









配套练习题 https://www.luogu.com.cn/problem/P3375
https://www.luogu.com.cn/problem/P3375
目录
配套练习题https://www.luogu.com.cn/problem/P3375
而是通过不断改变模式串的匹配位置来达到减小时间复杂度的目的。
算法引入
算法简介
KMP算法,是字符串匹配的经典算法。其名称的由来没有什么故事:仅仅是三位计算机科学家(D.E.Knuth,J.H.Morris和V.R.Pratt)的名字的首字母的组合。
该算法的精髓在于:
当失配时,不会直接归位重新匹配,
而是通过不断改变模式串的匹配位置来达到减小时间复杂度的目的。
至于如何移动,且听下回分解(bushi)
莽夫写法
要想学会KMP,就必须由浅入深,首先从暴力看起。
const int N=1e5+5;
char s[N],p[N];
int n,m;
vector<int> match(char *s,char *p){//返回所有匹配位置的首字符
int i=0,j=0;
vector<int>ans;
while(i<n){
if(s[i]==p[j]) i++,j++;
if(j==m) ans.push_back(i-j),i=i-j+1,j=0;
if(s[i]!=p[j]) i=i-j+1,j=0;
}
return ans;
}
signed main(){
scanf("%s\n%s",s,p);
n=strlen(s),m=strlen(p);
vector<int> ans=match(s,p);
for(int i=0,siz=ans.size();i<siz;i++){
printf("%d ",ans[i]);
}
}显然,上方的代码最差时间复杂度为O(n*m),而且这个时间复杂度非常好卡。
(举个例子,s=aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa,p=aaaaaaaaaaaaaaaaaaaaaab)
算法优化
一切的一切都要从一个样例说起:
注:在本文中,绿色(AC的颜色)表示合配,红色(WA的颜色)表示失配。 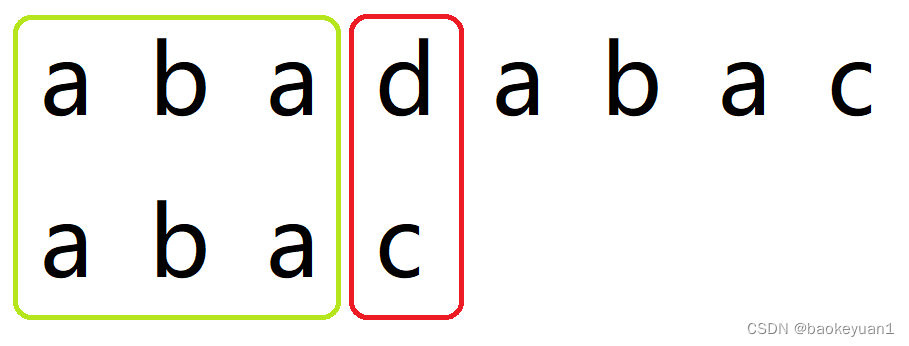
首先,s[0~2]=p[0~2],但是s[3]!=p[3]。如果是暴力的话,我们会直接把p向右移动一位(即暴力中的 i=i-j+1,j=0 )但是,这就违背了我们的宗旨:
当失配时,不会直接归位重新匹配,
而是通过不断改变模式串的匹配位置来达到减小时间复杂度的目的。
于是,我们就要把p往右移。
但是,我们要移动多少呢?
最长相同真前后缀
何为最长相同真前后缀?
1.真前缀or真后缀:非字符串本身的前缀or后缀
2.相同:完全一致
3.最长:长度最长
因此,其意思即为:长度最大的、完全相同的、非该字符串本身的前缀与后缀。
为了便于描述,对于字符串q,我们记 表示
的最长相同真前后缀。
所以,对于样例中的p=abac,则有。
为什么它能告诉我该移动几位呢?
首先,我们要实现 i 不往左移,那么,若与 i 匹配的是 j ,则必须要求满足s[i-j+1~i]=p[0,j-1](即j之前的部分必须与s相匹配)。
设 p 向右移动的距离为k,那么必须要满足对于任意的,都需要满足
。这说明什么?这说明 j-k+1 就是相同真前后缀的长度,
就是
的公共真前后缀。为什么一定要是最长公共前后缀呢?短一点不行吗?
古语有云:一寸长,一寸强因为向右移动的距离为k,而相同真前后缀的长度为j-k-1。要是移动距离过大,可能就越过了一个解。因此,移动距离要在贪心的前提下尽可能小,相应的,公共真前后缀的长度就应尽可能大。但是它不能等于自身的长度,否则就是在原地踏步,死循环了。
有了上面的推论,我们就很好推导了。当失配的字符分别为 s[i] 与 p[j] 时, j 左端的匹配部分的最长相同真前后缀的长度为。
。若仍然失配,仅需重复上述操作即可(思考一下为什么);若 j=0 时仍不匹配,说明解不可能在这部分中,直接跳过。
(下方图文注解)
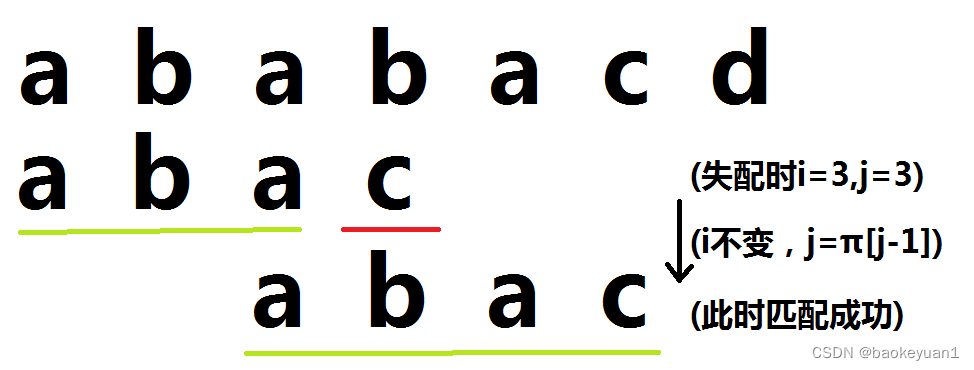
这是求匹配位置的代码。↓
const int N=1e6+5;
char s[N],p[N];
int pi[N];
int n,m;
inline int get_next(int i,int j){//返回当s[i]与p[j]失配后,j应该变为几
while(j&&s[i]!=p[j])
j=pi[j-1];
if(s[i]==p[j]) return j;//特判j==0&&s[i]!=p[j]的情况
else return -1;
}
vector<int> kmp(){//kmp算法匹配字符串
int i=0,j=0;
vector<int> ans;//记录答案
while(i<n){
if(s[i]==p[j]) j++,i++;//若匹配,直接找到下一位
else j=get_next(i,j);//否则往右移动p
if(j==m) ans.push_back(i-j),j=get_next(i,pi[j-1]);//若匹配成功,加入答案,并跳转
if(j==-1) i++,j++;//如果退无可退,则跳过这个i
}
return ans;//返回答案
}π数组
现在唯一的问题就是如何求π数组了。
如果暴力——
const int N=1e1+5;
char s[N],p[N];
int pi[N];
int n,m;
inline bool same(int i,int j,int siz){
while(siz--)
if(p[i++]!=p[j++]) return false;
return true;
}
void get_pi(){
pi[0]=0;
for(int i=1;i<m;i++){
for(int siz=i;siz+1;siz--){
if(same(0,i-siz+1,siz)){
pi[i]=siz;
break;
}
}
}
} 是的,暴力的时间复杂度甚至飙到了。这样的话优化就失去了意义。那我们怎么办呢?
使用DP的思想
使用DP的思想。如果我们已经知道了 0~j-1的所有数字的最长相同真前后缀的长度,想必会对求π[j]有所帮助(当然,这是猜测,还需要严谨地证明)。
(说明一点,π [i] 在以0为开头的字符串中,还能表示最长相同真前后缀后一位的下标,如p=abaa,π [2] = 1不但表示子串aba的最长相同真前后缀的长度为1,还表示 p [ π [2] ] 是最长相同真前后缀后面的第一位)
(可能有点绕,边看边理解就好)
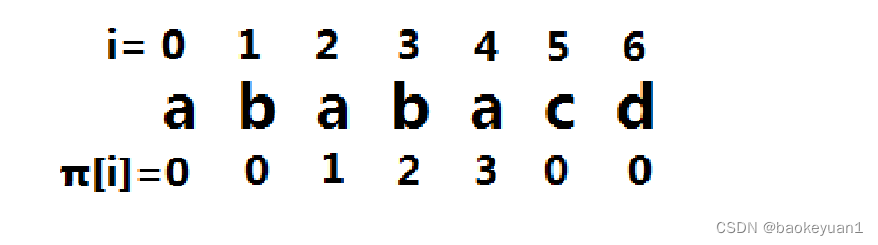
如图, 假设此时 i=5 。则下图中绿色框框选出的两部分是完全相同的。若有 ,那么
,可以轻松证明这是最优解。
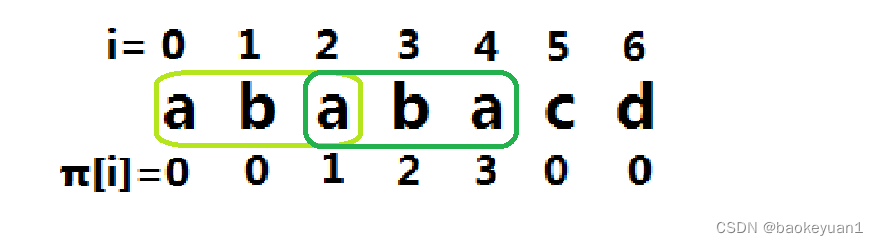
但是,样例显然不符合上面的情况。这时候该怎么办呢?
我们要明确一点:一定要往前找。因为大的我们都遍历过,都不符合情况。
往前找多少呢?既然是往前找 ,那么最后求得的子串必然是的前缀。对于其前缀,因为前后缀的是完全相同的,所以对于每一个前缀的子串,都必然有一个后缀与之对应完全相等。对于
,最大的可能的前缀又是什么呢?是的,就是
(如下图)是不是有那味儿了呢?
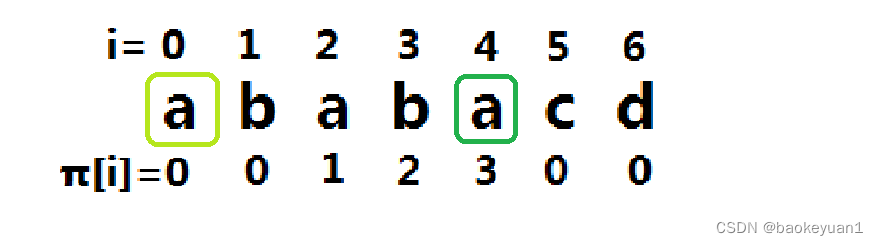
没错,这是一个循环,不断往前寻找尽可能大的长度。在寻找过程中,如满足条件,就直接赋值 π [i] = π [k] +1 。边界条件也很简单,就是当前缀长度为0且 p [i] ≠ p [0]。(如果有些难消化,可以多看几遍)
using namespace std;
const int N=1e6+5;
char s[N],p[N];
int pi[N];
int n,m;
void get_pi(){
pi[0]=0;
for(int i=1;i<m;i++){
int k=i;
while(k&&p[pi[k-1]]!=p[i])
k=pi[k-1];
if(k==0) pi[i]=0;
else pi[i]=pi[k-1]+1;
}
}将这几段代码合在一起,就成了了我们的最终代码了——
#include<iostream>
#include<stdio.h>
#include<cstring>
#include<vector>
using namespace std;
const int N=1e6+5;
char s[N],p[N];
int pi[N];
int n,m;
void get_pi(){
pi[0]=0;
for(int i=1,k;i<m;i++){
k=i;
while(k&&p[pi[k-1]]!=p[i])
k=pi[k-1];
if(k==0) pi[i]=0;
else pi[i]=pi[k-1]+1;
}
}
inline int get_next(int i,int j){
while(j&&s[i]!=p[j])
j=pi[j-1];
if(s[i]==p[j]) return j;
else return -1;
}
vector<int> kmp(){
int i=0,j=0;
vector<int> ans;
while(i<n){
if(s[i]==p[j]) j++,i++;
else j=get_next(i,j);
if(j==m) ans.push_back(i-j),j=get_next(i,pi[j-1]);
if(j==-1) i++,j++;
}
return ans;
}
signed main(){
scanf("%s\n%s",s,p);
n=strlen(s);
m=strlen(p);
get_pi();
vector<int> ans=kmp();
for(int i=0,siz=ans.size();i<siz;i++){
printf("%d\n",ans[i]+1);
}
for(int i=0;i<m;i++){
printf("%d ",pi[i]);
}
return 0;
}
/*
输出说明:
前有若干列,表示主串与模式串匹配的位置
后有一行,第i个数字表示 π[i]
*/事实上,还有一种更简单的写法
我们只需要将两个字符拼接在一起(模式串在前,主串在后),记为 all ,中间加一个在两个字符串中都没有出现的字符 起分割作用。则对于 all 的后半段(即主串),如有 π [i] = m (m为模式串长度),则表明在主串中有一段与模式串相同。这样也可以起到查找子串的作用。
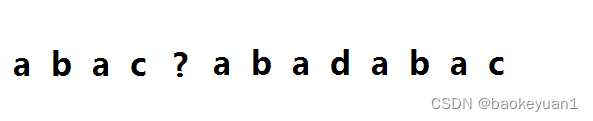
like this ↑
完结撒花!















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









