







前言
官网:
Argobots Home:https://collab.cels.anl.gov/display/ARGOBOTS/Argobots+Home
wiki:https://github.com/pmodels/argobots/wiki
协作空间:https://collab.cels.anl.gov/display/ARGOBOTS/Argobots+Home#page-metadata-end
PDF:https://www.mcs.anl.gov/papers/P5515-0116.pdf
开发文档:ARGOBOTS: Modules
AReviewofLightweightThreadApproachesforHighPerformance
简略
Argobots 支持两种 工作单元:用户级线程(ULT,也称为协程)和小任务( tasklet)。
ULT 有一个与之关联的堆栈,而 tasklet 则没有。 Tasklet 允许快速的上下文切换,但不允许阻塞(lcx:也就是一旦执行,必须执行完)。 ULT 允许这样的阻塞,并且只比 tasklet 慢一点。
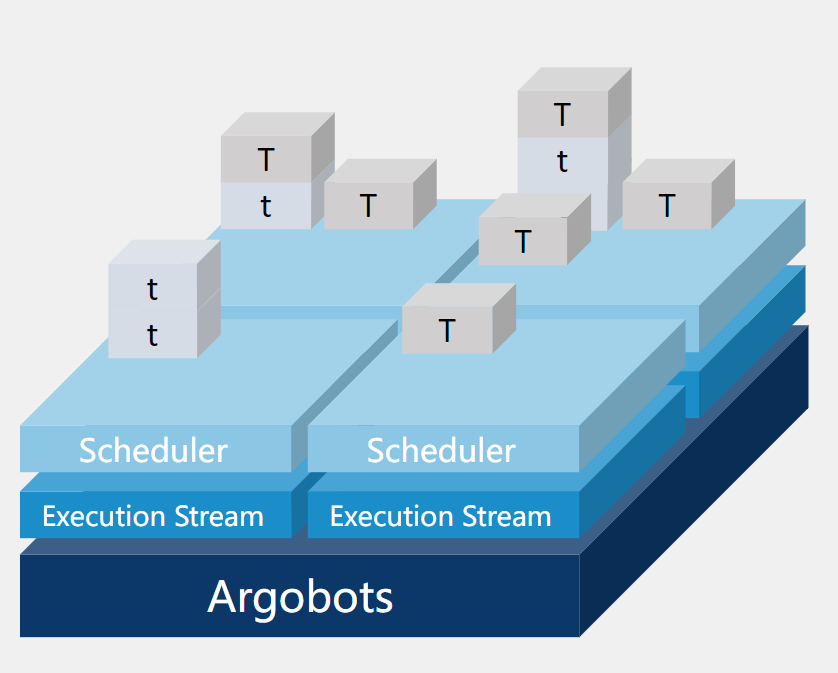
Argobots 的执行单元是xstream (就是一个物理线程)
工作原理是:
创建n个xstream (n个线程)和n个pool,然后用你的处理函数fun创建ULT,放到pool里面。 xstream就会不断的从绑定的pool里面拿出ULT来执行fun。
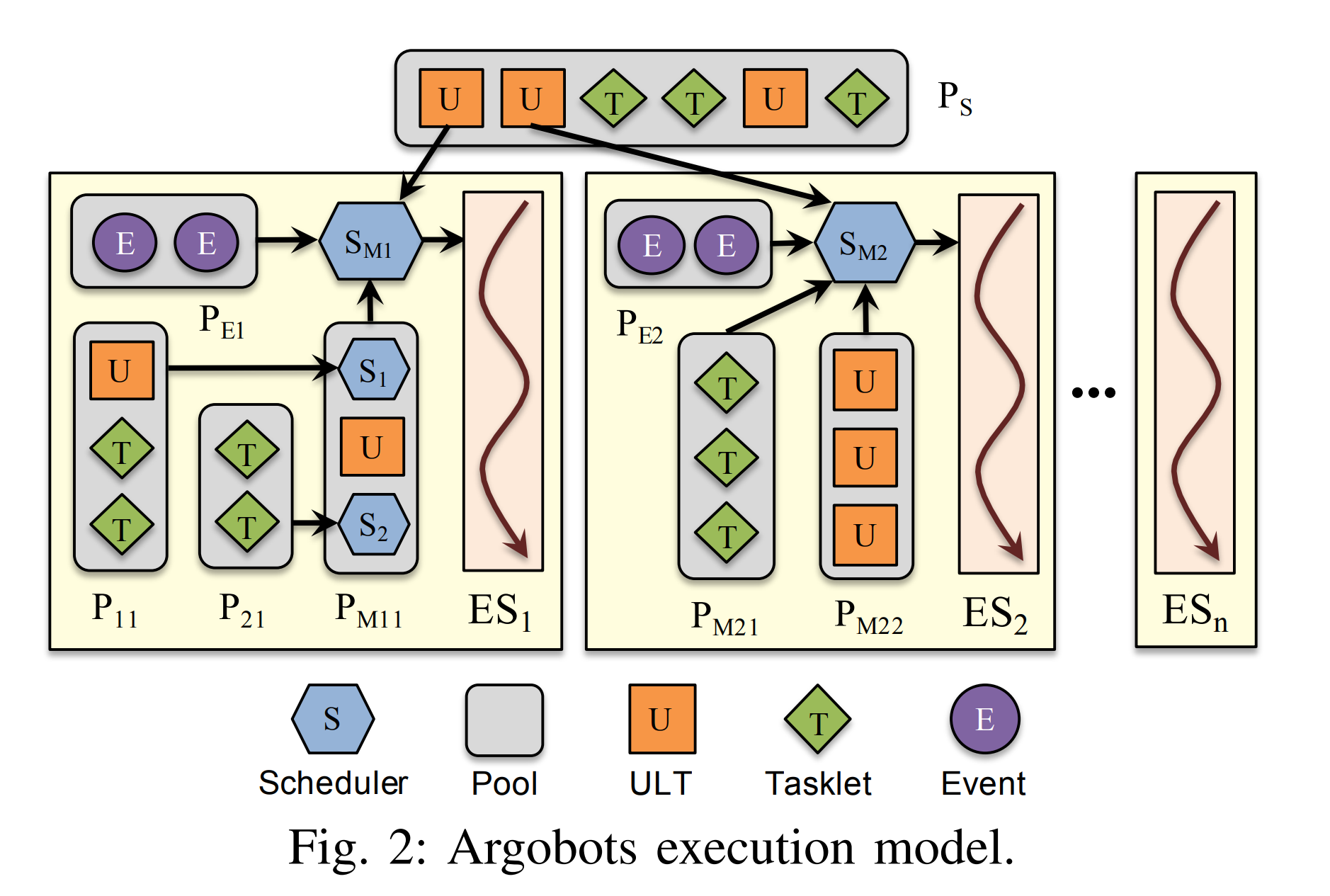
例子:
DAOS 服务器不依赖生成 pthread 来并发处理 I/O。相反,它为每个传入的 I/O 请求创建一个 Argobots [6] 用户级线程 (ULT)。 Argobots ULT 是与执行流 (xstream) 相关联的轻量级执行单元,它映射到 DAOS 服务的 pthread。这意味着来自任何 ULT 的传统 POSIX I/O 函数调用、pthread 锁或同步消息等待调用可能会阻塞执行流上所有 ULT 的进度。但是,因为 DAOS 使用的所有构建块都提供了非阻塞用户空间接口,所以 DAOS I/O ULT 永远不会在系统调用上被阻塞。相反,如果 I/O 或网络请求仍在进行中,它可以主动放弃执行。 I/O ULT 最终将由负责从网络和 SPDK 轮询完成事件的系统 ULT 重新调度。 ULT 创建和上下文切换非常轻量级。基准测试表明,一个 xstream 每秒可以创建数百万个 ULT,并且每秒可以执行超过一千万个 ULT 上下文切换。因此它非常适合 DAOS 服务器端 I/O 处理,它应该支持微秒级 I/O 延迟(图 2)
概念简介
Argobots 一个轻量级的、底层的 线程和任务框架。支持 大规模的节点并行性。与其他线程模型不同, Argobots 为用户提供高效的线程和任务处理 机制,而不是政策,以便用户可以开发自己的 解决方案。为了实现这一目标,Argobots 支持两种 工作单元:用户级线程(ULT,携程?)和小任务。前者有一个 关联堆栈并允许阻塞调用,而后者则没有,但提供快速的上下文切换。 Argobots 也公开了 硬件资源(例如内核)作为执行流(ES)并 提供工作单元和 ES 之间的映射机制。Argobots 支持具有可插入队列策略的可堆叠调度程序的创新概念。(摘自:https://www.mcs.anl.gov/papers/P5515-0116.pdf)
Argobots: 一个轻量级的底层线程框架
Argobots 是一个轻量级的运行时系统,支持大规模并发的集成计算和数据移动。它将直接利用硬件和操作系统中的最底层结构:轻量级通知机制、数据移动引擎、内存映射和数据放置策略。Argobots 被众多工业和学术合作伙伴使用,例如英特尔、HDF 集团、RIKEN 和 BSC。Argobots 被选为《 2020 年研发 100 大奖的决赛选手》https://www.rdworldonline.com/finalists-for-2020-rd-100-awards-are-unveiled/。
轻量级线程和小任务(Lightweight Threads and Tasklets)
Argobots 实现了轻量级并行工作单元,例如轻量级线程或小任务,可以动态有效地适应来自应用程序和硬件资源的需求。根据功率、弹性、内存位置和功能有效地调度线程和小任务。线程和小任务由称为[执行流]的抽象执行实体执行。

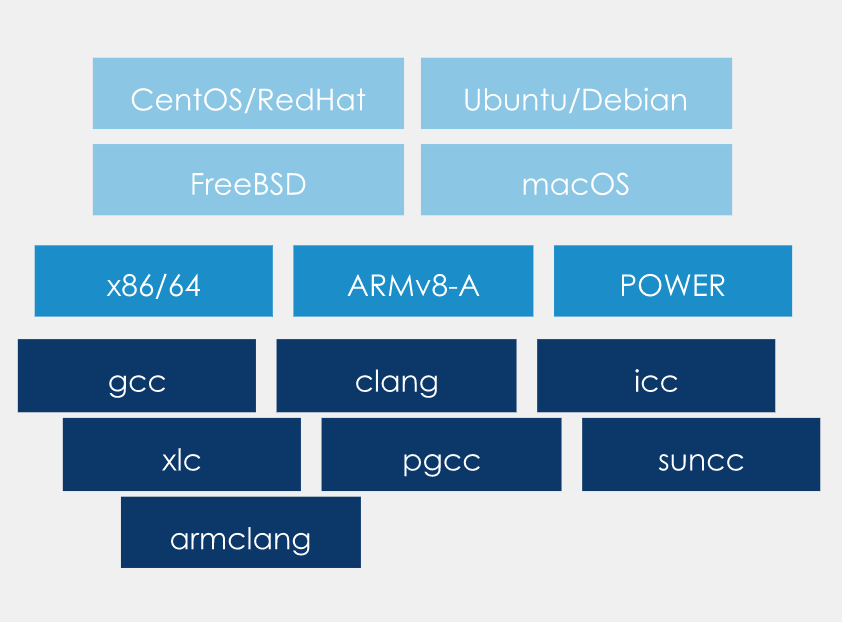
高可移植性(High Portability)
Argobots 适用于主要的基于 UNIX 的平台,包括 Ubuntu、FreeBSD、CentOS、macOS 和 Solaris。Argobots 支持大多数 CPU 架构,并针对 Intel/AMD x86/64、ARMv8-A 和 POWER 8 和 9 进行了特殊优化。我们定期使用众多 C 编译器测试 Argobots,包括 GCC、Clang、ICC (Intel)、XLC (IBM)、PGCC(PGI)、Solaris Studio (Oracle) 和用于 HPC (ARM) 的 Arm C 编译器。请在此处查看详细信息:Test Results |https://www.argobots.org/tests/
可定制的调度程序(Customizable Schedulers)
本地化调度策略,例如当前运行时系统中使用的那些,虽然对于短期执行很有效,但不知道全局策略和优先级。适应性和动态应用程序行为必须通过调度策略来处理,这些调度策略可以随时间变化或针对特定算法或数据结构进行定制。专用调度策略中的“Plugging”让 OS/R 处理机制并利用轻量级通知功能,同时将策略留给系统软件堆栈的更高级别。
Argobots 生态(Ecosystem of Argobots)

Argobots 一直在 Argo 项目内外扩展其生态系统。各种编程模型正在将 Argobots 集成到它们的运行时中,以便他们的应用程序可以在不修改代码的情况下利用 Argobots。
- Intel DAOS
- RIKEN OpenMP/XcalableMP
- OmpSs (BSC)
- Margo: Mercury over Argobots
- BOLT: OpenMP over Argobots
- Open MPI interoperation with Argobots
- MPICH interoperation with Argobots
- Charm++ over Argobots
- CilkBots over Argobots
- TASCEL over Argobots
- PaRSEC over Argobots
Argobots 的使用:helloword实例
/* -*- Mode: C; c-basic-offset:4 ; indent-tabs-mode:nil ; -*- */
/*
* See COPYRIGHT in top-level directory.
*//*
* Creates multiple execution streams and runs ULTs on these execution streams.
* Users can change the number of execution streams and the number of ULT via
* arguments. Each ULT prints its ID.
*/#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdarg.h>
#include <abt.h>#define DEFAULT_NUM_XSTREAMS 2
#define DEFAULT_NUM_THREADS 8typedef struct {
int tid;
} thread_arg_t;void hello_world(void *arg)
{
int tid = ((thread_arg_t *)arg)->tid;
printf("Hello world! (thread = %d)\n", tid);
}int main(int argc, char **argv)
{
int i;
/* Read arguments. */
int num_xstreams = DEFAULT_NUM_XSTREAMS;
int num_threads = DEFAULT_NUM_THREADS;
while (1) {
int opt = getopt(argc, argv, "he:n:");
if (opt == -1)
break;
switch (opt) {
case 'e':
num_xstreams = atoi(optarg);
break;
case 'n':
num_threads = atoi(optarg);
break;
case 'h':
default:
printf("Usage: ./hello_world [-e NUM_XSTREAMS] "
"[-n NUM_THREADS]\n");
return -1;
}
}
if (num_xstreams <= 0)
num_xstreams = 1;
if (num_threads <= 0)
num_threads = 1;/* Allocate memory. */
ABT_xstream *xstreams =
(ABT_xstream *)malloc(sizeof(ABT_xstream) * num_xstreams);
#每个xstream一个poolABT_pool *pools = (ABT_pool *)malloc(sizeof(ABT_pool) * num_xstreams);
ABT_thread *threads =
(ABT_thread *)malloc(sizeof(ABT_thread) * num_threads);
thread_arg_t *thread_args =
(thread_arg_t *)malloc(sizeof(thread_arg_t) * num_threads);
/* Initialize Argobots. */
ABT_init(argc, argv);/* Get a primary execution stream. */
ABT_xstream_self(&xstreams[0]);/* Create secondary execution streams. */
for (i = 1; i < num_xstreams; i++) {
ABT_xstream_create(ABT_SCHED_NULL, &xstreams[i]);
}/* Get default pools. */#为每个xstream指定一个pool
for (i = 0; i < num_xstreams; i++) {
ABT_xstream_get_main_pools(xstreams[i], 1, &pools[i]);
}/* Create ULTs. */#创建ULT,并放到一个pool中
for (i = 0; i < num_threads; i++) {
int pool_id = i % num_xstreams;
thread_args[i].tid = i;
ABT_thread_create(pools[pool_id], hello_world, &thread_args[i],
ABT_THREAD_ATTR_NULL, &threads[i]);
}/* Join and free ULTs. */
for (i = 0; i < num_threads; i++) {
ABT_thread_free(&threads[i]);
}/* Join and free secondary execution streams. */
for (i = 1; i < num_xstreams; i++) {
ABT_xstream_join(xstreams[i]);
ABT_xstream_free(&xstreams[i]);
}/* Finalize Argobots. */
ABT_finalize();/* Free allocated memory. */
free(xstreams);
free(pools);
free(threads);
free(thread_args);return 0;
}
Argobots 简介PPT
https://download.csdn.net/download/bandaoyu/88386581
Argobots 源码学习 - 创建 ES 流
ABT_xstream_create 函数流程梳理。在初始化时,会有一个列表全部存放 ES 流,这里会循环调用,给列表中逐个创建 ES 流。 ABT_xstream_create 创建新的执行流, 并通过 newxstream 返回其句柄。如果 sched 为 ABT_SED_NULL,则使用具有基本 FIFO 队列和默认调度器配置的默认调度器。 如果 sched 不是 ABT_SED_NULL,则用户不能复用调度来创建另一个执行流。如果 sched 未配置为自动释放,则用户有责任在释放 newxstream 后释放 sched。newxstream 在使用后必须由 ABT_xstream_free () 释放。
创建调度器 ABTI_sched_create_basic
如果传入的 sched 为 NULL 这里会创建一个默认(ABT_SCHED_DEFAULT)的调度器。
创建 ES 流 xstream_create
根据全局设置 p_global 和上一步创建的调度器 p_sched 来创建一个 ABTI_XSTREAM_TYPE_SECONDARY 类型的 ES。
申请内存
存放结构 p_newxstream,这个结构会被插入到链表中。
设置 ES 等级 xstream_set_new_rank
这里传入的 rank 为 - 1。设置等级的操作需要给 p_global->xstream_list_lock 加锁。 如果 rank 等于 - 1,会从 0 开始寻找一个没用过的 rank。寻找的过程就是双向链表的遍历。

设置运行状态
设置 ES 的 type,设置 ES 的 state 为 ABT_XSTREAM_STATE_RUNNING。
初始化本地内存 ABTI_mem_init_local
分别初始化 ES 流的 mem_pool_stack 和 mem_pool_desc,调用函数 ABTI_mem_pool_init_local_pool。ABTI_mem_pool_take_bucket 会从全局的内存池中分一个桶。
初始化主调度器 xstream_init_main_sched
- 将调度器设置为主调度器:used = ABTI_SCHED_MAIN
- 将 ES 的调度器设置为这个调度器:p_main_sched = p_sched
创建根线程 ABTI_ythread_create_root
本文的主要贡献如下。 • Argobots 执行模型设计通过在通用框架中利用最先进的概念和优化,为更高级别的运行时和编程模型提供了极高的灵活性和控制。这种灵活性允许用户将高级抽象转换为有效的低级实现。 • 如果没有有效实施,轻量级设计可能会很重。我们进行了深入分析,包括调查关键路径中发生的每个缓存未命中和 TLB 未命中。这导致了实现优化和 API 在轻量级运行时环境中实现了前所未有的性能的扩展。 • 我们使用 36 核机器评估 Argobots 我 crobenchmarks 并比较它的性能和可扩展性 与其他轻量级线程库一样,例如 Qthreads [3] 和 MassiveThreads [4]。该评估表明,Argobots 在实现可持续性能的同时,比其他库产生的开销小且可扩展性更好。 • 我们对三个应用程序进行性能研究。 结果表明,Argobots 版本的性能优于原始应用程序,因为 Argobots 凭借其轻量级机制实现了更高效的实施。
ULT,也称为协程或纤程,通常被称为具有低上下文切换开销的轻量级线程。 ULT 的线程语义类似于操作系统级线程的语义,但在用户空间中运行。 此外,可以将多个 ULT 映射到单个操作系统级线程。 因此,ULT可能不会同时执行,并且可能需要协作调度以便以交错方式执行多个ULT。 与传统线程(例如 Pthreads)相比,ULT 更适合表达大规模并行性以及重叠计算和通信(或 I/O)
因为它们的轻量级上下文机制。
To leverage these benefits of ULTs, researchers have proposed various threading models, as well as OS supports such as Windows fibers [5], [6] or Solaris threads [7]. Converse threads [8] are designed for the Converse framework [9] as a threading subsystem and support both ULTs and tasklets, incorporating a hierarchical scheduling model. Argobots is highly motivated by the Converse threads, but it delivers more flexible and deterministic threading and tasking primitives by allowing users to control every detail of Argobots. Qthreads [3] provides a large number of ULTs with full-/empty-bit semantics; a ULT can wait for any word of memory until it is marked either full or empty. MassiveThreads [4] is a lightweight thread library focusing on scheduling recursive task parallelism. Maestro [10] provides lightweight threads and synchronization operations, but it is designed to be the target of a high-level language compiler or source-to-source translator. Nanos++ runtime [11] provides ULTs that are used
to implement task parallelism in OmpSs [12]. GnuPth [13] supports ULTs on a single kernel-space thread while focusing on portability. StackThreads [14] provides multithreads only within a single processor; StackThreads/MP [15] extends this capability by supporting dynamic thread migration on shared-memory multiprocessors. Marcel [16] is enhanced with hierarchical scheduling of ULTs on NUMA machines. On the other hand, Stackless Python [17] and Protothreads [18] are more focused on stackless threads, that is, tasklets.
为了利用 ULT 的这些优势,研究人员提出了各种线程模型,以及操作系统支持,例如 Windows 光纤 [5]、[6] 或 Solaris 线程 [7]。 Converse 线程 [8] 是为 Converse 框架 [9] 设计的线程子系统,并支持 ULT 和 tasklet,并结合了分层调度模型。 Argobots 受到 Converse 线程的高度激励,但它通过允许用户控制 Argobots 的每个细节来提供更灵活和确定性的线程和任务原语。 Qthreads [3] 提供了大量具有全/空位语义的 ULT; ULT 可以等待任何内存字,直到它被标记为满或空。 MassiveThreads [4] 是一个专注于调度递归任务并行性的轻量级线程库。 Maestro [10] 提供轻量级线程和同步操作,但它被设计为高级语言编译器或源到源翻译器的目标。 Nanos++ 运行时 [11] 提供了使用的 ULT
在 OmpSs [12] 中实现任务并行性。 GnuPth [13] 在单个内核空间线程上支持 ULT,同时专注于可移植性。 StackThreads [14] 仅在单个处理器内提供多线程; StackThreads/MP [15] 通过支持共享内存多处理器上的动态线程迁移扩展了这种能力。 Marcel [16] 通过 NUMA 机器上的 ULT 分层调度得到了增强。另一方面,Stackless Python [17] 和 Protothreads [18] 更专注于无堆栈线程,即 tasklet。
Lightweight threads have also been utilized for special purposes, especially for hiding I/O or communication latency. Capriccio [19] is a ULT package for high-concurrency servers, such as the Apache web server; however, it supports multiple ULTs only in single-threaded applications, not in a multithreaded environment. StateThreads [20] provides a threading API for writing Internet applications, such as web servers or proxy servers, with an event-driven state machine architecture. Li and Zdancewic [21] combined the lightweight threading model and the event-driven model to build massively concurrent network services. MPC [22] exploits ULTs to deal with communications and synchronizations. TiNy-threads [23] is specialized to map lightweight software to hardware thread units in the Cyclops64 cellular architecture. Scheduler activations [24] and dispatchers in K42 [25] are similar to ESs in that they virtualize hardware resources and ULTs are mapped to them when executed. However, their goal is to avoid blocking in a scheduler activation (or dispatcher) by creating a new scheduler activation and switching to it by preemption in order to execute a different ULT. They provide kernel interfaces to ULT libraries for this. On the other hand, the Argobots ES does not interact with the OS kernel to avoid
blocking. Instead, it relies on cooperative multitasking between
ULTs (i.e., the ULT has to voluntarily yield when it blocks). Therefore, the ideas presented in [24], [25] are orthogonal and complementary to our work.
轻量级线程也被用于特殊用途,特别是用于隐藏 I/O 或通信延迟。 Capriccio [19] 是一个用于高并发服务器的 ULT 包,例如 Apache Web 服务器;但是,它仅在单线程应用程序中支持多个 ULT,而不是在多线程环境中。 StateThreads [20] 提供了一个线程 API,用于编写具有事件驱动状态机架构的 Internet 应用程序,例如 Web 服务器或代理服务器。 Li 和 Zdancewic [21] 结合轻量级线程模型和事件驱动模型来构建大规模并发网络服务。 MPC [22] 利用 ULT 来处理通信和同步。 TiNy-threads [23] 专门用于将轻量级软件映射到 Cyclops64 蜂窝架构中的硬件线程单元。 K42 [25] 中的调度程序激活 [24] 和调度程序与 ES 相似,因为它们虚拟化硬件资源,并且 ULT 在执行时映射到它们。但是,他们的目标是通过创建新的调度程序激活并通过抢占切换到它以执行不同的 ULT 来避免阻塞调度程序激活(或调度程序)。为此,它们为 ULT 库提供内核接口。另一方面,Argobots ES 不与操作系统内核交互以避免
阻塞。相反,它依赖于
ULT(即 ULT 在阻塞时必须自愿让步)。因此,[24]、[25] 中提出的想法与我们的工作是正交的和互补的。
The main difference between Argobots and other approaches is that Argobots is designed primarily to be an under- lying hreading and tasking runtime for high-level runtimes or libraries. It rovides low-level primitives with which we can even build other ULT libraries, whereas current ULT libraries cannot do so or lose important features in the attempt. First, Argobots exposes two levels of parallelism, ESs and work units, that can give a better chance to optimize locality and to deterministically schedule work units. Arguably, explicitly mapping ESs and work units may present a burden to new users, but it can enable advanced users to better control the locality and the scheduling by precisely assigning work units to specific ESs. In addition, unlike other models, Argobots seeks to provide efficient mechanisms, not policies, for users to develop their own solutions. Argobots also supports lowerlevel control of scheduling and stackable
cheduling framework with pluggable strategies. Since this
pproach prevents Argobots from conflicting with upper-layer runtimes, it enhances the sustainability and stability of
erformance. We believe that all these efforts make Argobots a better fit for various high-level runtimes or domain-specific libraries.
Argobots 和其他方法的主要区别在于 Argobots 主要被设计为高级运行时或库的底层线程和任务运行时。它提供了低级原语,我们甚至可以使用这些原语构建其他 ULT 库,而当前的 ULT 库不能这样做或在尝试中丢失重要功能。首先,Argobots 公开了两个级别的并行性,ES 和工作单元,这可以提供更好的机会来优化局部性和确定性地调度工作单元。可以说,显式映射 ES 和工作单元可能会给新用户带来负担,但它可以使高级用户通过将工作单元精确分配给特定的 ES 来更好地控制局部性和调度。此外,与其他模型不同,Argobots 寻求为用户提供有效的机制,而不是策略,以开发自己的解决方案。 Argobots 还支持较低级别的调度和可堆叠控制
调度框架与可插拔策略一起工作。从此 方法防止 Argobots 与上层运行时发生冲突,它增强了程序的可持续性和稳定性 性能。我们相信所有这些努力使 Argobots 更适合各种高级运行时或特定领域的库。
In Section V we compare Argobots with popular Qthreads and MassiveThreads in terms of performance and scalability ecause they are among the best-performing lightweight threading models currently used in the HPC community.
Moreover, these are available as independent libraries that are not integrated in the programming model runtimes, and their performance was well studied in previous works [3], [4]
在第五节中,我们将 Argobots 与流行的 Qthreads 和 MassiveThreads 在性能和可扩展性方面进行比较,因为它们是目前 HPC 社区中使用的性能最佳的轻量级线程模型之一。
此外,这些可作为未集成在编程模型运行时中的独立库提供,并且它们的性能在以前的工作中得到了很好的研究 [3]、[4]
……
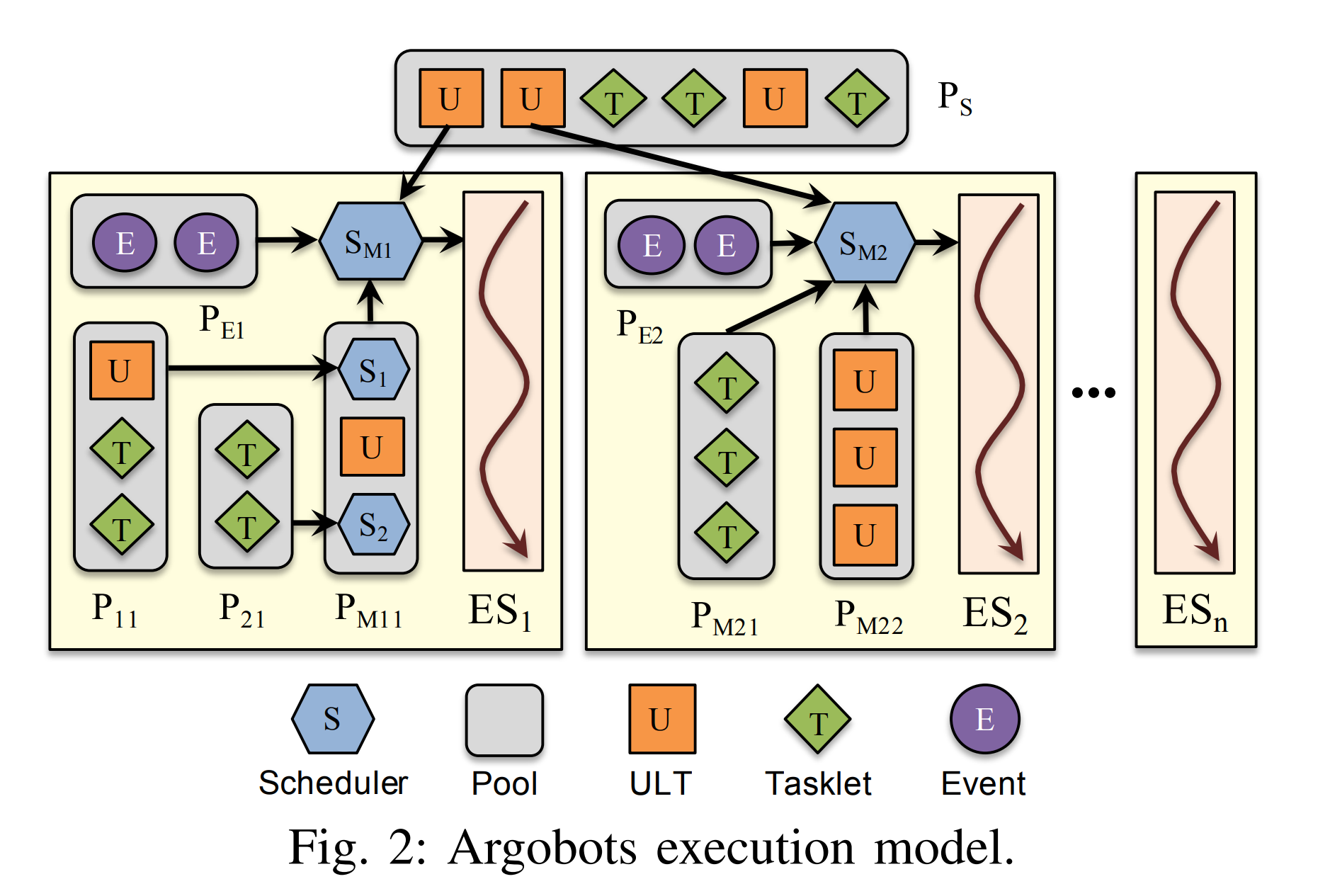
Figure 2 illustrates the execution model of Argobots. Argobots explicitly supports two levels of parallelism: ESs andwork units. An ES is a sequential instruction stream that consists of one or more work units. When an ES is bound to a hardware processing element (PE), it can also be regarded as a software-equivalent or OS-level thread. ESs are explicitly created, and each ES is executed independently. ESs have implicitly managed progress semantics, which guarantees that one blocked ES cannot block other ESs. A work unit is a lightweight execution unit, such as a ULT or tasklet, and gets associated with a specific ES when it is running. There is no concurrent execution of work units in a single ES, and thus only one work unit runs in an ES at a certain point. However, work units in different ESs can be executed concurrently. Each ES is associated with its own scheduler that is in charge of scheduling work units according to its scheduling policy.
The scheduler also handles asynchronous events periodically. Argobots provides some basic schedulers, and users can also write their own scheduler
执行模型
图 2 说明了 Argobots 的执行模型。 Argobots明确支持两个级别的并行性:ES 和工作单元。 ES 是由一个或多个工作单元组成的顺序指令流。当一个 ES 绑定到一个硬件处理元素(PE)上时,它也可以被视为一个软件等效或 OS 级线程。 ES 是显式创建的,每个 ES 都是独立执行的。 ES 具有隐式管理的进度语义,这保证了一个被阻塞的 ES 不能阻塞其他 ES。工作单元是轻量级的执行单元,例如 ULT 或 tasklet,并在运行时与特定的 ES 相关联。单个 ES 中没有工作单元的并发执行,因此在某个时刻只有一个工作单元在 ES 中运行。但是,不同 ES 中的工作单元可以同时执行。<---(协程的特性)每个 ES 都与自己的调度器相关联,该调度器负责根据其调度策略调度工作单元。
调度程序还定期处理异步事件。 Argobots 提供了一些基本的调度器,用户也可以自己编写调度器。
ULTs and tasklets are associated with function calls and execute to completion. However, they differ in subtle aspects that make each of them better suited for some programming motifs. For example, a ULT has its own persistent stack region, whereas a tasklet borrows the stack of its host ES’s scheduler. A ULT is an independent execution unit in user space and provides standard
hread semantics at a low contextswitching cost. ULTs are suitable for expressing parallelism in terms of persistent contexts whose flow of control pauses and resumes based on the flow of data. A common example is an overdecomposed application that uses blocking receives to wait for remote data. Unlike OS-level threads, ULTs are not intended to be preempted. They cooperatively yield control, for example, when they wait for remote data or just let other work units make progress. When ULTs run in an ES, their execution may be interleaved inside an ES because they can yield control to the scheduler or another ULT. A tasklet is an indivisible unit of work with dependence only on its input data, and it typically provides output data upon completion.
Tasklets do not explicitly yield control but run to completion before returning control to the scheduler that invoked them.
ULT 和 tasklet 与函数调用相关联并执行完成。但是,它们在细微的方面有所不同,这使得它们中的每一个都更适合某些编程主题。例如,ULT 有自己的持久堆栈区域,而 tasklet 借用其主机 ES 调度程序的堆栈。 ULT 是用户空间中的一个独立执行单元,提供标准以较低的上下文切换成本读取语义。 ULT 适用于根据持久上下文来表达并行性,其控制流根据数据流暂停和恢复。一个常见的例子是一个过度分解的应用程序,它使用阻塞接收来等待远程数据。与操作系统级别的线程不同,ULT 不打算被抢占。例如,当他们等待远程数据或只是让其他工作单位取得进展时,他们会合作让出控制权。当 ULT 在 ES 中运行时,它们的执行可能会在 ES 内交错执行,因为它们可以将控制权交给调度程序或另一个 ULT。 tasklet 是一个不可分割的工作单元,仅依赖于其输入数据,通常在完成后提供输出数据。
Tasklet 不会显式地让出控制权,而是在将控制权返回给调用它们的调度程序之前运行完成。
The explicit management of ESs and work units differentiates Argobots from other ULT libraries [3], [4], [10]. Instead of merely relying on the underlying scheduler of a thread library, users of Argobots can control which work units can run concurrently by managing the mapping between ESs and work units. This low-level control enhances cooperative multitasking because work units that involve much communication and need frequent context switch can be mapped together to ESs.
In addition, work units that are compute bound and do not benefit from cooperative multitasking can run in an ES without frequent context switching. Moreover, this approach enables users to easily manage the data locality of work units.
ES 和工作单元的显式管理将 Argobots 与其他 ULT 库 [3]、[4]、[10] 区分开来。 Argobots 的用户不仅仅依赖于线程库的底层调度程序,还可以通过管理 ES 和工作单元之间的映射来控制哪些工作单元可以并发运行。 这种底层控制增强了协作多任务处理,因为涉及大量通信并需要频繁上下文切换的工作单元可以一起映射到 ES。
此外,计算受限且无法从协作多任务中受益的工作单元可以在 ES 中运行,而无需频繁的上下文切换。 此外,这种方法使用户能够轻松管理工作单元的数据局部性。
调度
The design principle for the scheduler is to provide a
framework for stackable or nested schedulers with pluggable strategies while exploiting the cooperative, nonpreemptive activation of work units. Localized scheduling strategies such as those used in current runtime systems, while efficient for short execution, are unaware of global strategies and priorities. daptability and dynamic system behavior must be handled by scheduling strategies that can change over time or be customized for a particular algorithm or data structure. Argobots supports plugging in custom strategies so that higher levels of the software stack can use their special policies while Argobots handles the low-level scheduling mechanism.
调度器的设计原则是提供一个具有可插拔策略的可堆叠或嵌套调度程序框架,同时利用工作单元的协作、非抢占式激活。 本地化调度策略,例如当前运行时系统中使用的那些,虽然对于短期执行很有效,但不知道全局策略和优先级。 适应性和动态系统行为必须通过调度策略来处理,这些调度策略可以随时间变化或针对特定算法或数据结构进行定制。 Argobots 支持插入自定义策略,以便更高级别的软件堆栈可以使用其特殊策略,而 Argobots 处理低级调度机制。
……
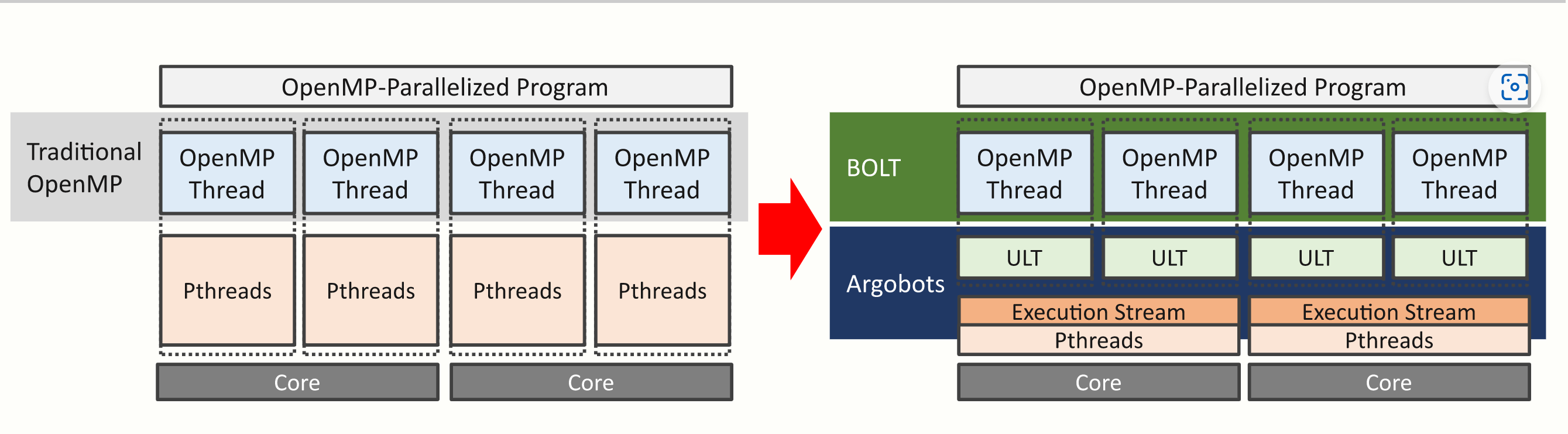
BOLT | OpenMP over Lightweight Threads (bolt-omp.org)
















 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









