







目录
编码
ASCII 1个字节=1个文字
ANSI 2个字节=1个文字
UNICODE 3个+字节=1个文字 -----压缩---->UTF-8
mysql中文编码乱码问题
“使用命令行方式登陆到MySQL服务器, 建立一个数据库,数据库编码设为UTF-8。此时,如果直接在命令行窗口使用insert语句插入中文,就遇到类似 ERROR 1406 (22001): Data too long for column 'name' at row 1 错误。乍一看,是字段长度引起的问题,但是实际是字符编码的问题。可是尝试以下解决方法:
1、在Linux中,使用终端方式登陆MySQL服务器,运行以下命令:
set names utf8;
该命令将终端的字符编码设为了UTF-8。此后再插入数据库中的内容都会按照UTF-8的编码来处理。
注意:在Linux中,终端方式中直接插入中文内容,可能并不会出现1406错误,但是这时插入的 数据
是按照系统的默认编码进行处理。因此对编码为UTF-8的数据库,在显示数据的地方可能会出现乱码。
2、在Windows下,命令行窗口不支持UTF-8编码,所以使用“set names utf8;”不会达到转化中文的
效果。但是这个问题还是可以解决的:
(1)使用默认编码建立数据库。这种情况下就可以直接输入中文了,但是相应的问题,就是会
失去UTF-8编码的灵活性。特别是不利于软件的国际化。
(2)放弃命令行窗口登录MySQL,使用图形化客户端。客户端工具可以MySQL的官方网站上找到。”
B. Mysql配置文件:
“在my.ini里找到sql- mode='STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'把其中 的STRICT_TRANS_TABLES,去掉,或者把sql- mode=STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION注释掉,然 后重启mysql就ok了
java中文转码
案例1:对端的中文编码是Unicode,传输到本端的buffer。
本端nistr= buffer.to_string () 则nistr就是"abc\u5639\u563b";
本端nibyte[]= buffer.getBytes("unicode") 则nibyte[0]、nibyte[1]……就是buffer字节流的第一、二个字节的值
将字符串转成unicode编码形式的字节数组类型
string message="你好123";
byte[] b_msg = message.getBytes("unicode");// 字符串使用unicode编码转换成字节
//b_msg数组为转换后的字节数组
在Unicode和UTF-8之间转换
方法1
try
{
// Convert from Unicode to UTF-8
String string = "abc\u5639\u563b";
byte[] utf8 = string.getBytes("UTF-8");
// Convert from UTF-8 to Unicode
string = new String(utf8, "UTF-8");
}
catch (UnsupportedEncodingException e)
{
}方法2
public static String unicodeToUtf8(String theString)
{
char aChar;
int len = theString.length();
StringBuffer outBuffer = new StringBuffer(len);
for (int x = 0; x < len;)
{
aChar = theString.charAt(x++);
if (aChar == '\\')
{
aChar = theString.charAt(x++);
if (aChar == 'u')
{
// Read the xxxx
int value = 0;
for (int i = 0; i < 4; i++)
{
aChar = theString.charAt(x++);
switch (aChar)
{
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
value = (value << 4) + aChar - '0';
break;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
value = (value << 4) + 10 + aChar - 'a';
break;
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
value = (value << 4) + 10 + aChar - 'A';
break;
default:
throw new IllegalArgumentException(
"Malformed \\uxxxx encoding.");
}
}
outBuffer.append((char) value);
}
else
{
if (aChar == 't')
aChar = '\t';
else if (aChar == 'r')
aChar = '\r';
else if (aChar == 'n')
aChar = '\n';
else if (aChar == 'f')
aChar = '\f';
outBuffer.append(aChar);
}
}
else
outBuffer.append(aChar);
}
return outBuffer.toString();
}utf-8转unicode
public static String utf8ToUnicode(String inStr)
{
char[] myBuffer = inStr.toCharArray();
StringBuffer sb = new StringBuffer();
for (int i = 0; i < inStr.length(); i++)
{
UnicodeBlock ub = UnicodeBlock.of(myBuffer[i]);
if(ub == UnicodeBlock.BASIC_LATIN)
{
//英文及数字等
sb.append(myBuffer[i]);
}
else if(ub == UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS)
{
//全角半角字符
int j = (int) myBuffer[i] - 65248;
sb.append((char)j);
}
else
{
//汉字
short s = (short) myBuffer[i];
String hexS = Integer.toHexString(s);
String unicode = "\\u" + hexS;
sb.append(unicode.toLowerCase());
}
}
return sb.toString();
}其他方法:https://blog.csdn.net/weixin_45358267/article/details/116532896
getByte()用法小结
在Java中,String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组。这个表示在不同情况下,返回的东西不一样!
String.getBytes(String decode)方法会根据指定的decode编码返回某字符串在该编码下的byte数组表示,如:
Java代码

- byte[] b_gbk = "深".getBytes("GBK");
- byte[] b_utf8 = "深".getBytes("UTF-8");
- byte[] b_iso88591 = "深".getBytes("ISO8859-1");
- byte[] b_unicode = "深".getBytes("unicode");
将分别返回“深”这个汉字在GBK、UTF-8、ISO8859-1和unicode编码下的byte数组表示,此时b_gbk的长度为2,b_utf8的长度为3,b_iso88591的长度为1,unicode为4。
而与getBytes相对的,可以通过new String(byte[], decode)的方式来还原这个“深”字时,这个new String(byte[], decode)实际是使用decode指定的编码来将byte[]解析成字符串。
Java代码

- String s_gbk = new String(b_gbk,"GBK");
- String s_utf8 = new String(b_utf8,"UTF-8");
- String s_iso88591 = new String(b_iso88591,"ISO8859-1");
- String s_unicode = new String(b_unicode, "unicode");
通过打印s_gbk、s_utf8、s_iso88591和unicode,会发现,s_gbk、s_utf8和unicode都是“深”,而只有s_iso88591是一个不认识的字符,为什么使用ISO8859-1编码再组合之后,无法还原“深”字呢,其实原因很简单,因为ISO8859-1编码的编码表中,根本就没有包含汉字字符,当然也就无法通过"深".getBytes("ISO8859-1");来得到正确的“深”字在ISO8859-1中的编码值了,所以再通过new String()来还原就无从谈起了。
因此,通过String.getBytes(String decode)方法来得到byte[]时,一定要确定decode的编码表中确实存在String表示的码值,这样得到的byte[]数组才能正确被还原。
有时候,为了让中文字符适应某些特殊要求(如http header头要求其内容必须为iso8859-1编码),可能会通过将中文字符按照字节方式来编码的情况,如
String s_iso88591 = new String("深".getBytes("UTF-8"),"ISO8859-1"),
这样得到的s_iso8859-1字符串实际是三个在 ISO8859-1中的字符,在将这些字符传递到目的地后,目的地程序再通过相反的方式String s_utf8 = new String(s_iso88591.getBytes("ISO8859-1"),"UTF-8")来得到正确的中文汉字“深”。这样就既保证了遵守协议规定、也支持中文。
同样,在开发会检查字符长度,以免数据库字段的长度不够而报错,考虑到中英文的差异,肯定不能用String.length()方法判断,而需采用String.getBytes().length;而本方法将返回该操作系统默认的编码格式的字节数组。如字符串“Hello!你好!”,在一个中文WindowsXP系统下,结果为12,而在英文的UNIX环境下,结果将为9。因为该方法和平台(编码)相关的。在中文操作系统中,getBytes方法返回的是一个GBK或者GB2312的中文编码的字节数组,其中中文字符,各占两个字节,而在英文平台中,一般的默认编码是"ISO-8859-1",每个字符都只取一个字节(而不管是否非拉丁字符)。所以在这种情况下,应该给其传入字符编码字符串,即String.getBytes("GBK").length。
getBytes()和toCharArray()
String类的:
byte[] getBytes()
返回的是字节数组,直接输出结果是地址值
char[] toCharArray()
返回的是字符数组,直接输出结果却是内容,因为字符数组是特殊的数组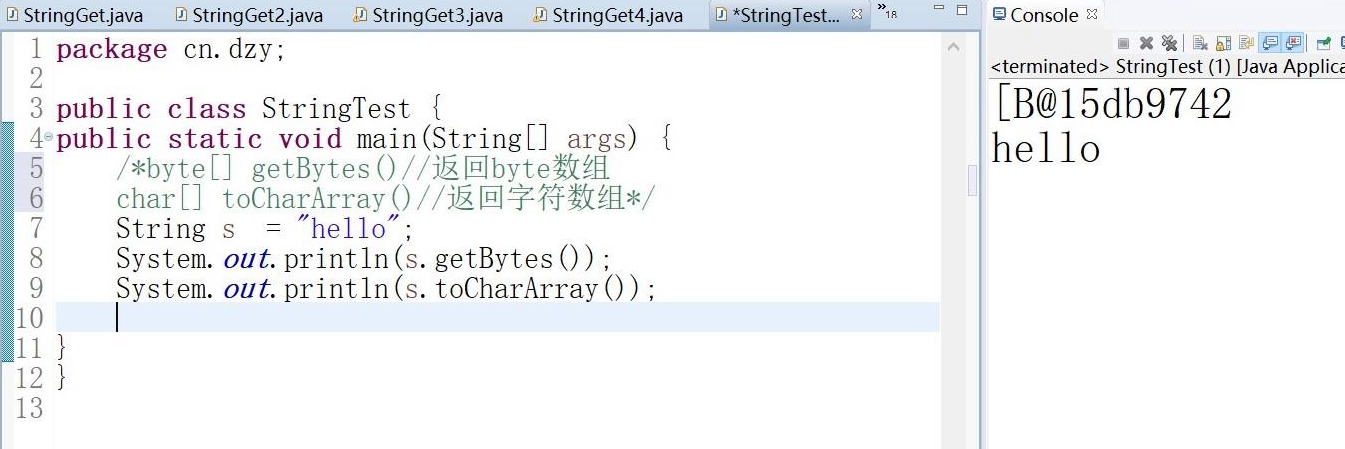
String myString=”abcd”;
byte myByte[]=myString.getBytes();
System.out.println(“myByte[1]=”+myByte[1]);
输出结果:
myByte[1]=98
返回myByte[] 就是地址值,myByte[1]是第二个地址值指向的数值=98
IDEA中文乱码解决方法
PYTHON中文编码问题(字符串前加‘U‘|DECODE|ENCODE)
字符串在Python3内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表示将unicode编码的字符串str2转换成gb2312编码。
总得意思:想要将其他的编码转换成utf-8必须先将其解码成unicode然后重新编码成utf-8,它是以unicode为转换媒介的 如:s=‘中文’ 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用 decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件
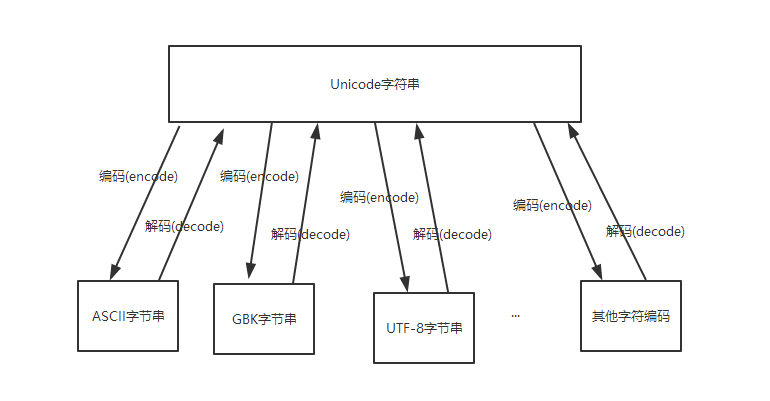
中文编码问题是用中文的程序员经常头大的问题,在python下也是如此,那么应该怎么理解和解决python的编码问题呢?
我们要知道python内部使用的是unicode编码,而外部却要面对千奇百怪的各种编码,比如作为中国程序经常要面对的gbk,gb2312,utf8等,那这些编码是怎么转换成内部的unicode呢?
首先我们先看一下源代码文件中使用字符串的情况。源代码文件作为文本文件就必然是以某种编码形式存储代码的,python2默认会认为源代码文件是asci编码,比如说代码中有一个变量赋值:
s1=’a’
print s1
python2认为这个’a’就是一个asci编码的字符。在仅仅使用英文字符的情况下一切正常,但是如果用了中文,比如:
s1=’哈’
print s1
这个代码文件被执行时就会出错,就是编码出了问题。python默认将代码文件内容当作asci编码处理,但asci编码中不存在中文,因此抛出异常。
解决问题之道就是要让python知道文件中使用的是什么编码形式,对于中文,可以用的常见编码有utf-8,gbk和gb2312等。只需在代码文件的最前端添加如下:
# -*- coding: utf-8 -*-
这就是告知python我这个文件里的文本是用utf-8编码的,这样,python就会依照utf-8的编码形式解读其中的字符,然后转换成unicode编码内部处理使用。
不过,如果你在Windows控制台下运行此代码的话,虽然程序是执行了,但屏幕上打印出的却不是哈字。这是由于python编码与控制台编码的不一致造成的。Windows下控制台中的编码使用的是gbk,而在代码中使用的utf-8,python按照utf-8编码打印到gbk编码的控制台下自然就会不一致而不能打印出正确的汉字。
- 解决办法一个是将源代码的编码也改成gbk,也就是代码第一行改成:
# -*- coding: gbk -*-
-
另一种方法是保持源码文件的utf-8不变,而是在’哈’前面加个u字,也就是:
s1=u’哈’
print s1这样就可以正确打印出’哈’字了。
这里的这个u表示将后面跟的字符串以unicode格式存储。python会根据代码第一行标称的utf-8编码识别代码中的汉字’哈’,然后转换成unicode对象。如果我们用type查看一下’哈’的数据类型type(‘哈’),会得到<type ‘str’>,而type(u’哈’),则会得到<type ‘unicode’>,也就是在字符前面加u就表明这是一个unicode对象,这个字会以unicode格式存在于内存中,而如果不加u,表明这仅仅是一个使用某种编码的字符串,编码格式取决于python对源码文件编码的识别,这里就是utf-8。
Python在向控制台输出unicode对象的时候会自动根据输出环境的编码进行转换,但如果输出的不是unicode对象而是普通字符串,则会直接按照字符串的编码输出字符串,从而出现上面的现象。
-
使用unicode对象的话,除了这样使用u标记,还可以使用unicode类以及字符串的encode和decode方法。
unicode类的构造函数接受一个字符串参数和一个编码参数,将字符串封装为一个unicode,比如在这里,由于我们用的是utf-8编码,所以unicode中的编码参数使用’utf-8′将字符封装为unicode对象,然后正确输出到控制台:
s1=unicode(‘哈’, ‘utf-8′)
print s1另外,用decode函数也可以将一个普通字符串转换为unicode对象。很多人都搞不明白python字符串的decode和encode函数都是什么意思。这里简要说明一下。
decode是将普通字符串按照参数中的编码格式进行解析,然后生成对应的unicode对象,比如在这里我们代码用的是utf-8,那么把一个字符串转换为unicode就是如下形式:
s2=’哈’.decode(‘utf-8′)
这时,s2就是一个存储了’哈’字的unicode对象,其实就和unicode(‘哈’, ‘utf-8′)以及u’哈’是相同的。
那么encode正好就是相反的功能,是将一个unicode对象转换为参数中编码格式的普通字符,比如下面代码:
s3=unicode(‘哈’, ‘utf-8′).encode(‘utf-8′)
s3现在又变回了utf-8的’哈’。
# coding=utf-8
# 字符串在Python3内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,
# 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
a = u"中国"
print a
print a.decode('utf-8') # 报错:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
# coding=utf-8
a = u"中国"
b = "哈哈"
# decode中的参数coding必须是b原来的编码方式,
# b.decode('utf-8')就是对原来是utf-8编码的b解码为unicode编码。
print b.decode('utf-8')
print a.encode('utf-8')
# encode中的参数coding必须是a即将要编码的方式,
# a.encode('utf-8') 就是要对原来是unicode编码的a进行utf-8编码。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









