






代码链接
https://github.com/Birdy-C/Shakespeare-search-engine
预处理
word stemming
一个单词可能不同的形式,在英语中比如动词的主被动、单复数等。比如live\lives\lived.
虽然英文的处理看起来已经很复杂啦但实际在中文里的处理要更加复杂的多。
stop words
比如a、the这种词在处理的时候没有实际意义。在这里处理的时候先对词频进行统计,人为界定停词,简单的全部替换为空格。但是这种方式并不适用于所有的情况,对于比如,To be or not to be,这种就很难处理。
具体实现
Index.txt 记录所出现的文件
这里将建立倒排索引分为三步
thefile.txt 所有出现过的词(词频由高到低)
stop_word.txt 停词
data.pkl 所创建的索引
1 count.py 确定停词
2 index.py 建立倒排索引
3 query.py 用于查询
这里在建立倒排索引的时候只记录了出现的文件名,并没有记录在文件中出现的位置。
图为count.py生成的词频统计
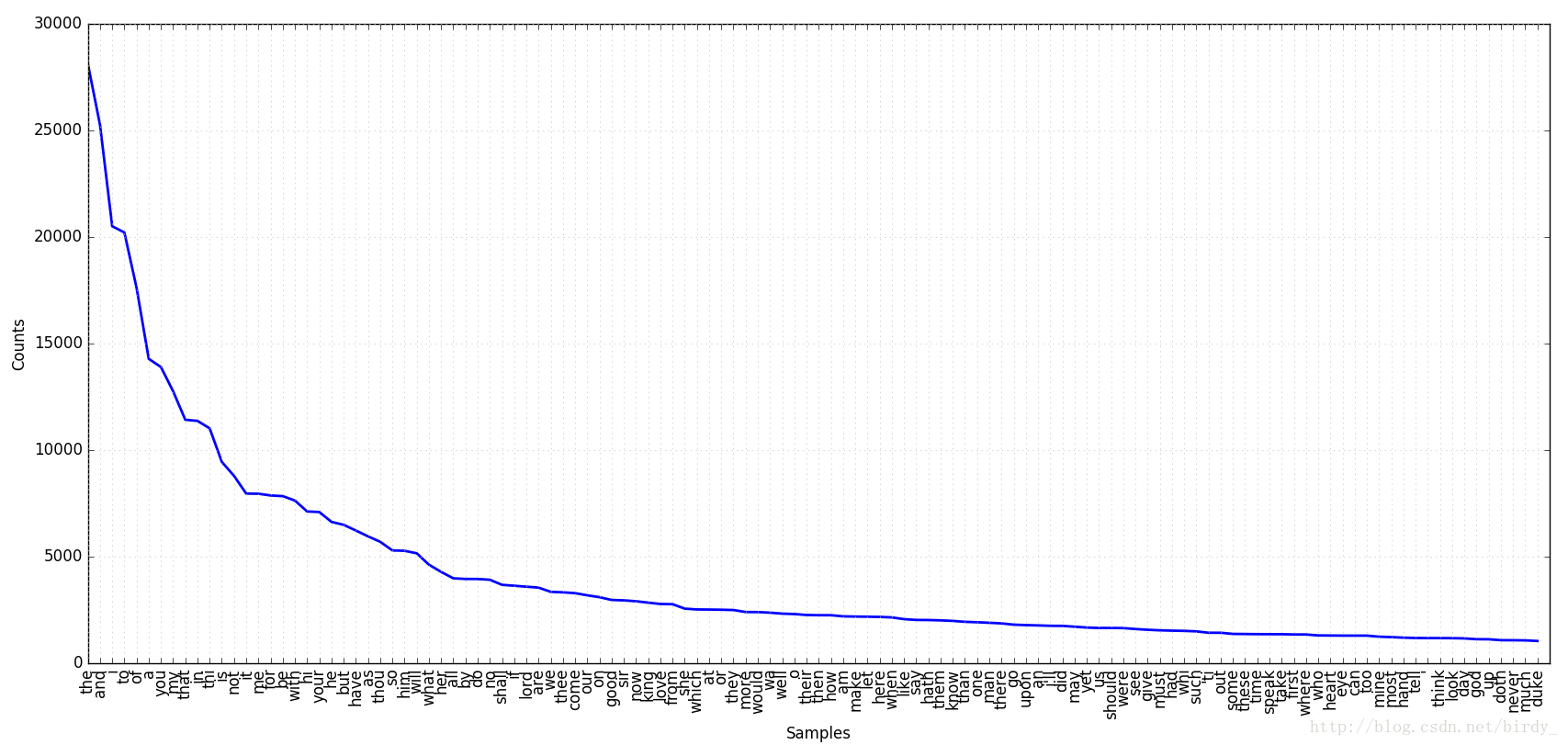
count.py
#-*- coding:utf-8 -*-
'''
@author birdy qian
'''
import sys
from nltk import * #import natural-language-toolkit
from operator import itemgetter #for sort
def output_count(fdist): #output the relative information
#vocabulary =fdist.items()
vocabulary =fdist.items() #get all the vocabulary
vocabulary=sorted(vocabulary, key=itemgetter(1),reverse=True) #sort the vocabulary in decreasing order
print vocabulary[:250] #print top 250 vocabulary and its count on the screen
print 'drawing plot.....' #show process
fdist.plot(120 , cumulative=False) #print the plot
#output in file
file_object = open('thefile.txt', 'w') #prepare the file for writing
for j in vocabulary:
file_object.write( j[0] + ' ') #put put all the vocabulary in decreasing order
file_object.close( ) #close the file
def pre_file(filename):
print("read file %s.txt....."%filename) #show process
content = open( str(filename) + '.txt', "r").read()
content = content.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~' : #cancel the punction
content = content.replace(ch, " ")
plurals = content.split() #split the file at '\n' or ' '
stemmer = PorterStemmer() #prepare for stemming
singles = [stemmer.stem(plural) for plural in plurals] #handling stemming
return singles
#main function
def main():
print "read index....." #show process
input = open('index.txt', 'r') #titles that need to be handled
all_the_file =input.read( )
file=all_the_file.split()
input.close() #close the file
fdist1=FreqDist() #create a new dist
for x in range( 0, len(file) ):
#print file[x]
txt = pre_file( file[x] ) #pre handing the txt
for words in txt :
words =words.decode('utf-8').encode(sys.getfilesystemencoding()) #change string typt from utf-8 to gbk
fdist1[words] +=1 #add it to the dist
output_count(fdist1)
#runfile
if __name__ == '__main__':
main() index.py
#-*- coding:utf-8 -*-
'''
@author birdy qian
'''
import sys
import pickle
from nltk import * #import natural-language-toolkit
from operator import itemgetter #for sort
STOPWORDS = [] #grobal variable
def output_index(result):
#print result
output = open('data.pkl', 'wb')
pickle.dump(result, output) # Pickle dictionary using protocol 0
output.close()
def pre_file(filename):
global STOPWORDS
print("read file %s.txt....."%filename) #show process
content = open( str(filename) + '.txt', "r").read()
content = content.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_��{|}~' : #cancel the punction
content = content.replace(ch, " ")
for ch in STOPWORDS: #cancel the stopwords
content = content.replace(ch, " ")
plurals = content.split() #split the file at '\n' or ' '
stemmer = PorterStemmer() #prepare for stemming
singles = [stemmer.stem(plural) for plural in plurals] #handling stemming
return singles
def readfile(filename):
input = open(filename, 'r') #titles that need to be handled
all_the_file =input.read( )
words = all_the_file.split() #split the file at '\n' or ' '
input.close()
return words
#main function
def main():
global STOPWORDS
print "read index....." #show process
file=readfile('index.txt')
print "read stopwords....."
STOPWORDS = readfile('stop_word.txt')
print "create word list....."
word = list(readfile('thefile.txt')) #the file with all the words in all the books
result = {} #memorize the result
for x in range( 0, len(file) ):
#print file[x]
txt = pre_file( file[x] ) # file[x] is the title
txt = {}.fromkeys(txt).keys() #cancel the repeat word
#can also use text.set()
for words in txt :
words =words.decode('utf-8').encode(sys.getfilesystemencoding()) #change string typt from utf-8 to gbk
if result.get(words) == None : #if the word is not in the dictionary
result[words]=[file[x]]
else: #if the word is in the dictionary
t=result.get(words)
t.append(file[x])
result[words]=t
output_index(result)
#runfile
if __name__ == '__main__':
main()
query.py
#-*- coding:utf-8 -*-
'''
@author birdy qian
'''
import os
import sys
import pprint, pickle
from nltk import PorterStemmer
def readfile(filename):
input = open(filename, 'r') #titles that need to be handled
all_the_file =input.read( )
words = all_the_file.split() #split the file at '\n' or ' '
input.close() #close the data
return words
def getdata():
pkl_file = open('data.pkl', 'rb') #index is saved in the file 'data.pkl'
data1 = pickle.load(pkl_file) #change the type
#pprint.pprint(data1)
pkl_file.close() #close the file
return data1 #close the data
def output( result ):
#print result
if result == None: #if the words is not in the index (one word return None)
print None
return
if len(result) == 0 : #if the words is not in the index (more than one words return [] )
print None
return
if len(result) < 10 : #if the records is less than 10
print result
else: #if the records is more than 10
print 'get '+ str(len(result)) + ' records' #the record number
for i in range( 0 , len(result) / 10 +1):
print '10 records start from ' +str(i*10+1)
if 10 * i + 9 < len(result) : #print from 10 * i to 10 * i + 10
print result[ 10 * i : 10 * i + 10 ]
else: #print from 10 * i to end
print result[ 10 * i : len(result) ]
break
getstr = raw_input("Enter 'N' for next ten records & other input to quit : ")
if getstr != 'N':
break
#main function
def main():
data_list = getdata() #read data
STOPWORDS = readfile('stop_word.txt')
stemmer = PorterStemmer() #prepare for stemming
while True:
get_str = raw_input("Enter your query('\\'to quit): ")
if get_str == '\\' : #leave the loop
break
get_str = get_str.lower()
for ch in STOPWORDS: #cancel the stopwords
get_str = get_str.replace(ch, " ")
query_list=get_str.split() #split the file at '\n' or ' '
query_list = [stemmer.stem(plural) for plural in query_list] #handling stemming
while True:
if query_list != [] :
break
get_str = raw_input("Please enter more information: ")
get_str = get_str.lower()
for ch in STOPWORDS: #cancel the stopwords
get_str = get_str.replace(ch, " ")
query_list=get_str.split()
query_list = [stemmer.stem(plural) for plural in query_list] #handling stemming
result=[]
for k in range( 0 , len(query_list) ):
if k==0: #if the list has not been built
result = data_list.get( query_list[0] )
else: #if the list has been built
result = list( set(result).intersection(data_list.get( query_list[k] ) ) )
output( result )
#runfile
if __name__ == '__main__':
main() 














 5667
5667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









