而且tcmalloc)。所以大量使用这些数据的时候不妨用数组自己维护一个内存池,可以减少很多的内存浪费。(原来STL的map和set一个节点要消耗近80个字节有这么多浪费在这里了啊)
而多线程下对于比较大的数据结构,为了减少分配时的锁争用,最好是自己维护内存池。单线程的话无所谓了,呵呵。不过自己维护内存池是增加代码复杂度,减少内存管理复杂度。但是我觉得,255个分页以下(1MB)的内存话,tcmalloc的分配和管理机制已经相当nice,没太大必要自己另写一个。
另外,Windows下内存分配方式不知道,不同类型(int、short和bool)连续new的地址似乎是隔开的,可能是内部实现的粒度更小,不同size的class更多。测试10M次new的时候,debug模式下明显卡顿了一下,平均每次new的内存消耗是52字节(32位)和72字节(64位)[header更复杂?]。但是Release模式下很快,并且平均每次new的内存消耗是20字节(32位)和24字节(64位)。可以猜测VC的malloc的debug模式还含有挺大的debug信息。是不是可以得出他的header里,Release版本只有1个指针,Debug里有5个指针呢?
更多详细文档:TCMalloc解密 - https://www.jianshu.com/p/11082b443ddf
内存优化总结:ptmalloc、tcmalloc和jemalloc
发表于 2016-06-13
概述
需求
系统的物理内存是有限的,而对内存的需求是变化的, 程序的动态性越强,内存管理就越重要,选择合适的内存管理算法会带来明显的性能提升。
比如nginx, 它在每个连接accept后会malloc一块内存,作为整个连接生命周期内的内存池。 当HTTP请求到达的时候,又会malloc一块当前请求阶段的内存池, 因此对malloc的分配速度有一定的依赖关系。(而apache的内存池是有父子关系的,请求阶段的内存池会和连接阶段的使用相同的分配器,如果连接内存池释放则请求阶段的子内存池也会自动释放)。
目标
内存管理可以分为三个层次,自底向上分别是:
- 操作系统内核的内存管理
- glibc层使用系统调用维护的内存管理算法
- 应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如使用引用计数std::shared_ptr,apache的内存池方式等等。
当然应用程序也可以直接使用系统调用从内核分配内存,自己根据程序特性来维护内存,但是会大大增加开发成本。
本文主要介绍了glibc malloc的实现,及其替代品
一个优秀的通用内存分配器应具有以下特性:
- 额外的空间损耗尽量少
- 分配速度尽可能快
- 尽量避免内存碎片
- 缓存本地化友好
- 通用性,兼容性,可移植性,易调试
现状
目前大部分服务端程序使用glibc提供的malloc/free系列函数,而glibc使用的ptmalloc2在性能上远远弱后于google的tcmalloc和facebook的jemalloc。 而且后两者只需要使用LD_PRELOAD环境变量启动程序即可,甚至并不需要重新编译。
glibc ptmalloc2
ptmalloc2即是我们当前使用的glibc malloc版本。
ptmalloc原理
系统调用接口

上图是 x86_64 下 Linux 进程的默认地址空间, 对 heap 的操作, 操作系统提供了brk()系统调用,设置了Heap的上边界; 对 mmap 映射区域的操作,操作系 统 供了 mmap()和 munmap()函数。
因为系统调用的代价很高,不可能每次申请内存都从内核分配空间,尤其是对于小内存分配。 而且因为mmap的区域容易被munmap释放,所以一般大内存采用mmap(),小内存使用brk()。
多线程支持
- Ptmalloc2有一个主分配区(main arena), 有多个非主分配区。 非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。 当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。
- free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的开销就会增大。
ptmalloc内存管理
- 用户请求分配的内存在ptmalloc中使用chunk表示, 每个chunk至少需要8个字节额外的开销。 用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。
-
ptmalloc 将相似大小的 chunk 用双向链表链接起来, 这样的一个链表被称为一个 bin。Ptmalloc 一共 维护了 128 个 bin,并使用一个数组来存储这些 bin(如下图所示)。

数组中的第一个为 unsorted bin, 数组中从 2 开始编号的前 64 个 bin 称为 small bins, 同一个small bin中的chunk具有相同的大小。small bins后面的bin被称作large bins。 -
当free一个chunk并放入bin的时候, ptmalloc 还会检查它前后的 chunk 是否也是空闲的, 如果是的话,ptmalloc会首先把它们合并为一个大的 chunk, 然后将合并后的 chunk 放到 unstored bin 中。 另外ptmalloc 为了提高分配的速度,会把一些小的(不大于64B) chunk先放到一个叫做 fast bins 的容器内。
- 在fast bins和bins都不能满足需求后,ptmalloc会设法在一个叫做top chunk的空间分配内存。 对于非主分配区会预先通过mmap分配一大块内存作为top chunk, 当bins和fast bins都不能满足分配需要的时候, ptmalloc会设法在top chunk中分出一块内存给用户, 如果top chunk本身不够大, 分配程序会重新mmap分配一块内存chunk, 并将 top chunk 迁移到新的chunk上,并用单链表链接起来。如果free()的chunk恰好 与 top chunk 相邻,那么这两个 chunk 就会合并成新的 top chunk,如果top chunk大小大于某个阈值才还给操作系统。主分配区类似,不过通过sbrk()分配和调整top chunk的大小,只有heap顶部连续内存空闲超过阈值的时候才能回收内存。
- 需要分配的 chunk 足够大,而且 fast bins 和 bins 都不能满足要求,甚至 top chunk 本身也不能满足分配需求时,ptmalloc 会使用 mmap 来直接使用内存映射来将页映射到进程空间。

ptmalloc分配流程

ptmalloc的缺陷
- 后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
- 多线程锁开销大, 需要避免多线程频繁分配释放。
- 内存从thread的areana中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。 比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用了。
- 每个chunk至少8字节的开销很大
- 不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值。
tcmalloc
tcmalloc是Google开源的一个内存管理库, 作为glibc malloc的替代品。目前已经在chrome、safari等知名软件中运用。
根据官方测试报告,ptmalloc在一台2.8GHz的P4机器上(对于小对象)执行一次malloc及free大约需要300纳秒。而TCMalloc的版本同样的操作大约只需要50纳秒。
小对象分配
- tcmalloc为每个线程分配了一个线程本地ThreadCache,小内存从ThreadCache分配,此外还有个中央堆(CentralCache),ThreadCache不够用的时候,会从CentralCache中获取空间放到ThreadCache中。
- 小对象(<=32K)从ThreadCache分配,大对象从CentralCache分配。大对象分配的空间都是4k页面对齐的,多个pages也能切割成多个小对象划分到ThreadCache中。

小对象有将近170个不同的大小分类(class),每个class有个该大小内存块的FreeList单链表,分配的时候先找到best fit的class,然后无锁的获取该链表首元素返回。如果链表中无空间了,则到CentralCache中划分几个页面并切割成该class的大小,放入链表中。

CentralCache分配管理
- 大对象(>32K)先4k对齐后,从CentralCache中分配。 CentralCache维护的PageHeap如下图所示, 数组中第256个元素是所有大于255个页面都挂到该链表中。

- 当best fit的页面链表中没有空闲空间时,则一直往更大的页面空间则,如果所有256个链表遍历后依然没有成功分配。 则使用sbrk, mmap, /dev/mem从系统中分配。
- tcmalloc PageHeap管理的连续的页面被称为span.
如果span未分配, 则span是PageHeap中的一个链表元素
如果span已经分配,它可能是返回给应用程序的大对象, 或者已经被切割成多小对象,该小对象的size-class会被记录在span中 - 在32位系统中,使用一个中央数组(central array)映射了页面和span对应关系, 数组索引号是页面号,数组元素是页面所在的span。 在64位系统中,使用一个3-level radix tree记录了该映射关系。

回收
- 当一个object free的时候,会根据地址对齐计算所在的页面号,然后通过central array找到对应的span。
- 如果是小对象,span会告诉我们他的size class,然后把该对象插入当前线程的ThreadCache中。如果此时ThreadCache超过一个预算的值(默认2MB),则会使用垃圾回收机制把未使用的object从ThreadCache移动到CentralCache的central free lists中。
- 如果是大对象,span会告诉我们对象锁在的页面号范围。 假设这个范围是[p,q], 先查找页面p-1和q+1所在的span,如果这些临近的span也是free的,则合并到[p,q]所在的span, 然后把这个span回收到PageHeap中。
- CentralCache的central free lists类似ThreadCache的FreeList,不过它增加了一级结构,先根据size-class关联到spans的集合, 然后是对应span的object链表。如果span的链表中所有object已经free, 则span回收到PageHeap中。
tcmalloc的改进
- ThreadCache会阶段性的回收内存到CentralCache里。 解决了ptmalloc2中arena之间不能迁移的问题。
- Tcmalloc占用更少的额外空间。例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。Ptmalloc2使用最少8字节描述一个chunk。
- 更快。小对象几乎无锁, >32KB的对象从CentralCache中分配使用自旋锁。 并且>32KB对象都是页面对齐分配,多线程的时候应尽量避免频繁分配,否则也会造成自旋锁的竞争和页面对齐造成的浪费。
性能对比
官方测试
测试环境是2.4GHz dual Xeon,开启超线程,redhat9,glibc-2.3.2, 每个线程测试100万个操作。

上图中可以看到尤其是对于小内存的分配, tcmalloc有非常明显性能优势。

上图可以看到随着线程数的增加,tcmalloc性能上也有明显的优势,并且相对平稳。
github mysql优化
https://github.com/blog/1422-tcmalloc-and-mysql
Jemalloc
jemalloc是facebook推出的, 最早的时候是freebsd的libc malloc实现。 目前在firefox、facebook服务器各种组件中大量使用。
jemalloc原理
- 与tcmalloc类似,每个线程同样在<32KB的时候无锁使用线程本地cache。
- Jemalloc在64bits系统上使用下面的size-class分类:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB]
Huge: [4 MiB, 8 MiB, 12 MiB, …] - small/large对象查找metadata需要常量时间, huge对象通过全局红黑树在对数时间内查找。
- 虚拟内存被逻辑上分割成chunks(默认是4MB,1024个4k页),应用线程通过round-robin算法在第一次malloc的时候分配arena, 每个arena都是相互独立的,维护自己的chunks, chunk切割pages到small/large对象。free()的内存总是返回到所属的arena中,而不管是哪个线程调用free()。

上图可以看到每个arena管理的arena chunk结构, 开始的header主要是维护了一个page map(1024个页面关联的对象状态), header下方就是它的页面空间。 Small对象被分到一起, metadata信息存放在起始位置。 large chunk相互独立,它的metadata信息存放在chunk header map中。
- 通过arena分配的时候需要对arena bin(每个small size-class一个,细粒度)加锁,或arena本身加锁。
并且线程cache对象也会通过垃圾回收指数退让算法返回到arena中。

jemalloc的优化
- Jmalloc小对象也根据size-class,但是它使用了低地址优先的策略,来降低内存碎片化。
- Jemalloc大概需要2%的额外开销。(tcmalloc 1%, ptmalloc最少8B)
- Jemalloc和tcmalloc类似的线程本地缓存,避免锁的竞争
- 相对未使用的页面,优先使用dirty page,提升缓存命中。
性能对比
官方测试

上图是服务器吞吐量分别用6个malloc实现的对比数据,可以看到tcmalloc和jemalloc最好(facebook在2011年的测试结果,tcmalloc这里版本较旧)。
4.3.2 mysql优化
测试环境:2x Intel E5/2.2Ghz with 8 real cores per socket,16 real cores, 开启hyper-threading, 总共32个vcpu。 16个table,每个5M row。
OLTP_RO测试包含5个select查询:select_ranges, select_order_ranges, select_distinct_ranges, select_sum_ranges,

可以看到在多核心或者多线程的场景下, jemalloc和tcmalloc带来的tps增加非常明显。
2. jason在多处理器下的一个实验

x轴是线程数,y轴是性能。
在单线程下,彼此相差不多,dlmalloc(Doug Lea’s malloc, been around forever)稍占优势。
在多线程下,dlmalloc和pkgmalloc性能急剧下降,而jemalloc在线程数和处理器数一致的时候,性能达到最高,线程数继续增加能保持稳定。
参考资料
glibc内存管理ptmalloc源代码分析
Inside jemalloc
tcmalloc浅析
tcmalloc官方文档
Scalable memory allocation using jemalloc
mysql-performance-impact-of-memory-allocators-part-2
ptmalloc,tcmalloc和jemalloc内存分配策略研究
Tick Tock, malloc Needs a Clock
总结
在多线程环境使用tcmalloc和jemalloc效果非常明显。
当线程数量固定,不会频繁创建退出的时候, 可以使用jemalloc;反之使用tcmalloc可能是更好的选择。
- 本文作者: bhpike65
- 本文链接: 内存优化总结:ptmalloc、tcmalloc和jemalloc | bhpike65


















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









